📊 ¿Conoces R Graph Gallery?
A primera vista parece una colección de gráficos. Más de 400 ejemplos, organizados por tipo, todos con código reproducible. Pero en realidad es un mapa de decisiones.
https://t.co/bIPhviibG0
#stats#DataScience#DataVisualization#RStats#python
"PaperOrchestra: A Multi-Agent Framework for Automated AI Research Paper Writing"
This paper builds a multi-agent system for AI research writing.
Each part of it handles one job: one plans, one does literature search, one makes figures, one writes, and one revises.
This treats paper writing like orchestration, not autocomplete.
They also introduce a benchmark built from 200 top AI papers, and show large gains over prior automated baselines, especially on literature review quality.
Google descubrió un truco muy estúpido para que la inteligencia artificial te responda MUCHO mejor. Mientras todo el mundo busca el prompt perfecto, escribe instrucciones complejas y técnicas con nombres elegantes... unos investigadores de Google descubrieron que lo que mejor funciona es copiar y pegar tu pregunta dos veces.
¡Sí, así de simple! Le mandás el mismo texto dos veces seguidas y la IA responde mejor.
Probaron con Gemini, ChatGPT, Claude y DeepSeek: en matemáticas, razonamiento y comprensión lectora mejoró en todo. En un caso, un modelo pasó de 21% de precisión a 97%.
¿Y por qué carajo funciona esto? Porque la IA lee tu mensaje una sola vez, de izquierda a derecha, sin poder volver atrás. Si tu pregunta está al final, todo el contexto de antes se procesó sin saber qué le ibas a preguntar. Es como leer un capítulo entero de un libro y recién al final alguien te dice: "ah, buscá cuántas veces aparece la palabra perro". Ya es tarde. Pero si lo leés dos veces, la segunda vez ya sabés qué buscar.
Mientras vos buscabas el prompt perfecto, la respuesta era Ctrl+C, Ctrl+V. A veces la solución más bruta es la más inteligente.
Terence Tao explains the math behind today’s LLMs is actually simple. Training and running them mostly uses linear algebra, matrix multiplication, and a bit of calculus, material an undergraduate can handle. We understand how to build and operate these models.
The real mystery is why they work so well on some tasks and fail on others, and why we cannot predict that in advance. We lack good rules for forecasting performance across tasks, so progress is largely empirical.
A key reason is the nature of real-world data. Pure noise is well understood, perfectly structured data is well understood, but natural text sits in between, partly structured and partly random. Mathematics for that middle regime is thin, similar to how physics struggles at meso-scales between atoms and continua.
Because of this gap, we can describe the mechanisms but cannot yet explain capability jumps or give reliable task-level predictions. That mismatch, simple machinery versus hard-to-predict behavior, is the core puzzle.
----
Video from 'Dr Brian Keating' YT Channel (Link in comment)
Amistades de la internet, si necesitan efectos de sonido para sus proyectos audiovisuales les sugiero echar mano del archivo de sonidos de la BBC. Hay miles de opciones y son de licencia libre.
https://t.co/2TANQfmLE9
Los puntos clave para un DESCANSO reparador 😴💤
Un estudio "preprint" recién subido a MedRXvid con 4,800 noches de datos revela que lo que comes HOY afecta tu sueño de ESTA MISMA NOCHE: @UOdivulga
👇
1️⃣ ¡Más fibra! 🥗 Comer más fibra aumenta el sueño profundo y el sueño REM (el más restaurador), reduciendo el sueño ligero.
2️⃣ Diversidad vegetal 🌿 Más plantas en tu dieta = menor frecuencia cardíaca durante la noche. Tu corazón descansa mejor.
3️⃣ Cenas pesadas 🍕 Pueden hacer que duermas unos minutos más, pero elevan tus pulsaciones nocturnas. No es un sueño de calidad.
4️⃣ Dato curioso 🤔 La proporción de grasas o carbohidratos del día no importó tanto como la fibra y el horario de las comidas.
