how does the brain build and track an internal state of the world from (possibly incomplete and noisy) visual observations?
i believe visual state tracking will be the grand challenge for vision in the coming years, and i hope this benchmark can be a useful starting line. enjoy!
Game engines let you spawn anything into a scene. World models don't. Once the camera moves, you're stuck with whatever the model dreamed up.
🧵 We fix that with SPAWN, a training-free method that injects a custom concept into the rollout from either an image or a text prompt.
Looks like I didn't do a good job of sharing this before but...
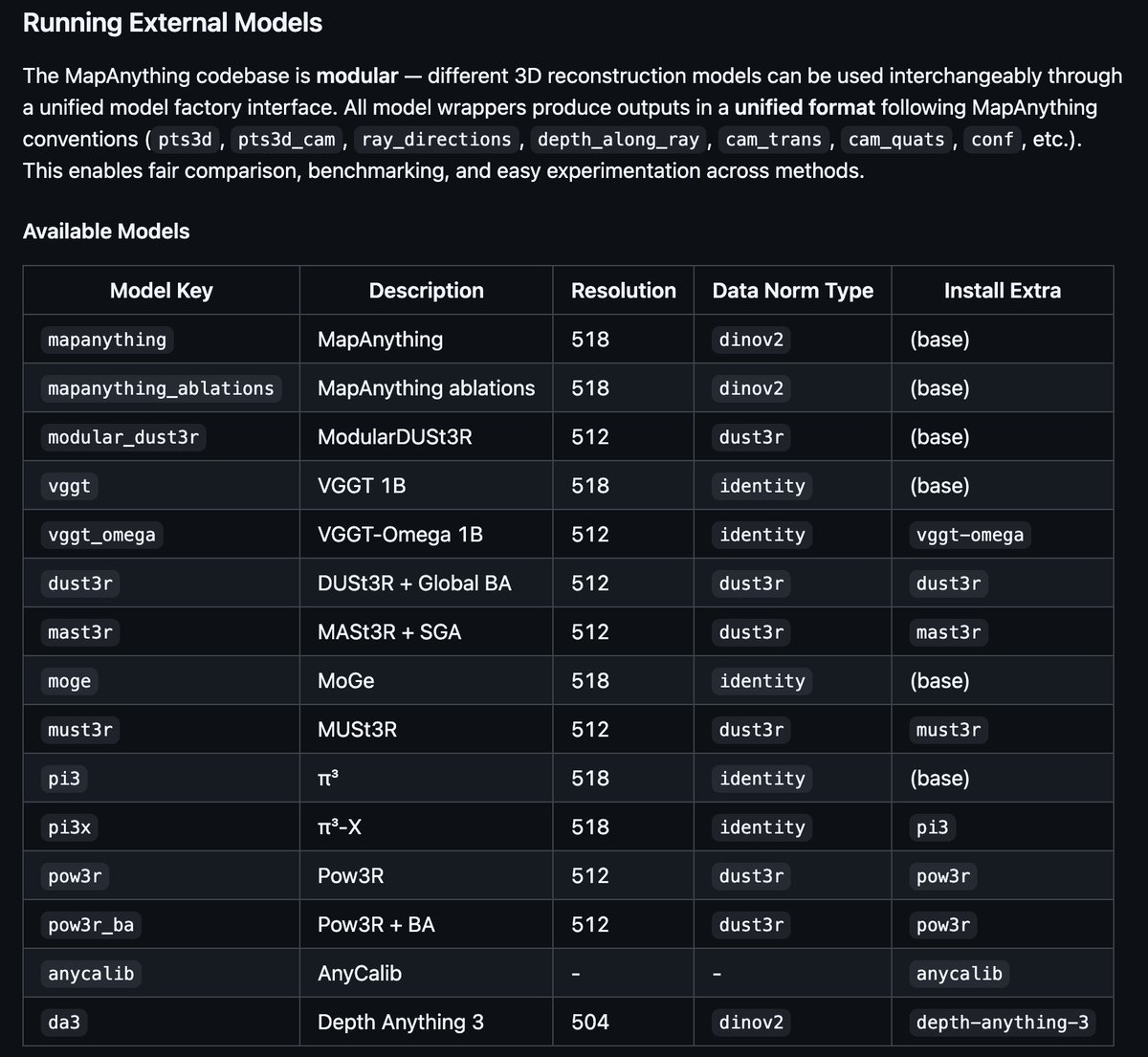
Yes, you can infer, visualize, compare, train and finetune all the geometry foundation models in the MapAnything codebase‼️
really excited to finally release this one.
guidance is critical for getting flow and diffusion models to do what we want, but most methods in the literature are heuristic and work for unclear reasons. the field likes to frame it as reward-tilted sampling, yet what people run in practice is often nowhere close to that.
here we take a different angle, deriving guidance from first principles as an optimal control problem. existing methods drop out as coarse approximations, and the flow map emerges as the fundamental ingredient for effective guidance.
our approach is training-free, and reaches state-of-the-art performance across diverse benchmarks at up to 70x fewer NFEs.
amazing work by @jrrhuang, justin, kartik, and sheel.
stay tuned for more on the finetuning side!
