Great paper on why RL actually works for LLM reasoning.
Apparently, "aha moments" during training aren't random. They're markers of something deeper.
Researchers analyzed RL training dynamics across eight models, including Qwen, LLaMA, and vision-language models. The findings challenge how we think about training reasoning capabilities.
RL training follows a two-phase dynamic that mirrors human cognition: first, the model masters low-level execution (calculations, formulas), then the learning bottleneck shifts to high-level strategic planning (logical maneuvers, backtracing, branching).
It turns out that current algorithms like GRPO apply optimization pressure uniformly across all tokens. This dilutes the learning signal. Most tokens are procedural execution. The real gains come from strategic planning tokens.
This new research introduces HICRA (Hierarchy-Aware Credit Assignment), an algorithm that concentrates optimization specifically on planning tokens rather than treating all tokens equally.
How do they identify planning tokens? Through "Strategic Grams," n-grams that function as logical scaffolding: phrases like "let's try a different approach" or "but the problem mentions that." Human annotation validated 86% of identified Strategic Grams genuinely guide reasoning flow.
On Qwen3-4B-Instruct, HICRA achieves 73.1% on AIME24 versus GRPO's 68.5%. On AIME25, 65.1% versus 60.0%. On Qwen2.5-7B-Base, gains of +8.4 points on AMC23 and +4.0 on Olympiad benchmarks.
Error analysis reveals the mechanism: during RL training, strategic errors decrease far more than procedural errors. A perfectly executed incorrect plan still fails. RL preferentially fixes high-level strategic faults because that's where the leverage is.
HICRA sustains higher semantic entropy than GRPO while maintaining lower token entropy. The difference matters because entropy regularization that promotes token-level diversity actually hurts performance. Only targeted strategic exploration improves reasoning.
Overall, the paper provides a mechanistic explanation for mysterious RL phenomena like "aha moments" and length-scaling, and demonstrates that focusing optimization on the right tokens substantially improves training efficiency.
(bookmark it)
Paper: https://t.co/mpLvne0gGk
Learn to build with AI Agents in my academy: https://t.co/JBU5beIoD0
🧵 Rethinking Entropy Regularization in RLVR
1️⃣
When I first dived into RLVR early this year — during our work on LUFFY (Learning to Reason under Off-Policy Guidance) — one term in the GRPO objective kept puzzling me:
👉 the entropy regularization term.
It’s everywhere in RL papers — yet something felt off when applied to large language models.
2️⃣
The idea sounds straightforward:
add an entropy bonus to encourage uncertainty → exploration → diversity.
This trick has powered RL success stories from Atari to robotics, helping agents escape local optima.
So intuitively, it should help language models too.
But… it didn’t.
3️⃣
When we tested it on large reasoning models, the pattern was odd:
- With a small entropy weight, entropy collapsed and performance stayed the same.
- With a large weight, entropy exploded — models produced incoherent text and training diverged.
A method that should promote healthy exploration instead caused chaos.
4️⃣
At the time, we brushed it aside — “entropy regularization costs little, so keep it in.”
But the question kept bugging me.
Why does a decades-old idea in RL break down in the LLM regime?
Eventually, we dug into it systematically.
5️⃣
We started by visualizing token-level entropy and probability distributions before and after applying strong entropy regularization.
The results were insightful:
- Entropy became uniformly high across nearly all positions.
- Probability mass spread evenly across the entire vocabulary.
The model no longer explored meaningful options — it explored everything.
6️⃣
Here’s the first difference from traditional RL: action space size.
Atari agents have maybe 4–20 discrete actions.
LLMs choose from 50k+ possible tokens at every step.
That means increasing entropy is trivially easy — just diffuse probability mass over thousands of meaningless tokens.
Exploration becomes uninformative noise.
7️⃣
The second difference: trajectory length.
RL agents act for dozens or hundreds of steps; LLMs generate thousands of tokens per rollout.
Entropy is summed across all positions, so its cumulative gain scales with sequence length.
