🚀 Exciting news! Our project, CROssBARv2, is now live as an online tool and its article (preprint)!
We've built a unified AI-powered platform that brings together the fragmented world of biomedical data — and lets you talk to it in plain English.
Here's the story 👇
The problem, in plain terms: Imagine being a detective, but your clues are scattered across 34 different filing cabinets, written in different languages, with no index. That's what biomedical researchers face every day — genes in one database, drugs in another, diseases somewhere else. Connecting the dots is slow & painful without serious programming skills.
CROssBARv2 is our answer to this. 🧬💊🔬
What did we build?
CROssBARv2 is a biomedical Knowledge Graph (KG) — think of it as a giant, intelligent map of biology. We integrated data from 34 well-established databases into a single, structured, and searchable system:
🔵 ~2.7 million nodes (proteins, genes, drugs, diseases, pathways, side effects, & more)
🔗 ~12.6 million edges (biomedical relationships)
🧠 14 node & 51 edge types
🏷️ Rich metadata
Now the exciting part 🤖 — meet CROssBAR-LLM
Large Language Models (LLMs) like ChatGPT or Gemini are brilliant at conversation — but they hallucinate. They confidently tell you things that sound right but aren't. In biomedicine, that's dangerous.
Our solution: ground the LLM in the knowledge graph.
CROssBAR-LLM lets you ask complex biomedical questions in plain English, like:
"What proteins are encoded by genes regulated by NFKB1, participate in the Endocytosis pathway, and are targeted by drugs used to treat diseases comorbid with osteoporosis?"
CROssBAR-LLM tutorial: https://t.co/gzHU9nBsiT
What happens under the hood:
🗣️ Your natural language question is translated into a formal DB query
⚡ The query runs on the CROssBARv2 KG in real time
📊 Structured, verified results are retrieved
💬 The LLM turns results into a clear, readable answer
No hallucinations. Every answer is traceable back to real data
How does it compare to just directly asking LLMs on a biomedical Q&A benchmark?
GPT/Claude/Gemini: ~50-65%
CROssBAR-LLM (w/ Gemini 1.5 Pro): 98% accuracy 🎯
CROssBAR-LLM (w/ GPT-4o): 97% accuracy 🎯
Everything is open and accessible 🔓
🌐 Web platform: https://t.co/Wh5LSS4Qam
📡 GraphQL API
🖥️ Neo4j Browser for visualisation
📂 Full data on Hugging Face & Google Drive
💻 All code on GitHub
No paywall. No programming required. Just ask your question!
Huge thanks to the team!
Bünyamin Şen, Erva Ulusoy @ervaulusy , Melih Darcan, Mert Ergun, Sebastian Lobentanzer, Ahmet S. Rifaioğlu @ahmet_rifaioglu , Dénes Türei, Julio Saez Rodriguez @JulioSaezRod , and me, in collaboration with Saez Lab @saezlab
spanning Hacettepe University @Hacettepe1967 , Heidelberg University @HeidelbergU , Helmholtz Munich @HelmholtzMunich , and European Bioinformatics Institute | EMBL-EBI @emblebi
📄 Read the preprint: https://t.co/zA2VHmdhS9
⚙️Try the tool: https://t.co/oNjMTl89Vk
