Heading to #BioITExpo to talk about AI enabled data pipelines and PKPD for pre clinical and early clinical development. Hit me up if you're in town https://t.co/gDJaatT3En
@alexiskold It is particularly impressive that the field of computer science (via Turing's paper) was born with the full awareness of it's own limitations (i.e., what is computable). Remarkable and I think unprecedented. (Scott Aaronson pointed this out, not me)
@stevenstrogatz Trump's innumeracy is legendary. Howard Stern once (long time ago) asked him on his show what is something like 12 times 13. And Trump said something like one thousand two hundred ....
@AlexKontorovich Dude, I totally watch and changed my teaching style after watching yours. Love the quantitative history of math, found good books that I probably wouldnt discover on my own, and so on. Keep at it pls!
A preview of my talk tomorrow at the Newton Insitute @NewtonInstitute (comments welcome)
My primary interest is research math: solving problems, proving theorems.
Before 2019, I was accustomed to using Mathematica to check tedious, error-prone algebra in my papers. Do it once, and never waste time checking it again.
But algebra was only part of the issue. If I had a lemma, and in a 60-page paper I might have 20 of them, with a dozen parameters all moving around in different ranges and needing to line up perfectly at the end, then even a single stray minus sign could kill the entire paper. The whole enterprise was extremely complex and fragile. (What I'm describing is very common in loads of fields in modern research math.)
In 2019, I watched a lecture of Kevin Buzzard's, and realized the answer: I should use an interactive theorem prover like Lean to check my lemmas the same way Mathematica checks my algebra. (Of course, as I've since learned, there are many benefits to working formally beyond correctness, and these have been extensively enumerated elsewhere, so I won't repeat them here.)
But my original motivation for getting involved in formalization was simple: I hoped it would speed up my workflow.
It did not.
In fact, formalization is brutally tedious, requiring painstakingly spelling out facts that to a human expert are blatantly obvious.
Fast forward to 2025, and AI was getting genuinely good at helping with formalization. I was already using Claude rather extensively when we crossed the finish line on the "Medium" PNT in July 2025. By September 2025, Math Inc's Gauss system autoformalized the Strong PNT, writing over 20K lines of compiling Lean autonomously. Earlier this month, they outdid themselves again, writing 200K lines autonomously and formalizing Viazovska's theorems on optimal sphere packing in dimensions 8 and 24.
So isn't that the dream? AI can now, in some instances, autoformalize very significant theorems. Can we mathematicians just get back to thinking, sketching, and letting AI do the formalization for us?
Not so fast.
Autoformalization only works because it is built on top of a big, comprehensive, efficient, coherent monorepo of high-quality formalized mathematics, namely Mathlib. And even in the PNT+ and Viazovska examples, the autoformalizations still depended on substantial earlier human work: setting up the right definitions, the right API, the right abstractions, and so on.
So maybe we now get a nice positive feedback loop:
Research
->
formal math (thanks to AI)
->
grows Mathlib
->
enables more research.
Still no.
AI formalization, and frankly the first-pass human formalization too, is usually local, ad hoc, single-purpose work. It is not necessarily general, abstract, efficient, or reusable. So it does not in and of itself help grow Mathlib. The second arrow is broken.
Actually, this is not some temporary annoyance, it is inevitable! The goals of doing research and building libraries are misaligned, like scrambling up a cliff versus building an elevator to the top. Both are trying to go up, but for completely different reasons and in completely different ways.
In fact, it is even worse than that: the second arrow may make the feedback loop negative.
Let us give that second arrow a name: "canonization".
By canonization, I mean the process of taking a local, one-off formalization and turning it into library mathematics: general, reusable, coherent, efficient, and compatible with the rest of the monorepo. This is an extremely difficult and time-consuming task. It requires a large amount of prior knowledge and skill, often in several quite different areas at once. And here's why the feedback loop may be negative: while a rough formalization can certainly be a technical head start, socially it often strands the problem in the worst possible state: too solved to feel pressing, too idiosyncratic to be reusable. If a formalization already exists in some ad hoc form, then people are much less incentivized to do this work! They get less credit for succeeding, there is less urgency, and less motivation.
Does this sound familiar? It's the same structural problem we had back in 2019, going from proved results to formalized results! So the answer should be obvious.
In June 2025, I claimed that (quasi)autoformalization, meaning not entirely autonomous but allowing human intervention and steering, was the greatest short-term challenge in realizing the dream of speeding up research [K2025]. The corresponding claim today is:
(Quasi)auto-canonization is the greatest short-term challenge for AI systems.