Add autoregression — where early uncertainty propagates forward — and you get a chain reaction: local noise turns into global explosion.
8️⃣
These two structural factors — vast action space and long trajectories — explain why naive entropy regularization fails in RL for large reasoning models.
Instead of structured exploration, it creates uniform chaos, flattening meaningful probability structure and destabilizing optimization.
9️⃣
So we rethought the idea from the ground up.
Rather than maximizing entropy everywhere, we apply it selectively — only to the meaningful subset of tokens at critical positions that truly guide reasoning.
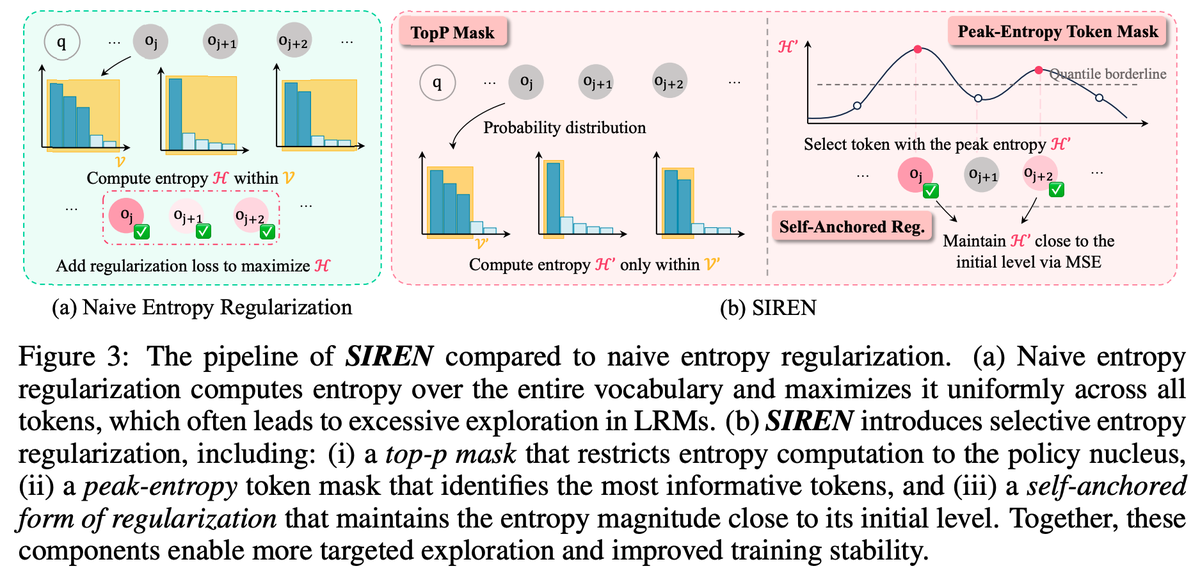
Our method uses a two-step entropy masking:
1) Top-p mask confines entropy computation within the policy nucleus — the semantically meaningful portion of the vocabulary.
2) Peak-entropy mask focuses regularization on high-impact tokens (like logical connectors or reasoning pivots) along long trajectories.
Together, these masks channel exploration where it matters — not everywhere.
🔟
We call this SIREN — Selective Entropy Regularization for Policy Optimization.
Beyond selective masking, SIREN introduces self-anchored regularization — a dynamic baseline that stabilizes the overall entropy level throughout training, preventing both collapse and runaway explosion.
This transforms entropy regularization from a blunt force into a precision tool.
Training becomes stable, exploration remains active, and reasoning quality steadily improves.
Across five mathematical reasoning benchmarks, SIREN outperforms strong RL baselines (Dr.GRPO, Clip-Cov, EntropyAdv, etc.), achieving +6.6 maj@k gains on AIME24/25 with Qwen2.5-Math-7B.
What works for short-horizon agents breaks for long-horizon reasoning.
The key isn’t more entropy — it’s selective entropy.
