[1/8]
🐶 AgentDoG 1.5: a diagnostic guardrail for AI agents.
Most safety models say "unsafe." AgentDoG names which step, what risk, what harm.
4B hits 55.2% on fine-grained diagnosis. GPT-5.4: 25.8%.
�� https://t.co/oOGDYfEHjV
💻 https://t.co/wmi1DUtyV7
#AISafety #Agent
Very excited to share that our ICML 2026 paper has been selected for an Oral Presentation! 🎉@icmlconf
Characterizing, Evaluating, and Optimizing Complex Reasoning
Reasoning is not just about reaching the right answer — the quality of the thinking process matters.
We show that complex reasoning traces can be represented as structured DAGs, evaluated through efficiency/effectiveness at both macro and micro levels, and optimized with a Thinking Reward Model.
Key insight: stronger reasoning does not simply mean thinking longer, but thinking in a more structured, purposeful, and verifiably useful way.
📄 Paper: https://t.co/cpm2BiyMxP
💻 Code: https://t.co/R70wTRGRBt
See you at ICML 2026! #ICML2026 #Reasoning #LLM
Thanks for sharing! π-BENCH evaluates whether agents can proactively resolve incomplete user requests by tracking long-range dependencies across prior sessions, workspace files, memory, and artifacts.
π-Bench
A new benchmark for proactive AI assistants.
100 long-horizon tasks across 5 personas test whether agents can spot hidden intents, recover missing context, and ask the right question before acting.
Even top models complete tasks yet struggle to read between the lines.
✨ Introducing π-BENCH: a benchmark for proactive personal assistant agents in long-horizon workflows.
Real personal assistants work in continuous application scenarios: research projects 🔬, legal handoffs ⚖️, marketing campaigns 📣, financial analysis 📊, pharmaceutical documentation 💊, and more.
In these settings, a task today may depend on something from much earlier: a decision made several sessions ago, a file updated last week, a previous artifact, or a persistent user preference.
π-BENCH tests whether agents can connect these dots across sessions—and, more importantly, use them proactively.
- Can the agent notice what the user forgot to mention?
- Can it ask the right clarification before going in the wrong direction?
- Can it reuse prior context instead of making the user repeat it?
That is the core of π-BENCH: evaluating whether agents can handle long-range dependencies and proactively resolve unstated user intents in realistic, multi-session personal-assistant workflows. 🧵
Huggingface: https://t.co/lUsbrxbza0
Project page: https://t.co/H9zmCBL2AP
Thank you so much, Clem! Really honored to be selected as Paper of the Day 🙏
We hope SU-01 can provide a simple and open reference for studying long-horizon reasoning, self-verification, and olympiad-level scientific problem solving in compact models.
Great question. Olympiad problems are not the same as day-to-day research problems — they are deliberately compressed, self-contained, and often have elegant hidden structures.
But that is also why they are useful: they stress-test core abilities needed in research, such as abstraction, long-horizon search, rigorous verification, and repairing flawed arguments.
We also tested FrontierScience-Research, which is closer to research-style scientific reasoning, and SU-01 achieved the best overall performance among similar-size models there. So our view is: olympiads are not “reality,” but they are a clean and demanding proxy for some key ingredients of real research reasoning.
It surprised me too.
But my takeaway is not that math is easy — rather, math is a very clean and unforgiving testbed for long-horizon reasoning: search, abstraction, verification, and repair.
What surprised me most is that a 30B-A3B model can now sustain this process over 100K+ tokens and reach gold-level results.
Even 30B models are crushing grad level math. The hard to escape conclusion is math isn’t actually that hard. Humans are just really bad at it.
Writing a 40 page short story with narrative consistency probably requires more intelligence than winning an IMO gold medal
Thank you! This part also surprised us.
A 30B-A3B model sustaining 100K+ token reasoning, while repeatedly searching, verifying, and repairing its own proof, was far from obvious to us at the beginning of the project.
The pace of progress is indeed hard to extrapolate.
> The resulting model, SU-01, supports stable reasoning on difficult problems with trajectories exceeding 100K tokens
Incredible stuff is being done. It’s hard to imagine what AI models will be capable of in a year.
Yes, exactly. The compute and data requirements are relatively modest compared with frontier-lab-scale recipes.
We do see encouraging signs of scaling beyond olympiad problems: SU-01 achieves the best overall performance among similar-size models on FrontierScience-Research, a benchmark targeting research-style scientific reasoning across physics, chemistry, and biology, even though we did not train on research-specific data.
This suggests that rigorous proof-search and self-verification abilities can transfer to broader research-level reasoning. With more dedicated research-oriented data and training, we believe this direction could be pushed further toward stronger research models.
