Introducing TabFM, a foundation model designed specifically for tabular data classification & regression. This approach allows generation of high-quality predictions on previously unseen tables in a single forward pass.
Learn more and try out the model →https://t.co/OTbVQ8oUQs
Karpathy's Agentic Engineering finally has proper tooling!
(built by Google)
Karpathy defined agentic engineering as the discipline that separates production agent work from vibe coding. The core skills he listed were spec design, eval loops, and security oversight.
The problem has been that practicing this still requires a different tool for every phase:
- editor for code
- a terminal for scaffolding
- a browser for testing
- a cloud console for deployment
- and a separate framework for evals.
Every transition is a context switch.
The solution to production-grade Agentic Engineering is now actually implemented in Google’s Agents CLI.
It covers the entire workflow in one place for scaffolding, evaluating, and deploying ADK agents.
One setup command injects 7 ADK-specific skills into a coding agent's context, which lets it handle scaffolding, evals, deployment, and enterprise registration through natural language.
I tested this end-to-end by building a RAG agent from scratch using Claude Code.
It scaffolded the full project from the ADK agentic_rag template, generated 20 eval scenarios with LLM-as-judge scoring, and returned a quantitative scorecard.
Finally, it also deployed everything to Agent Runtime and registered the agent to Gemini Enterprise, so the entire org can discover and use it.
The video below shows this in action, and I worked with the Google Cloud team to put this together.
Agents CLI GitHub repo → https://t.co/oOBGTVLKv8
(don't forget to star it ⭐ )
I wrote up the full build covering all six steps from install to enterprise registration.
It includes the eval scorecard, the instruction loophole the eval caught before deployment, and what the deployment process actually looks like end-to-end.
Read it below.
Karpathy method + Claude Code reading your whole Obsidian vault is the smartest second brain on earth.
The method is simple and brutal. If you can’t build a thing from scratch, you don’t know it. Tutorials are fake learning and your brain deletes them in 3 days.
Most people ignore this. They build a second brain that just sits there, folders of notes nobody reopens, dead text.
Point Claude Code at the vault and it wakes up. 5,000 notes, one mind. It reads all of it and answers in your own words and your own proofs, not a model’s guess.
Then the loop closes.
Want to understand neural nets? Skip the 3-hour video and ask Claude Code to build a tiny one. 200 lines from scratch. Watch it train, break a layer, watch it fail, fix it.
It clicks in 20 minutes instead of 3 weeks.
The second it lands the note gets written. One idea per file, linked to 10 others, dropped into the vault while the memory is still hot.
Now it compounds.
Month 1: is 60 notes. Month 6 is 900. Every new note pulls in old ones, so you ask anything and the answer comes from your brain, not the internet.
Before: 40 tabs, 6 half read PDF, 0 retained.
After: build it once, own it for life.
Setup takes 4 minutes. Plain text, no lock-in.
A second brain nobody reads is a graveyard.
Yours just started thinking.
🚨 @3BLUE1BROWN DID IT AGAIN
Language compressibility is not just a neat math trick: it is the core engine of modern LLMs.
Grant's latest video boils Shannon's entropy down to a single, powerful idea:
Prediction IS compression.
→ Predict the next word better, use fewer bits to store it
→ Shannon found English is astonishingly compressible (~1 bit per character)
→ This is the exact mechanism GPT models run on
→ Under this framing, intelligence equals compression
FUN FACT: Von Neumann told Shannon to use the term "entropy" because no one really understands it.
Today, it powers the AI revolution.
Deep-dive resources in the 🧵↓
Stop learning LLM internals from random one-off tutorials.
LLM Internals is a step-by-step GitHub learning repo for understanding how large language models work under the hood.
It helps you build a cleaner mental model by organizing blogs and videos from tokenization to attention math, Transformer components, training concepts, and inference optimization.
Key features:
• Fundamentals first – starts with LLMs, RAG, MCP, agents, fine-tuning, quantization, tokenization, and BPE
• Attention math – walks through Q/K/V, √dₖ scaling, causal masking, RoPE, and grouped-query attention
• Transformer components – covers the architecture, feed-forward networks, normalization, MoE, and LoRA
• Training concepts – includes backpropagation, cross-entropy loss, RLHF, and reasoning models
• Inference optimization – covers KV cache, paged attention, Flash Attention, speculative decoding, continuous batching, and prompt caching
It’s open-source (Apache License 2.0).
Link in the reply 👇
Algo diferencial que aún va a tardar (y quizá en España no lo veamos nunca) es la validación de señales de lenguaje no estructurado a escala. No optimizas dentro de un espacio de features cerrado, generas features nuevas desde texto que antes no era computable.
Es el único hueco donde un LLM hace algo que ni el quant ni el analista pueden.
two great callouts here, for agents that operate at sustainable cost, you need
1. the right model for the task
2. to make sure prompt caching is enabled
this is hard to support in an application because
1. the right model/provider for a task at this point can change on a weekly basis
2. APIs (including prompt caching specs) are different across providers
deepagents (general purpose, customizable harness) makes this easy because it:
1. is provider agnostic
2. enables prompt caching by default across providers
awesome write up on deepagents prompt caching by @its_ao here: https://t.co/Gruq8kF2Cy
If you use LLM-as-judge, this one is worth reading.
(bookmark it)
It's actually one of the most effective ways to use LLM-as-a-Judge for evals.
Holistic judge scores hide both their reasoning and their ceiling effects.
BINEVAL decomposes each evaluation criterion into atomic yes-or-no questions, answers each independently per output, then aggregates the verdicts into calibrated multi-dimensional scores.