***Please repost!***
#AI #LLM #ML #Bioinformatics #KnowledgeGraph #DrugDiscovery #Biomedicine #OpenScience
🚀 Our new book chapter is out in Protein Function Prediction: Methods and Protocols:
“A Benchmarking Platform for Assessing Protein Language Models on Function-Related Prediction Tasks”
https://t.co/giBK9M4AKw
w/ @elif_cevrim@mgyigit@ervaulusy & Ardan Yılmaz
++
Hacettepe Biological Data Science Lab is on site at #ISMBECCB2025 (20–24 July, ACC Liverpool)—the flagship bioinformatics forum uniting ISMB & ECCB. The atmosphere is truly inspiring and dynamic. 🔬✨ #bioinformatics
++
Erva Ulusoy @ervaulusy is on stage presenting ProtHGT—heterogeneous graph transformers + protein LMs for protein‑function prediction with biological knowledge graphs— on the #Function stage at #ISMBECCB2025
Excited to share our new article 🚨
“Protein Language Models for Predicting Drug–Target Interactions: Novel Approaches, Emerging Methods & Future Directions”
with @atabeyunlu@ervaulusy@mgyigit & Melih Darcan is published in COSTBI
Free access link: https://t.co/kIwlojWAq9
New article 📢
Our study entitled: "Mutual annotation-based prediction of protein domain functions with Domain2GO"
with @ervaulusy is now published in the Protein Science journal
https://t.co/IbAxGJS26U
🧬🤟🎊
#ProteinScience@ProteinSociety
https://t.co/HuxYCJP1f8
++
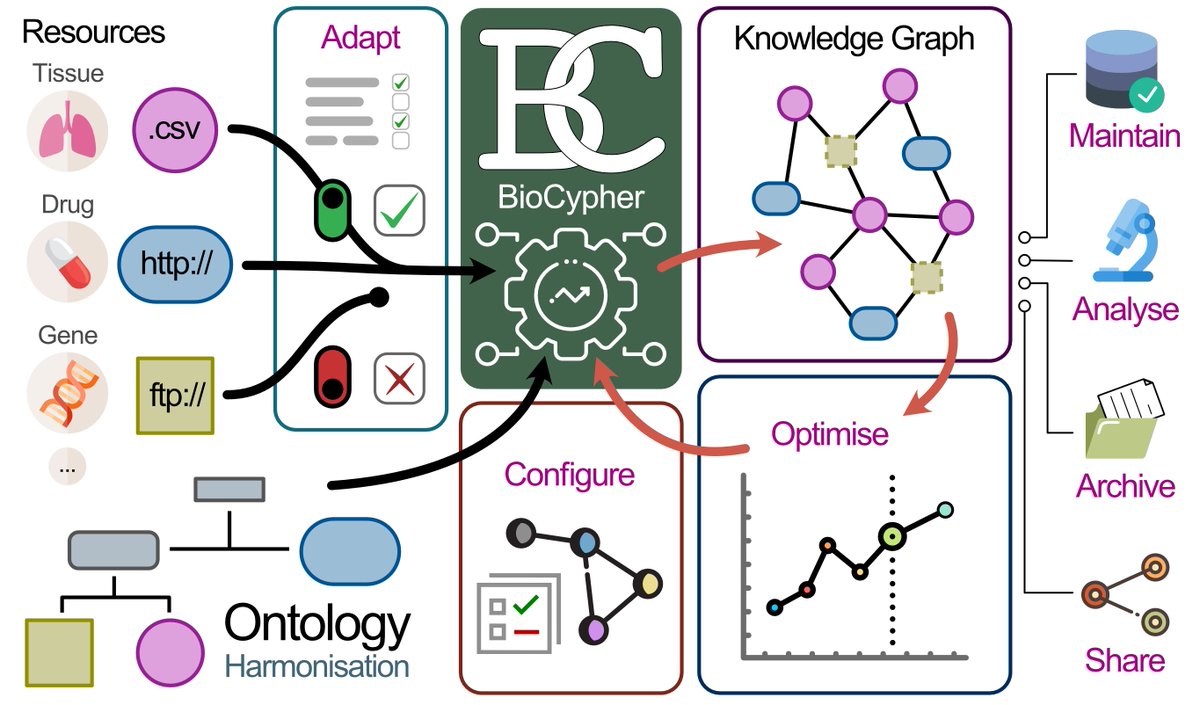
New paper alert 🚨
I'm happy to announce that our collaborative project led by @slobentanzer & @JulioSaezRod@saezlab on developing an #opensource framework called "BioCypher" for easy creation & manipulation of biological knowledge graphs has been published @NatureBiotech 🥳
Aynı haftada grubumuzdan bir güzel haber daha 🚨
Erva "Heterojen Biyomedikal Verinin Bilgi Çizgeleri ve Derin Öğrenme Tabanlı Analizi ile Protein Fonksiyonlarının Otomatik Tahmini" başlıklı yüksek lisans (YL) tezini başarı ile savundu
Tebrikler @ervaulusy 👏🥳🤟
Beklenen ++
Good news from our lab 🚨
All of our submissions got accepted (4 oral, 3 posters) at the flagship bioinformatics conference, ISMB/ECCB2023 https://t.co/Zag9nv81FE
Congrats to all, starting from presenters: @ervaulusy@atabeyunlu@serbulentunsal Burakcan, Elif & @heval_atas
1/6
New paper 🚨🤟🥳🎸
"SELFormer: Molecular Representation Learning via SELFIES Language Models" is out as a pre-print
https://t.co/iniTw4n41R
Started as an undergraduate course project and evolved into a new chemical language model!
#DeepLearning#DrugDiscovery#ML#AI
1/8
Building a knowledge graph for biomedical tasks usually takes months or years. 😰 What if you could do it in weeks or days? 🏃 We created BioCypher (https://t.co/9eGe9RDkNj) to make it easier than ever, but still flexible and transparent. 🧵⬇️
Two days full of exciting science #HIBIT2022 Turkish bioinformatics community rocks 🤟🏼
Thanks to organizers @yaydinson Dr Arzu Karahan @BurcakOtlu also @RSGTurkey & all students who worked tirelessly
Love from Hacettepe Biological Data Science Lab, hope to see you all next year