🧩 Read the paper:
📄 Rethinking Entropy Regularization in Large Reasoning Models
🔗 arXiv: https://t.co/WlswG9awdY
🔗 GitHub: https://t.co/93Ya6qJd0p
Introducing Multi-Agent Evolve 🧠
A new paradigm beyond RLHF and RLVR:
More compute → closer to AGI
No need for expensive data or handcrafted rewards
We show that an LLM can self-evolve — improving itself through co-evolution among roles (Proposer, Solver, Judge) via RL — all without external supervision.
On Qwen2.5-3B-Instruct, Multi-Agent Evolve boosts average accuracy from 55% → 58% across 22 benchmarks.
Remarkably, the model automatically learns balance among roles:
- The Proposer first generates easy tasks.
- The Judge refines the difficulty metric.
- The Proposer then raises the challenge, forcing the Solver to improve.
- The system co-evolves until reaching equilibrium.
Multi-Agent Evolve: LLMs self-improve through co-evolution.
📄 Paper: https://t.co/PY62OFhTgH
💻 Code (coming soon): https://t.co/DFGGb0qRgw
@KalteneggerLisa It is, indeed an incredible fact that what the human mind, at its deepest and most profound, perceives as beautiful finds its realization in external nature.… What is intelligible is also beautiful. Subrahmanyan Chandrasekhar
My research got featured in the @Forbes magazine 🚀! Such an immense pleasure to witness the impact of my ideas on human knowledge.
https://t.co/pcDHluK9DY
#research#space#astronomy
This could have something to do with the Fermi Paradox that our galaxy doesn't appear to be swarming with intelligent life: the least common type of solar system is ours, "Ordered," with the smaller planets close to the star and gas giants further out.
https://t.co/5UH0VSiEPZ
I'm discussing “Four Classes of Planetary System Architecture” with @BobprayD, Rajarshi Prattipati, @sierra_photon, @exomishra, Hansen F., and Quantum Photonics. Today, Mar 3 at 11:30 PM GMT 8 in @clubhouse. Join us! https://t.co/CzBBNT8m84
Dr. Lokesh Mishra Physics Inst, Space Research & Planetary Sciences , U Bern Dept. of Astronomy, Faculty of Science, U Geneva talks about his paper in a fireside chat at the @qpclub1 in @Clubhouse w/ @ceciletamura , @sierra_photon , @BobprayD
https://t.co/dXCn5LKQia
@robinhanson Our work, actually, allows us to probe this hard question in a mathematical sense: Is Habitability a planetary system level phenomena?
See paper 1 for details https://t.co/MrOv4j7iDE
Interesting work by @exomishra on the classification of planetary systems. https://t.co/4gqNHAk6rC Suggests there are 4 basic types (of which our "ordered" solar system is the rarest), dictated by the initial conditions for planetary formation.
#arXiv A framework for the architecture of exoplanetary systems. I. Four classes of planetary system architecture https://t.co/AgVXlNoW5V II. Nature versus nurture: Emergent formation pathways of architecture classes https://t.co/Jrih2YFSJm
[2301.02373] Lokesh Mishra, Yann Alibert, Stéphane Udry et al.: A framework for the architecture of exoplanetary systems. II. Nature versus nurture: Emergent formation pathways of architecture classes https://t.co/p4DVHFQkOb https://t.co/4KPG2RpEWo #astro_ph_EP
[2301.02374] Lokesh Mishra, Yann Alibert, Stéphane Udry et al.: A framework for the architecture of exoplanetary systems. I. Four classes of planetary system architecture https://t.co/oN8rsvPbdY https://t.co/lZ5IPYXghj #astro_ph_EP
Schon lange ist der #Astronomie klar: #Planetensysteme sind nicht zwingend wie unser #Sonnensystem aufgebaut. Forschende der #unibern, der @unige_en sowie des @NCCRPlanetS zeigen erstmals: Es gibt insgesamt vier Klassen von Planetensystemen. https://t.co/eTC95L5X69