I personally know of only one AI company so far that seems to be taking this challenge seriously, namely Harmonic with its Aristotle agent. Imagine if we get this right. Definitions will still be difficult to automate, but there are orders of magnitude fewer definitions than theorems. Once those foundations are laid (which will still be a ton of human time and effort!), everything else can scale on top.
Right now, the vast majority of research mathematicians working in formalization are, very commendably, working toward growing Mathlib. But they comprise maybe 1% of all professional mathematicians. This is not necessarily because people do not want to work formally. It is because the current system does not match how most mathematicians want to work.
People are diverse. They have different strengths and weaknesses, different interests, different workflows. If we embrace an ecosystem where people are encouraged to formalize freely, with heavy AI assistance, and where the right pieces later get (quasi)auto-canonized into the central monorepo, then I think we could potentially be in position, given the right incentives, training, and culture-shifts, to move from a handful to the majority of mathematicians doing math formally.
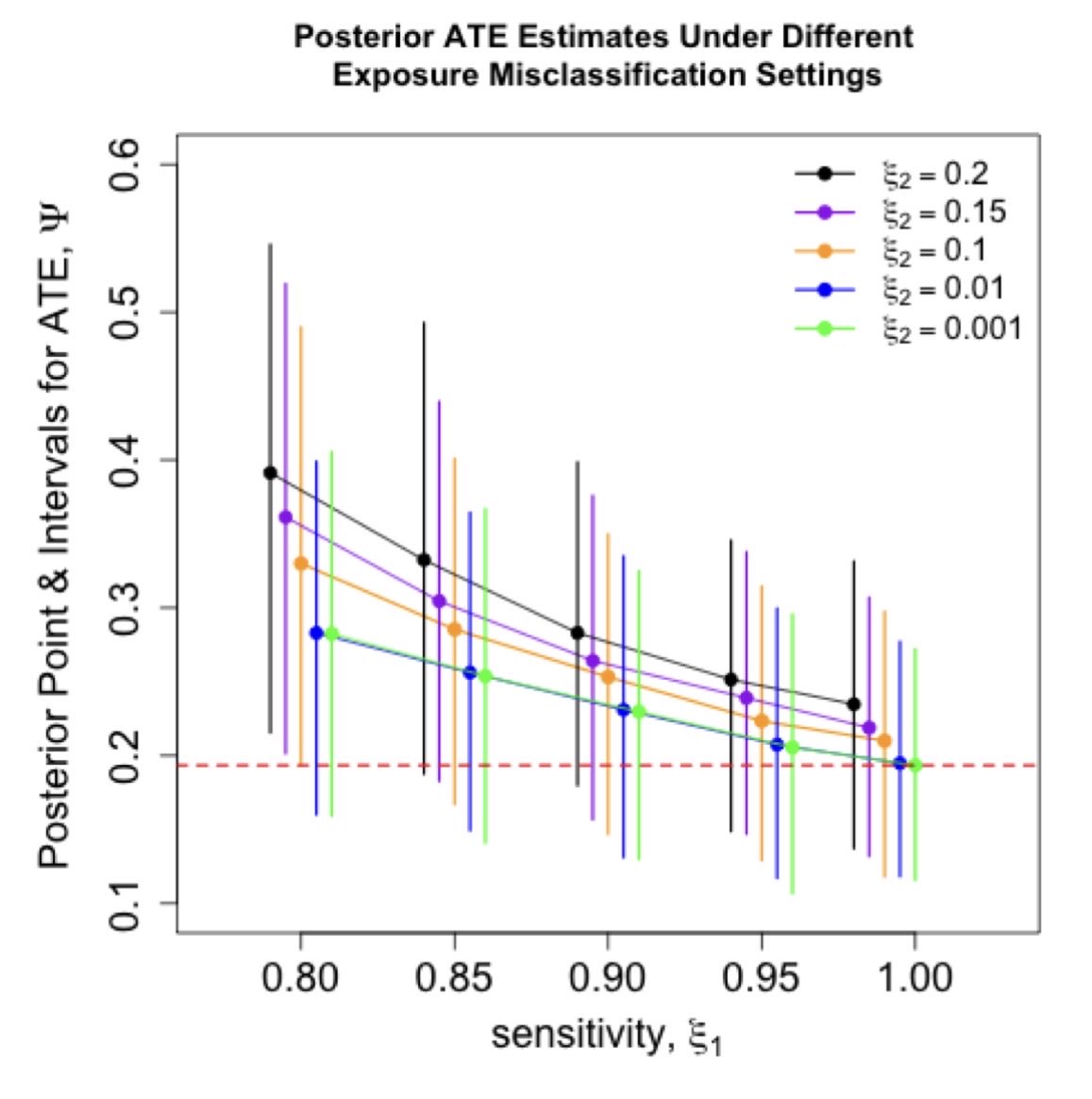
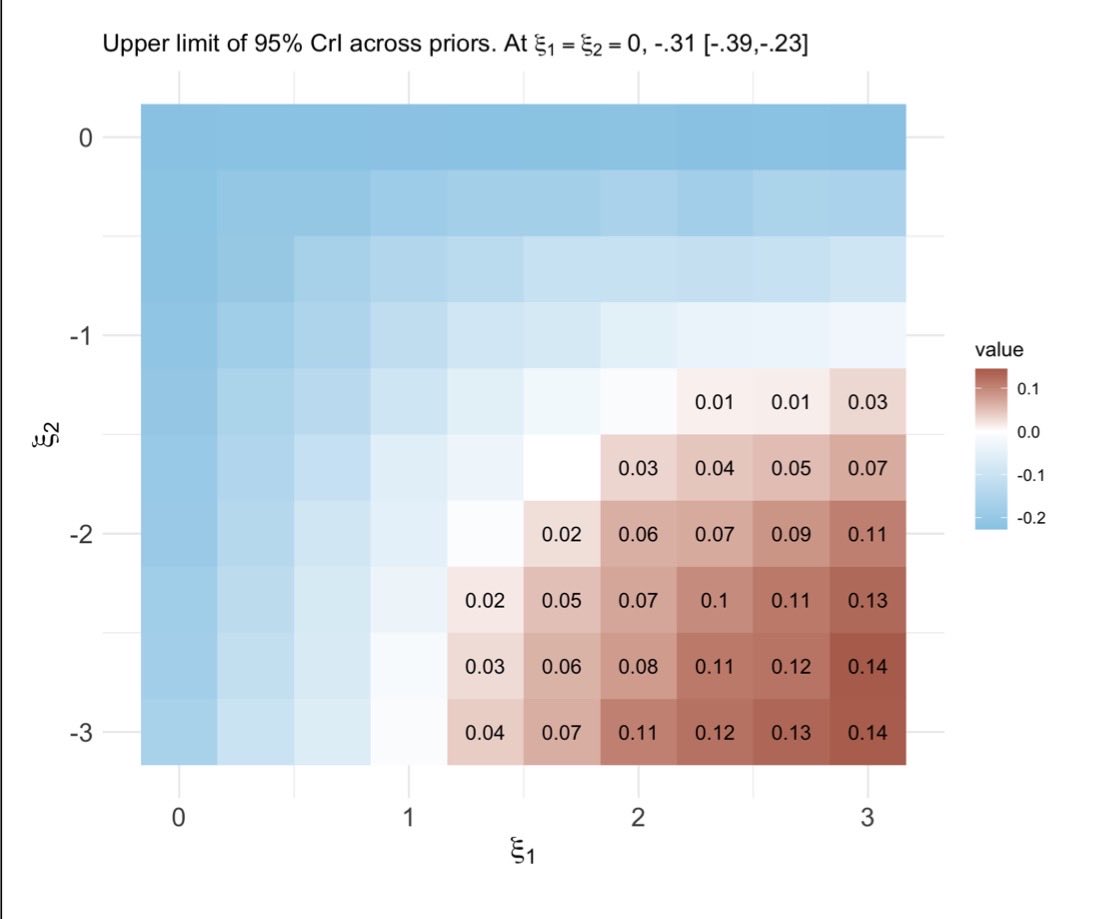
New paper up on arXiv.