AM-ARM200 is here: 6+1 DoF, 1kg payload, 52cm reach — all for a $240 follower BOM. 🤯
It brings the SO-ARM100 open-source philosophy into a whole new capability class. Built for real-world manipulation, not just tabletop demos.
And yes, you drive it exactly like a SO-ARM100.
Fully compatible with @huggingface@LeRobotHF
GitHub: https://t.co/srLxZZgZDr
#EmbodiedAI #Robotics #OpenSource @RemiCadene
How much does a language model forget when finetuned on new tasks? We show both model size and optimization matter and forgetting can be nearly eliminated with self-generated replay!
https://t.co/Qs9A4n095s
w/@mrtnm@dongkyucho@ShikaiQiu@rumichunara@Pavel_Izmailov 1/8
Gemini Omni Flash - monalisa edition 🤩
This model is so coherent in arts and science at the same time
zooming in monalisa showing paints to the molecules to atom with coherent text 🤯
omg we are so back and the speed , super hyped for omni pro
What do JEPA-style self-distillation dynamics actually learn — and why do they sometimes avoid collapse?
In our new work with @BasileTerv987 and Jean Ponce, we tackle this question.
What surprised us: These dynamics provably recover representations with nonlinear-CCA structure.
Language Models Need Sleep
"Transformer-based large language models are increasingly used for long-horizon tasks; however, their attention mechanism scales poorly with context length. To handle this, we study a sleep-like consolidation mechanism in which a model periodically converts recent context into persistent fast weights before clearing its key-value cache."
"increasing sleep duration N for our models improves performance, with the largest gains on examples that require deeper reasoning."
🎉 We released MIKASA-Robo-VLA v1.0.0 — a benchmark suite for studying memory in Vision-Language-Action (VLA) policies for tabletop robotic manipulation.
https://t.co/LLN7sCokx2
🧠 The goal is simple:
make memory evaluation in robotic manipulation more systematic.
👇
Our paper was accepted as a #ICML2026 Spotlight!
Reasoning in LLMs has improved largely by chaining local steps. But is that the whole story?
Humans occasionally make inferential "leaps" across domains, a faculty known as analogy.
We design a synthetic task to show how small Transformers acquire analogical reasoning, and find that the same signatures appear in pretrained LLMs.
arxiv: https://t.co/1WCizIKWly
code: https://t.co/82kOKCtJo7
📢 Accepted to TMLR, with reproducibility certification 🏅
v2 of our JEPA-WM study (arXiv:2512.24497) is out, with new data-scaling experiments, a Lipschitz analysis of multistep rollout training, and extended discussions.
Recap + what's new 👇
w/ @JimmyTYYang1, Jean Ponce, @AdrienBardes, @ylecun
I uploaded a screenshot of Google Maps to Gemini Omni with a route drawn on it.
Then I prompted it to create a first person view of someone driving a taxi cab along the route in the reference image.
Pretty close to the real thing.
New paper: AsymFlow🔥
JiT x0-prediction is not enough for pixel generation. Better keep velocity in a low-rank subspace:
- 1.57 FID on ImageNet (best pixel flow model)
- Finetunes FLUX.2 klein into pixel space, beats the original on HPSv3/DPG/GenEval (#1 overall on HPSv3)
1/7
🚀 🚀 🚀 Excited to share our new paper:
Remember to be Curious: Episodic Context and Persistent Worlds for 3D Exploration
What does it take for an agent to stay curious in a 3D world?
The answer is memory.
🌐 Project: https://t.co/G4SjLoFJht
📄 Paper: https://t.co/iUFwp5NvRu
💻 Code: https://t.co/KZRaQLyzyh
🚨New paper!
📃Mechanisms of Misgeneralization in Physical Sequence Modeling
Planners for the physical world produce motions that look safe, but quietly change quantities the demonstrations are meant to control.
When does this happen? Why? Can we predict it before training?👇🧵
Guide with examples, not rewards 🐘
Controlling what a pretrained generative model produces is still mostly a choice between three slow options: fine-tune it, attach a reward network, or search at inference. We found flow matching allows a fourth, and it costs almost nothing.
In deterministic interpolants, the velocity of the flow is determined by where the trajectory is headed: the endpoint mean. Shift that mean, and the entire flow shifts with it.
This turns control into a matter of reference. Change the examples that define the endpoint, and you change the direction the model follows. The examples need not be perfect. They only need to point the flow toward the attribute you want.
Color, identity, style, and structure, all controllable through examples. 🧵👇