Really excited to share something @carlottacaste and I been working on over the last couple of months. Here goes the first #rstats learning path on @MicrosoftLearn - Create Machine Learning models with R and Tidymodels:
We hope you enjoy the ride 🤗🥳!
https://t.co/f2oI2yjwFF
My thesis is LLMs significantly boost your motivation to work on something. Getting a shitty prototype fast is immensely motivating
Code and time are often not the bottleneck, motivation is the bottleneck.
New 3h31m video on YouTube:
"Deep Dive into LLMs like ChatGPT"
This is a general audience deep dive into the Large Language Model (LLM) AI technology that powers ChatGPT and related products. It is covers the full training stack of how the models are developed, along with mental models of how to think about their "psychology", and how to get the best use them in practical applications.
We cover all the major stages:
1. pretraining: data, tokenization, Transformer neural network I/O and internals, inference, GPT-2 training example, Llama 3.1 base inference examples
2. supervised finetuning: conversations data, "LLM Psychology": hallucinations, tool use, knowledge/working memory, knowledge of self, models need tokens to think, spelling, jagged intelligence
3. reinforcement learning: practice makes perfect, DeepSeek-R1, AlphaGo, RLHF.
I designed this video for the "general audience" track of my videos, which I believe are accessible to most people, even without technical background. It should give you an intuitive understanding of the full training pipeline of LLMs like ChatGPT, with many examples along the way, and maybe some ways of thinking around current capabilities, where we are, and what's coming.
(Also, I have one "Intro to LLMs" video already from ~year ago, but that is just a re-recording of a random talk, so I wanted to loop around and do a lot more comprehensive version of this topic. They can still be combined, as the talk goes a lot deeper into other topics, e.g. LLM OS and LLM Security)
Hope it's fun & useful!
https://t.co/75mXcUBI8L
Female Track Athlete of the Year nominee ✨
Repost to vote for Faith Kipyegon 🇰🇪 in the #AthleticsAwards.
Voting closes on Sunday 27 October at 11:59 PM CEST.
Fun convo w @karpathy🎙️
*Bottlenecks to AI LLM progress
*Robots, form factors, data
*Tesla (& Waymo) self driving
*AI & Education
*Eureka labs
Lots of great stuff!
The wait is finally over!!! 😁
We just dropped an in-depth tutorial on how to build your own robot!
Teach it new skills by showing it a few moves with just a laptop.
Then watch your homemade robot act autonomously 🤯
1/🧵👇
The same guy has now made university education 7× more expensive. The fees for Medicine and Surgery was 78k per year when he came in. It's now 540k per year -forcing students to take loans that they'll pay with interest yet there are no jobs. What an evil being!
RECEIPTS: Ethiopian Airlines called me a liar, so I tracked down the passenger in my viral video who was offloaded for a minister.
ET called police on Aisha and her husband, forced them to delete their videos & left them stranded in Addis for 24hrs. They’ve received no apology
⚡️ Excited to share that I am starting an AI+Education company called Eureka Labs.
The announcement:
---
We are Eureka Labs and we are building a new kind of school that is AI native.
How can we approach an ideal experience for learning something new? For example, in the case of physics one could imagine working through very high quality course materials together with Feynman, who is there to guide you every step of the way. Unfortunately, subject matter experts who are deeply passionate, great at teaching, infinitely patient and fluent in all of the world's languages are also very scarce and cannot personally tutor all 8 billion of us on demand.
However, with recent progress in generative AI, this learning experience feels tractable. The teacher still designs the course materials, but they are supported, leveraged and scaled with an AI Teaching Assistant who is optimized to help guide the students through them. This Teacher + AI symbiosis could run an entire curriculum of courses on a common platform. If we are successful, it will be easy for anyone to learn anything, expanding education in both reach (a large number of people learning something) and extent (any one person learning a large amount of subjects, beyond what may be possible today unassisted).
Our first product will be the world's obviously best AI course, LLM101n. This is an undergraduate-level class that guides the student through training their own AI, very similar to a smaller version of the AI Teaching Assistant itself. The course materials will be available online, but we also plan to run both digital and physical cohorts of people going through it together.
Today, we are heads down building LLM101n, but we look forward to a future where AI is a key technology for increasing human potential. What would you like to learn?
---
@EurekaLabsAI is the culmination of my passion in both AI and education over ~2 decades. My interest in education took me from YouTube tutorials on Rubik's cubes to starting CS231n at Stanford, to my more recent Zero-to-Hero AI series. While my work in AI took me from academic research at Stanford to real-world products at Tesla and AGI research at OpenAI. All of my work combining the two so far has only been part-time, as side quests to my "real job", so I am quite excited to dive in and build something great, professionally and full-time.
It's still early days but I wanted to announce the company so that I can build publicly instead of keeping a secret that isn't. Outbound links with a bit more info in the reply!