“Stress-Testing Assumptions: A Guide to Bayesian Sensitivity Analyses in Causal Inference”
Examples include: exposure misclassification, unmeasured confounding, snd MNAR outcomes.
W/ @mcmc_stan code on GitHub.
https://t.co/8kRkjUrAvj
@ProbFact This used to be a fun homework assignment (ask students to decode a text encoded with a substitution cypher) before solutions popped up on the Internet and of course ChatGPT
Next Tuesday, 2nd December, in Copenhagen at @EurIPSConf UnConference @ELLISforEurope workshop - please stop by to say hi: both on the day, and the whole week.
Remarkable that Igor Savelyev credits Lenin with the definition of matter! Being a Soviet scientist was a tricky business -- even physics books needed to pass the censor.
I just got a copy The Princeton Companion to Mathematics edited by @wtgowers and opened it to this delicious nugget. Also, completely unexpected, Bayesian analysis is on page 159/1000!
@shiraamitchell One of the cool things about your posts on the gelblog is that that they have a certain look and feel, a signature, that's unmistakenly yours. I never have to squint at the author's name.
@EmanuelDerman@StephenKing Hm, yeah I guess it's an asymmetric device -- use it too much and it's annoying (to all I suspect); don't use it at all and it's hard to read but only to those who read a certain way. Language is nice that way with high variance in production and consumption.