Much has been said about many companies’ desire for more compute (as well as data) to train larger foundation models. I think it’s under-appreciated that we have nowhere near enough compute available for inference on foundation models as well.
Years ago, when I was leading teams at Google, Baidu, and Stanford that focused on scaling up deep learning algorithms, many semiconductor manufacturers, data center operators, and academic researchers asked me whether I felt that AI technology would continue to make good use of more compute if they kept on delivering it. For many normal desktop processing workloads, like running a web browser or a text editor, having a faster CPU doesn’t help that much beyond a certain point. So do we really need faster and faster AI processors to train larger and larger models? Each time, I confidently replied “yes!” and encouraged them to keep scaling up compute. (Sometimes, I added half-jokingly that I had never met a machine learning engineer who felt like they had enough compute. 😀)
Fortunately, this prediction has been right so far. However, beyond training, I believe we are also far from exhausting the benefits of faster and higher volumes of inference.
Today, a lot of LLM output is primarily for human consumption. A human might read around 250 words per minute, which is around 6 tokens per second (250 words/min / (0.75 words/token) / (60 secs/min)). So it might initially seem like there’s little value to generating tokens much faster than this.
But in an agentic workflow, an LLM might be prompted repeatedly to reflect on and improve its output, use tools, plan and execute sequences of steps, or implement multiple agents that collaborate with each other. In such settings, we might easily generate hundreds of thousands of tokens or more before showing any output to a user. This makes fast token generation very desirable and makes slower generation a bottleneck to taking better advantage of existing foundation models.
That’s why I’m excited about the work of companies like @GroqInc, which can generate hundreds of tokens per second. Recently, @SambaNovaAI also published an impressive demo that hit hundreds of tokens per second.
Incidentally, faster, cheaper token generation will also help make running evaluations (evals), a step that can be slow and expensive today since it typically involves iterating over many examples, more palatable. Having better evals will help many developers with the process of tuning models to improve their performance.
Fortunately, it appears that both training and inference are rapidly becoming cheaper. I recently spoke with @CathieDWood and @CCRobertsARK of the investment firm ARK, which is famous for its bullish predictions on tech. They estimate that AI training costs are falling at 75% a year. If they are right, a foundation model that costs $100M to train this year might cost only $25M to train next year. Further, they report that for “enterprise scale use cases, inference costs seem to be falling at an annual rate of ~86%, even faster than training costs.”
I don’t know how accurate these specific predictions will turn out to be, but with improvements in both semiconductors and algorithms, I do see training and inference costs falling rapidly. This will be good for application builders and help AI agentic workflows lift off.
[Original text: https://t.co/BaH6bqZDds ]
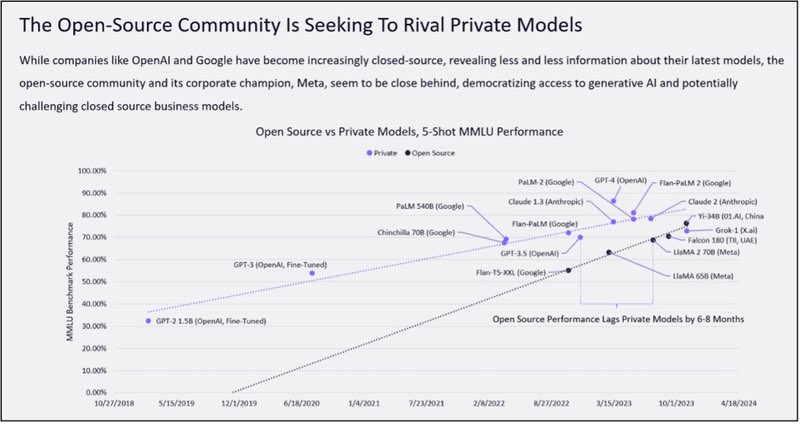
This is perhaps one of the most important charts on AI for 2024.
It was built by the amazing researcher team at @CathieDWood’s @ARKInvest.
We can see the rise of open source local models are on the path to overtake massive (and expensive) cloud based closed models.
Also: a model with more parameters is not necessarily better. It's generally more expensive to run and requires more RAM than a single GPU card can have.
GPT-4 is rumored to be a "mixture of experts", i.e. a neural net consisting of multiple specialized modules, only one of which is run on any particular prompt. So the effective number of parameters used at any one time is smaller than the total number.
Dear journalists, it makes absolutely no sense to write:
"PaLM 2 is trained on about 340 billion parameters. By comparison, GPT-4 is rumored to be trained on a massive dataset of 1.8 trillion parameters."
It would make more sense to write:
"PaLM 2 possesses about 340 billion parameters and is trained on a dataset of 2 billion tokens (or words). By comparison, GPT-4 is rumored to possess a massive 1.8 trillion parameters trained on untold trillions of tokens."
Parameters are coefficients inside the model that are adjusted by the training procedure. The dataset is what you train the model on. Language models are trained with tokens that are subword units (e.g. prefix, root, suffix).
Saying "trained a dataset of X billion parameters" reveals that you have absolutely no understanding of what you're talking about.
An inflation update: in the past I've focused on a measure that excludes lagging shelter and used cars as well as food and energy. Just to note that it adds to the evidence that inflation has been largely defeated
Voici une annonce qui m'intéresse
https://t.co/MwUxDCtCV3
Je suis vraiment curieux et enthousiaste de pouvoir rendre consommable à mes clients LLAMA-2. Je suis admiratif du travail de Meta sur l'IA et plus spécifiquement sur LLAMA-2
This is huge: Llama-v2 is open source, with a license that authorizes commercial use!
This is going to change the landscape of the LLM market.
Llama-v2 is available on Microsoft Azure and will be available on AWS, Hugging Face and other providers
Pretrained and fine-tuned models are available with 7B, 13B and 70B parameters.
Llama-2 website: https://t.co/PKrrXgHdem
Llama-2 paper: https://t.co/aINNrXNhMb
A number of personalities from industry and academia have endorsed our open source approach: https://t.co/N7HwgW9Suh
Voici un article intéressant sur les banques américaines. Il clarifie les spécifictés lié aux nombres de banques régionales (plus de 4K).
Ces spécificités vont probablement impacter la finance mondiale, avec un flux de nouvelles p…https://t.co/EM5sq7u8Lt https://t.co/SbNhi9GAgw
Le risque d'une IA dans un domaine réglementé, comme la banque est bien expliqué ici selon moi .
Si l'explicabilité est nécessaire pour l'obtention d'un prêt, je suis persuadé que ce type de décision ne pourra s'obtenir que par des…https://t.co/CFNwCO0cYZ https://t.co/ALSU0ZCAHB
Vaccines are not Rocket Science. They are a proven biological method to improve immunity against bacterial and viral infections that otherwise killed millions. Why are people suddenly against them?
This will change the practice of testing for the mainframe ; developers will be able to test their changes on an ephemerous workspace, set-up for the test and destroyed afterward. https://t.co/aORQcmQylm
Super-human AI is nowhere near the top of the list of existential risks.
In large part because it doesn't exist yet.
Until we have a basic design for even dog-level AI (let alone human level), discussing how to make it safe is premature.
Je suis persuadé que les ingénieurs utilisant l'IA remplaceront ceux qui ne le feront pas. Je pense que le besoin et le nombre d'ingénieurs augmentera...
This must be said and repeated.
Yes, Geoff was totally wrong to predict a drop in radiologist positions.
We knew that it was wrong when he said it.
We have data now.
This is exactly how I view the Generative AI stack starting with infrastructure, cloud, models, tools, applications, and services. https://t.co/aD0zrFK0pM