In 2019, OpenAI announced GPT-2 with this post:
https://t.co/jjP8IXmu8D
Today (~5 years later) you can train your own for ~$672, running on one 8XH100 GPU node for 24 hours. Our latest llm.c post gives the walkthrough in some detail:
https://t.co/XjLWE2P0Hp
Incredibly, the costs have come down dramatically over the last 5 years due to improvements in compute hardware (H100 GPUs), software (CUDA, cuBLAS, cuDNN, FlashAttention) and data quality (e.g. the FineWeb-Edu dataset). For this exercise, the algorithm was kept fixed and follows the GPT-2/3 papers.
Because llm.c is a direct implementation of GPT training in C/CUDA, the requirements are minimal - there is no need for conda environments, Python interpreters, pip installs, etc. You spin up a cloud GPU node (e.g. on Lambda), optionally install NVIDIA cuDNN, NCCL/MPI, download the .bin data shards, compile and run, and you're stepping in minutes. You then wait 24 hours and enjoy samples about English-speaking Unicorns in the Andes.
For me, this is a very nice checkpoint to get to because the entire llm.c project started with me thinking about reproducing GPT-2 for an educational video, getting stuck with some PyTorch things, then rage quitting to just write the whole thing from scratch in C/CUDA. That set me on a longer journey than I anticipated, but it was quite fun, I learned more CUDA, I made friends along the way, and llm.c is really nice now. It's ~5,000 lines of code, it compiles and steps very fast so there is very little waiting around, it has constant memory footprint, it trains in mixed precision, distributed across multi-node with NNCL, it is bitwise deterministic, and hovers around ~50% MFU. So it's quite cute.
llm.c couldn't have gotten here without a great group of devs who assembled from the internet, and helped get things to this point, especially ademeure, ngc92, @gordic_aleksa, and rosslwheeler. And thank you to @LambdaAPI for the GPU cycles support.
There's still a lot of work left to do. I'm still not 100% happy with the current runs - the evals should be better, the training should be more stable especially at larger model sizes for longer runs. There's a lot of interesting new directions too: fp8 (imminent!), inference, finetuning, multimodal (VQVAE etc.), more modern architectures (Llama/Gemma). The goal of llm.c remains to have a simple, minimal, clean training stack for a full-featured LLM agent, in direct C/CUDA, and companion educational materials to bring many people up to speed in this awesome field.
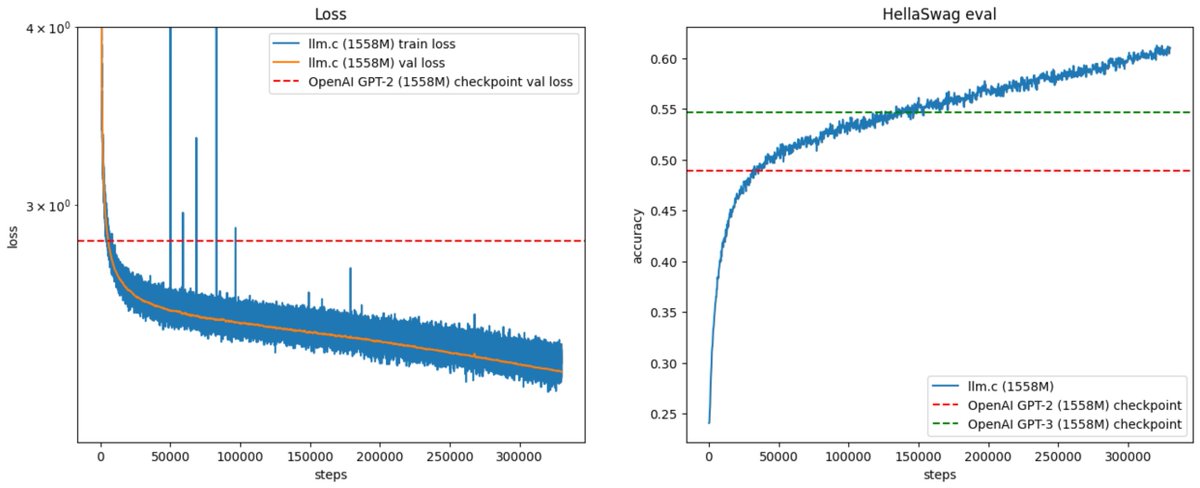
Eye candy: my much longer 400B token GPT-2 run (up from 33B tokens), which went great until 330B (reaching 61% HellaSwag, way above GPT-2 and GPT-3 of this size) and then exploded shortly after this plot, which I am looking into now :)
Lakini kama umepigiwa simu ukalipwa you’d rather stand down than let the lost lives go in vain na usiongee. That is worse than treason betraying your fellow comrades and fallen martyrs!
#RutoMustGo
"Why is Ruto killing us?"
"Why kill someone over glass that can be bought again?"
President Ruto failed to read the room. And his MPs passed the Finance Bill while Kenyans were literally outside Parliament asking them to reject it
Kenya is the country we've been born & bred in. Asking us to look for jobs elsewhere to indirectly ask us for money thru' remittances really beats the purpose of building Kenya. We want to build this country & all we demand is accountability.
#RejectFinanceBill2024#TotalShutdown