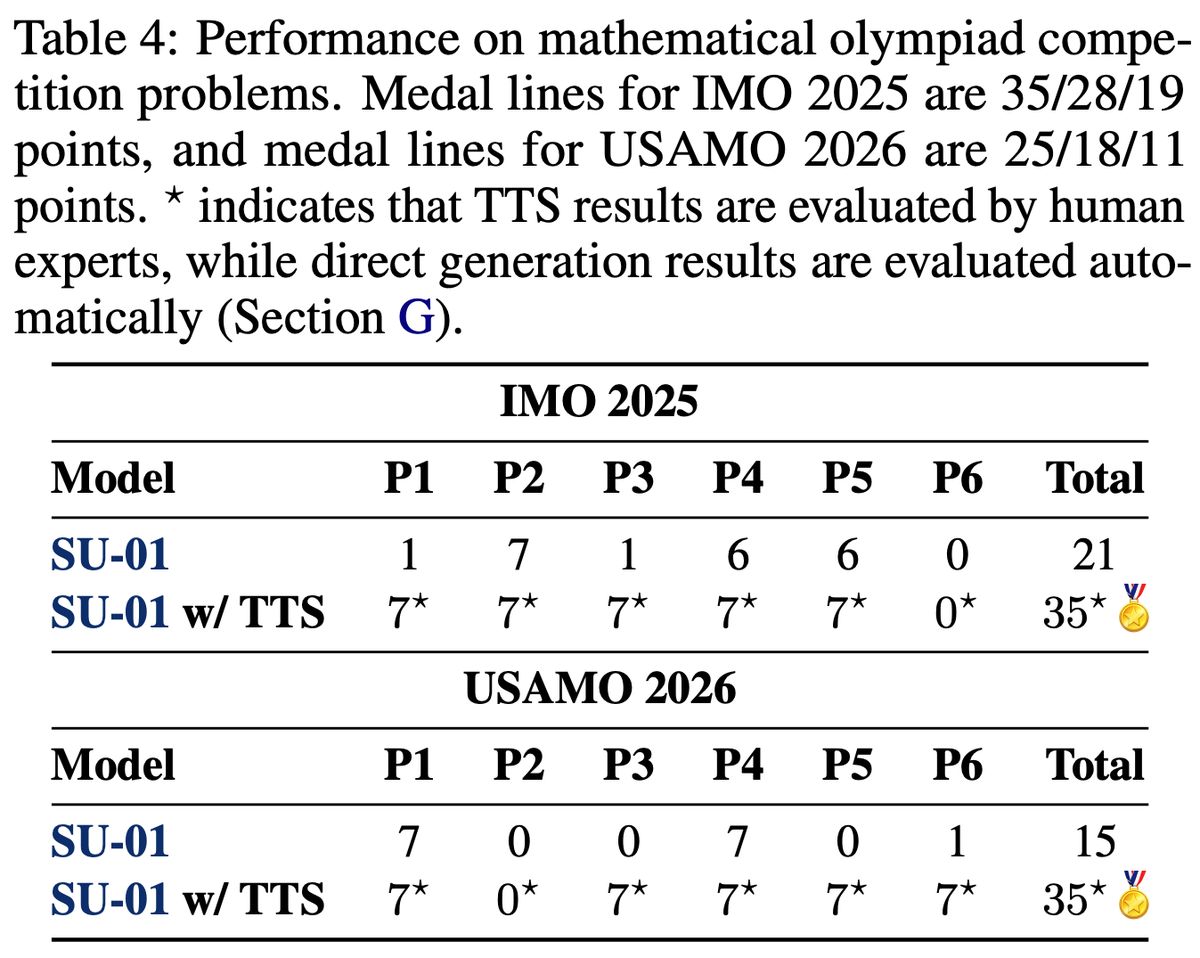
### 4/4 USAMO 2026 results
USAMO 2026 was a very hard competition.
Among 340 human contestants, the mean score was 8.59, the median was 6, and the highest score was 35. The gold line was 25.
SU-01 scored **35** with test-time scaling, matching the highest human score and far exceeding the gold line.
It also received full credit on Problem 3, where the human average was only 0.01 and no contestant scored above 5.
Can a simply trained 30B model reach gold-medal-level olympiad reasoning in pure natural language?
In our new report, we introduce **SU-01**, a 30B-A3B model trained with a simple unified recipe for rigorous mathematical and scientific reasoning.
The recipe is intentionally lightweight: around **340K sub-8K-token SFT trajectories**, followed by only **200 RL steps**, then test-time verification and refinement.
The resulting model supports stable reasoning on difficult problems with trajectories exceeding **100K tokens**.
With test-time scaling, SU-01 achieves:
- **35 points on IMO 2025**, meeting the gold-medal line;
- **35 points on USAMO 2026**, far above the 25-point gold line and matching the highest human score among 340 contestants. It also received full credit on Problem 3, where the human average was only 0.01 and no contestant scored above 5;
- gold-level performance on **IPhO 2024/2025**;
- **70.2% on IMO-ProofBench**, close to Gemini 3.1 Pro Thinking.
The key takeaway is simple:
Olympiad-level scientific reasoning may not require a giant model or a heavily customized pipeline for each domain.
What matters is learning a reusable loop of **proof construction, verification, and refinement**.
We have open-sourced the code and model:
Paper: https://t.co/9ZQmttLo8x
Github: https://t.co/yrLWY4Cl7i
Model: https://t.co/qJqXRxrYv0

![dong_rui39501's tweet photo. [1/8]
🐶 AgentDoG 1.5: a diagnostic guardrail for AI agents.
Most safety models say "unsafe." AgentDoG names which step, what risk, what harm.
4B hits 55.2% on fine-grained diagnosis. GPT-5.4: 25.8%.
�� https://t.co/oOGDYfEHjV
💻 https://t.co/wmi1DUtyV7
#AISafety #Agent https://t.co/lmd2x6i7oj](https://pbs.twimg.com/media/HJ8eLtmbgAAfdJl.jpg)