El PrePrint: 👇
Day-to-day dietary variation shapes overnight sleep physiology: a target-trial emulation in 4.8 thousand person-nights | medRxiv
QUIEN APRENDA A APRENDER CON IA VA A DOMINAR LOS PRÓXIMOS 10 AÑOS.
Este prompt convierte a la IA en tu entrenador personal de aprendizaje.
Podrás dominar cualquier tema más rápido, con foco y totalmente personalizado.
Guárdalo.
👇
Eres un tutor EXPERTO, diseñador curricular y coach.
Quiero dominar completamente el tema [TEMA].
Sigue este proceso SIEMPRE:
1️⃣ Aclaración
Reformula el tema en 1–2 frases.
Enumera 3–5 subhabilidades clave.
Pregúntame mi nivel (principiante/intermedio/avanzado) y tiempo disponible.
Si no está claro, propone dos versiones.
2️⃣ Hoja de ruta
Después de mi confirmación, crea una ruta en 3–6 etapas:
Fundamentos → Conceptos básicos → Aplicaciones → Dominio → Enseñanza
Para cada etapa incluye:
• Objetivo claro
• Habilidades clave
• Acciones prácticas
• Esfuerzo estimado
3️⃣ Enseña en micro-pasos
Empieza por la Etapa 1.
Explica en partes pequeñas usando analogías simples.
Después de cada parte:
• Haz 2–4 preguntas rápidas
• Si fallo, explica de otra manera
4️⃣ Práctica activa
Genera ejercicios variados:
• Recordar
• Explicar como si tuviera 12 años
• Aplicaciones reales
• Crear algo propio
Incluye un desafío ligeramente superior a mi nivel.
5️⃣ Retroalimentación
Evalúa mis respuestas.
Detecta errores.
Dime exactamente qué debo reforzar.
6️⃣ Recursos
Sugiere 3–5 recursos de alta calidad adaptados a mi nivel.
7️⃣ Dificultad progresiva
Aumenta la complejidad gradualmente e integra lo aprendido.
El primer mensaje debe:
• Resumir el tema
• Proponer subhabilidades
• Preguntar nivel y tiempo
• Esperar mi decisión
Mantén todo claro, conciso y orientado a resultados.
Domina la IA.
Domina el futuro.
La IA no te reemplazará.
Pero quien use IA, sí.
No necesitas más información.
Necesitas mejor sistema.
Este prompt es el sistema.
Guárdalo.
Úsalo.
Evoluciona.
🚨 Google acaba de cargarse la industria de la extracción de documentos.
Ha lanzado LangExtract, una librería que convierte texto desordenado en datos estructurados y verificables, incluso en documentos enormes.
Es gratis y open-source 👇
El inicio del fin de los montacargas?
Estas son las Unidades Filics de una startup alemana de robótica. Robots móviles autónomos que se deslizan bajo palés, levantan cargas de hasta una tonelada y se mueven omnidireccionalmente con luces de navegación.
La @UNESCO_es ha publicado el informe AI and the Future of Education. Disruptions, dilemmas and directions (2025).
No es un texto para leer en diagonal ni una lista de recomendaciones rápidas. Es más bien una advertencia tranquila. La IA no entra en educación solo como un conjunto de nuevas herramientas, sino como un amplificador de tensiones que ya estaban ahí y que ahora se vuelven imposibles de seguir ignorando.
El informe insiste en algo que llevo tiempo observando en centros y universidades. El problema no es tanto la velocidad tecnológica como la asimetría entre innovación técnica y capacidad pedagógica para absorberla.
La IA avanza más rápido que nuestra manera de pensar el aprendizaje, la evaluación y la responsabilidad educativa.
Hay varias ideas que merece la pena subrayar.
- La primera es que no basta con formar en el uso de la IA. Si no se rediseñan tareas, criterios y evidencias de aprendizaje, la formación se queda en la superficie y acaba siendo cosmética.