Every question-level verdict is inspectable, so you can diagnose exactly why an output scored low, and the same verdicts feed straight back as targeted prompt-improvement signal.
Across SummEval, Topical-Chat, and QAGS, it matches or beats UniEval and G-Eval, training-free, with especially strong results on factual consistency.
Paper: https://t.co/oar6BZcasm
Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX
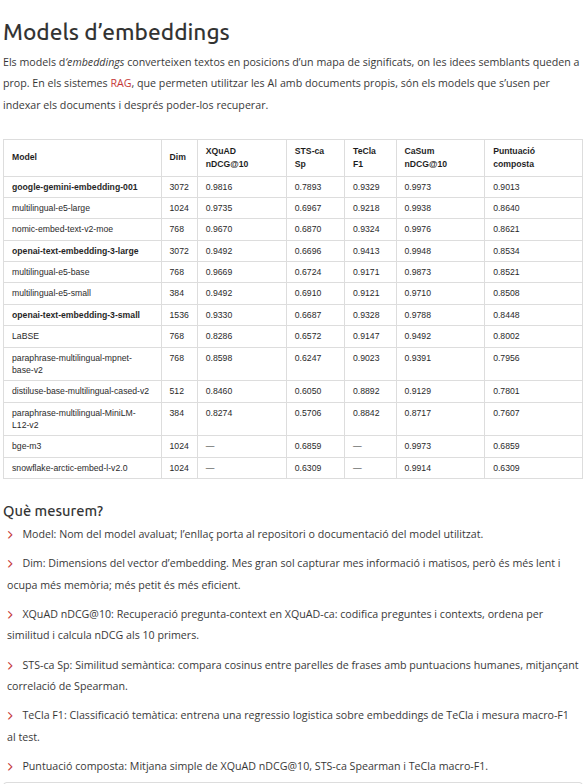
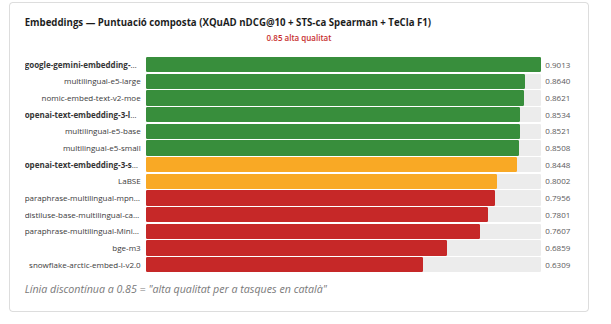
Els models d'IA d'embeddings permeten recuperar, classificar o calcular la semblança entre textos.
Són claus als sistemes RAG (AI amb els teus docs), una de les aplicacions d'IA més usades a l'empresa.
Hem fet la 1ra avaluació del seu rendiment en català:
https://t.co/qirTsoJEQQ
Head of Engineering Shopify:
"AI writes the code, AI reviews the code. Your job is just to write the loops around it."
26 minutes on how AI changed the way 3,000 engineers work inside a single company.
Ignoring it while everyone else uses AI to do more is the fastest way to fall behind.
Watch it, then read the step by step guide on loops below.
The RL framework behind GLM-5.2 is fully open source.
The full post-training of GLM-5.2 ran on it in about two days. The same stack sits behind the entire GLM series, from 4.5 to 5.1.
It is called slime, and it is built around one idea. Keep a single RL kernel, and push all the variety into data generation.
Let me explain what that means.
Every RL run has two halves. One generates experience, where the model produces responses and something scores them. The other learns from it by updating weights.
The learning half is mechanical. It reads samples, computes a loss, and steps the optimizer, the same way whether the model solves equations or drives a browser.
What changes between tasks is generation. A math run answers in a single turn and grades the result. An agent run loops through tool calls, reads results, and only then earns a reward.
slime draws the line right there. The learning half stays fixed as one kernel, and everything that differs becomes a new way to generate data.
Under the hood, it wires Megatron for training to SGLang for rollout, with a Data Buffer between them that owns prompts, custom data, and generation.
Most RL stacks grow into a pile of disconnected trainers, rollout services, and agent frameworks. slime refuses that.
Multi-turn tool use, sandbox interaction, environment feedback, and verifier rewards all enter as data generation, not as forks of the loop. So an agentic workload runs on the same loop a math run uses, and the kernel never changes.
A few things follow.
→ It is battle-tested. The loop is validated by shipping real GLM models, and it also supports Qwen3, DeepSeek V3, and Llama 3.
→ Correctness comes first. RL bugs are silent, so slime keeps the dataflow explicit and treats CI, reproducibility, and fault tolerance as real engineering.
The proof is the ecosystem on top of it. Dressage, Miles, vime, Relax, OpenClaw-RL, P1, and TritonForge all build on slime without touching the core loop.
The lesson is not that RL needs a bigger framework. It is that the variety belongs in data generation, and the training loop should stay small enough to trust.
GitHub repo: https://t.co/IFkfhBGJHx
(don't forget to star 🌟)
Since we're talking about RL, I wrote a full breakdown on fine-tuning LLMs with RL in 2026. Including how to skip manual reward engineering with automatic LLM-graded rewards.
The article is quoted below.
Me cansé de hacer la compra desde la web de Mercadona.
Así que convertí la API de Mercadona en una CLI.
Ahora cualquier agente de IA (o tú) puede buscar productos, gestionar el carrito y automatizar la compra desde la terminal.
Es open source:
https://t.co/XlW9qJn8UH
L'enginyeria basada en agents va més enllà del "vibe coding" i té com a objectiu l'automatització del màxim nombre possible de tasques del procés de desenvolupament de programari.
He actualitzat significativament aquest recull:
https://t.co/QAVLjAIrYb