- La segunda es que la equidad no se resuelve simplemente dando acceso a herramientas. Se juega en las condiciones reales de aprendizaje y, sobre todo, en que el criterio pedagógico no se delegue, aunque técnicamente sea posible hacerlo.
- La tercera es quizá la más incómoda. Si no repensamos qué evaluamos y por qué, la IA no va a “romper” la educación, pero sí puede vaciar de sentido muchas prácticas que ya estaban agotadas antes de su llegada.
La UNESCO no propone prohibiciones ni soluciones mágicas. Plantea dilemas. Gobernanza, ética, agencia humana, rol del profesorado, sentido del aprendizaje en contextos cada vez más automatizados. Y ahí está, para mí, el verdadero valor del informe. Obliga a parar y a pensar antes de reaccionar.
Leyéndolo, es difícil no ver la necesidad de marcos que ayuden a tomar decisiones con calma y criterio en los centros. No para decidir por nosotros, sino para ordenar el análisis antes de actuar. En ese plano encaja el SEIA, como una forma de trasladar a contextos reales muchas de las preguntas que el informe plantea a escala global: qué diseñamos, qué evaluamos, qué responsabilidad asumimos y qué decidimos no delegar.
El futuro de la educación con IA no se juega en la herramienta, sino en el diseño. En cómo distribuimos la responsabilidad. En qué seguimos exigiendo al estudiante. Y en qué decidimos no delegar, aunque sea técnicamente posible.
Si quieres acceder al informe completo, escríbeme “UNESCO” en los comentarios y te paso el enlace de acceso.
Leerlo no resuelve el problema. Pero ayuda a formular mejor las preguntas. Y ahora mismo, en educación, eso ya es mucho.
#edtech #UNESCO #IA #AI
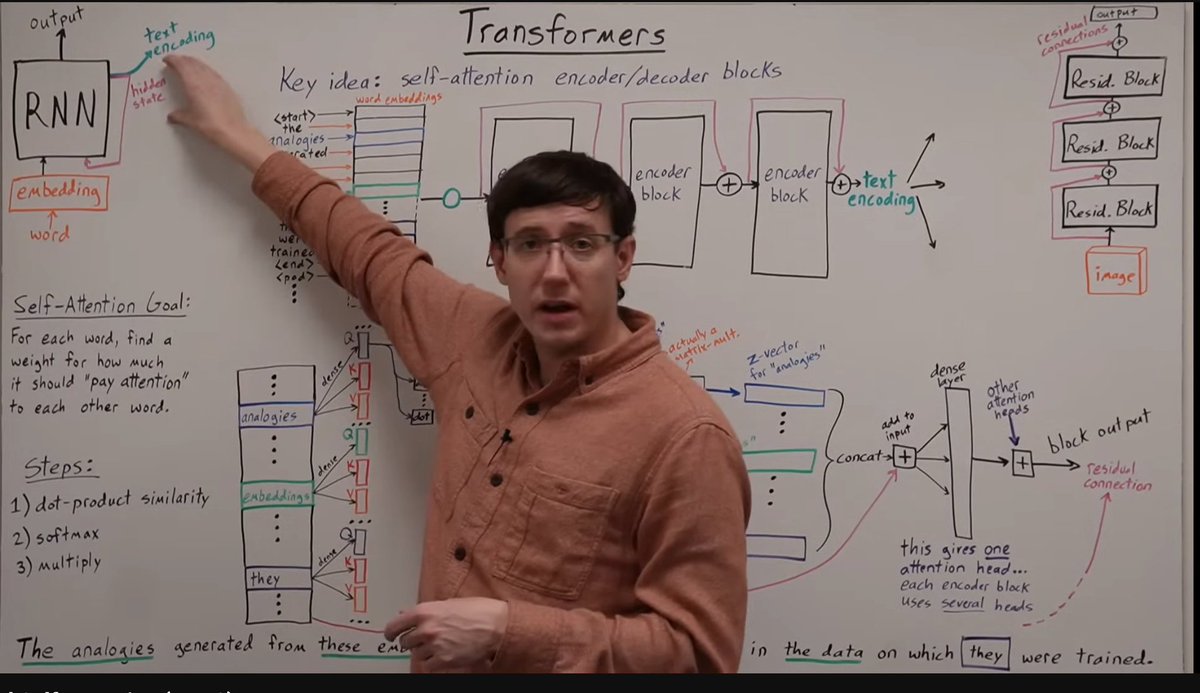
Hands down, this is the clearest and most effective explanation of Transformers on YouTube. The lecture was delivered by Professor Bryce as part of Davidson’s CSC 381: Deep Learning (Fall 2022).
If your goal is to truly understand Transformers and self-attention, this is the only video you need and there’s no reason to watch anything else.
En la universidad seguimos discutiendo sobre el uso de la IA, cuando el problema está en qué y cómo estamos evaluando.
He leído con calma un artículo de Oscar Martínez Rivera que recoge una experiencia muy concreta sobre el uso de IA en trabajos universitarios. Y me interesa especialmente porque no teoriza en abstracto, sino que analiza qué ocurre cuando la IA entra en una actividad real, con datos, resultados y límites claros.
La propuesta es sencilla y, pedagógicamente, muy bien pensada. Se pide al alumnado que use ChatGPT para generar una primera respuesta, que esa respuesta se haga visible en un anexo y que, a partir de ahí, el trabajo se reconstruya teniendo en cuenta lecturas obligatorias, debates de clase y materiales específicos de la asignatura. No se juega a detectar trampas, se obliga a mostrar el proceso.
Desde el marco del SEIA, este tipo de actividad se sitúa claramente en un nivel 2, donde la IA puede apoyar o coproducir, pero la responsabilidad cognitiva sigue siendo del estudiante. Lo que se evalúa no es el texto “bien escrito”, sino el criterio para revisar, contrastar y sostener una respuesta con contexto académico real.
Los datos del estudio son reveladores. Una parte importante del alumnado ya utilizaba IA antes de la actividad y, además, con fines académicos. Es decir, la usan aunque no los preparemos para ello. En ese escenario, la opción no es ignorarlo, sino diseñar mejor.
Hay además un resultado incómodo. Cuando la estructura del razonamiento la marcaba la IA, el trabajo tendía a suspender. No por deshonestidad, sino porque no alcanzaba el nivel de precisión y anclaje en lecturas que exigía el enunciado. La IA servía para pulir o estructurar, pero no para sustituir el pensamiento.
El propio alumnado percibía entonces que la herramienta daba respuestas generales, pero no los matices necesarios. Ese punto conviene leerlo con perspectiva. Con modelos más avanzados y una ingeniería de contexto bien aplicada, hoy la IA sí puede responder con bastante precisión a preguntas concretas. Y eso refuerza una conclusión clave. No podemos confiar en las limitaciones técnicas de la herramienta como filtro evaluativo. El filtro tiene que estar en el diseño de evidencias.
Lo valioso de esta experiencia es que no propone prohibir ni vigilar más. Propone asumir que la IA ya está ahí y rediseñar tareas para que, si el estudiante no comprende, ni siquiera la IA pueda salvarle. Y eso devuelve sentido a la evaluación universitaria.
Si te interesa profundizar en el marco del SEIA, comenta SEIA y te paso el acceso. Si quieres leer el artículo completo, comenta ARTÍCULO y te lo comparto.
Gracias por leerme 🙌
#SEIA #IA #AI #edtech
If you want to learn AI the right way, start here.
No shortcuts. No hype. No fluff.
Top 10 Stanford's Courses on AI & ML.
CS221: Artificial Intelligence
CS229: Machine Learning
CS229M: Machine Learning Theory
CS230: Deep Learning
CS234: Reinforcement Learning
CS224N: Natural Language Processing
CS231N: Deep Learning for Computer Vision
CME295: Large Language Models (LLMs)
CS236: Deep Generative Models
CS336: Language Modeling from Scratch
Did you know you can calculate the exact sample size you need before you even start your study? A sample size calculation — also called a power analysis — helps you determine the optimal number of observations for your statistical analysis. It ensures your study is large enough to detect meaningful effects, but not so large that you waste resources.
Key advantages of performing a power analysis:
✔️ Avoid underpowered studies that might miss real effects
✔️ Save time and costs by avoiding unnecessarily large samples
✔️ Tailor your sample size to the effect size you care about detecting
✔️ Choose your desired confidence level and statistical power for robust results
✔️ Works for a wide range of statistical tests, from t‑tests to ANOVA and regression
✔️ Supported by many free R packages, such as pwr
The image shows on the left side how the required sample size changes depending on the expected effect size — smaller effects require much larger samples. On the right side, you see an example of a calculated sample size for comparing two groups using a t-test, showing exactly how many participants are needed per group for the desired confidence level and statistical power.
Sign up for my newsletter to get more practical tips on statistics, data science, R, and Python. Check out this link for more details: https://t.co/X93SeCe0rb
#pythonprogramming #programmer #DataAnalytics #RStats #Python #datastructure #DataAnalytics



























![PabloRioX's tweet photo. QUIEN APRENDA A APRENDER CON IA VA A DOMINAR LOS PRÓXIMOS 10 AÑOS.
Este prompt convierte a la IA en tu entrenador personal de aprendizaje.
Podrás dominar cualquier tema más rápido, con foco y totalmente personalizado.
Guárdalo.
👇
Eres un tutor EXPERTO, diseñador curricular y coach.
Quiero dominar completamente el tema [TEMA].
Sigue este proceso SIEMPRE:
1️⃣ Aclaración
Reformula el tema en 1–2 frases.
Enumera 3–5 subhabilidades clave.
Pregúntame mi nivel (principiante/intermedio/avanzado) y tiempo disponible.
Si no está claro, propone dos versiones.
2️⃣ Hoja de ruta
Después de mi confirmación, crea una ruta en 3–6 etapas:
Fundamentos → Conceptos básicos → Aplicaciones → Dominio → Enseñanza
Para cada etapa incluye:
• Objetivo claro
• Habilidades clave
• Acciones prácticas
• Esfuerzo estimado
3️⃣ Enseña en micro-pasos
Empieza por la Etapa 1.
Explica en partes pequeñas usando analogías simples.
Después de cada parte:
• Haz 2–4 preguntas rápidas
• Si fallo, explica de otra manera
4️⃣ Práctica activa
Genera ejercicios variados:
• Recordar
• Explicar como si tuviera 12 años
• Aplicaciones reales
• Crear algo propio
Incluye un desafío ligeramente superior a mi nivel.
5️⃣ Retroalimentación
Evalúa mis respuestas.
Detecta errores.
Dime exactamente qué debo reforzar.
6️⃣ Recursos
Sugiere 3–5 recursos de alta calidad adaptados a mi nivel.
7️⃣ Dificultad progresiva
Aumenta la complejidad gradualmente e integra lo aprendido.
El primer mensaje debe:
• Resumir el tema
• Proponer subhabilidades
• Preguntar nivel y tiempo
• Esperar mi decisión
Mantén todo claro, conciso y orientado a resultados.
Domina la IA.
Domina el futuro.
La IA no te reemplazará.
Pero quien use IA, sí.
No necesitas más información.
Necesitas mejor sistema.
Este prompt es el sistema.
Guárdalo.
Úsalo.
Evoluciona.](https://pbs.twimg.com/media/HBDiEm4WkAAOJpv.jpg)