How much does a language model forget when finetuned on new tasks? We show both model size and optimization matter and forgetting can be nearly eliminated with self-generated replay!
https://t.co/Qs9A4n095s
w/@mrtnm@dongkyucho@ShikaiQiu@rumichunara@Pavel_Izmailov 1/8
We tried self-generating instruction data but it didn't seem to work, at least from our brief testing. Llama-3.2-1B-Instruct is able to generate something that looks like a user prompt but it never generated the end of turn token. I think the reason is that models are usually not trained on prompts (only on the responses).
I believe that we also tried using chat datasets (not self-generated) but I don't remember how well it worked. Naively, I would expect chat datasets to be smaller and less diverse than pretraining datasets, but also the format is different. So there might be cases where instruction data is preferable over pretraining data. We haven't really explored this but I think it could be interesting.
How should we scale Adam’s hparams with batch size? I had some spare TPUs available so I remastered Figure 4 from our paper on batch size at a higher resolution. Using a 30M language model, we find a constant β₂ half-life (10M tokens) to be optimum across batch sizes.
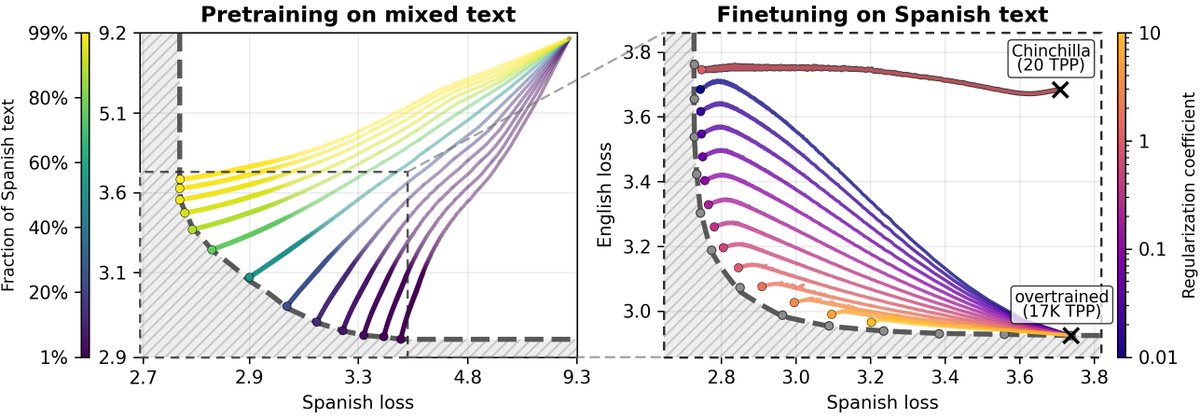
@cuneytgurcan@andrewgwils@dongkyucho@ShikaiQiu@rumichunara@Pavel_Izmailov There's definitely a lot going on in Figure 1. Left plot is pretraining trajectories, starting from a fixed random initialization. Right plot is finetuning trajectories starting from two different checkpoints: one that's Chinchilla-pretrained and one that's overtrained.
@garybasin@Pavel_Izmailov@AtakanTekparmak We pretrained small models on 10 to 17,000 tokens per parameter (TPP). For reference Qwen3-0.6B is 60,000 TPP whereas Qwen3-235B-A22B is only 153 TPP. While we haven’t tested models at this large scale, we would certainly expect a large difference in spare capacity.
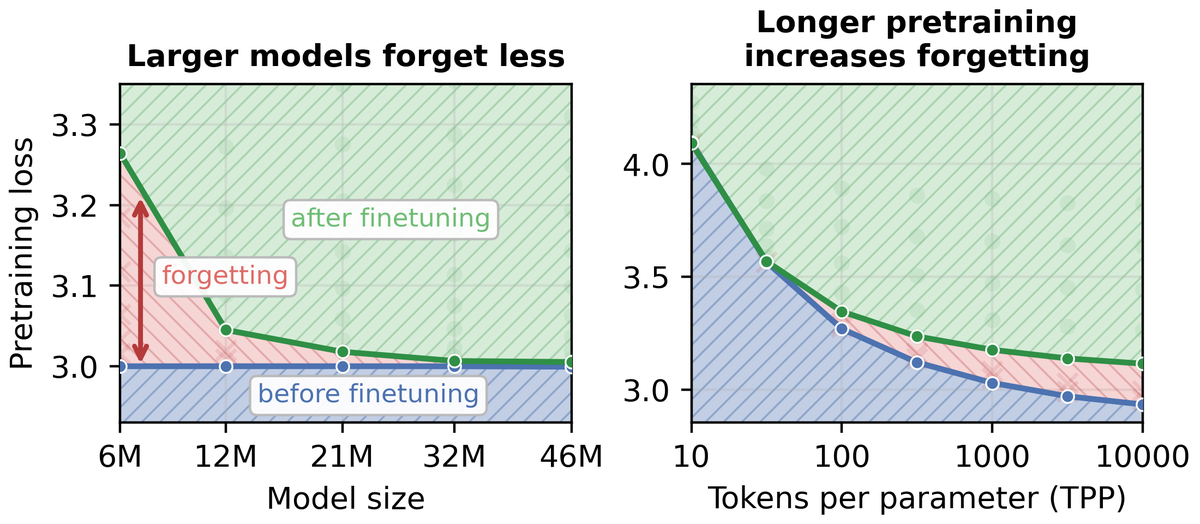
@Farfan__@andrewgwils@dongkyucho@ShikaiQiu@rumichunara@Pavel_Izmailov Figure 4 is 205M model pretrained on 30B tokens, Figure 9 is Llama-3.2-1B. But yes, we generally study small models. Forgetting is most severe when the model is small and trained for long. We run sweeps over 100B token finetuning jobs, which gets expensive.
New paper: https://t.co/LGbYhYytbt
The main idea is that we can use an LLM to generate its own replay data to prevent forgetting, as long as we have spare capacity. Very overtrained models have to forget to learn new information.
@bspectacledGOAT@andrewgwils@dongkyucho@ShikaiQiu@rumichunara@Pavel_Izmailov Exactly! But if you have access to the pretraining data or data that is very close in distribution, it might be more practical to use that data rather than sampling. (Sampling is somewhat expensive and can be tricky to implement)
@atu_tej@andrewgwils@dongkyucho@ShikaiQiu@rumichunara@Pavel_Izmailov Seems to be the same basic idea! One difference is that this paper uses only NTP loss for the replay data(?) We find KL to work slightly better on self-generated data and much better on off-policy data. And we also relate the regularization strength to model capacity
@ThinkDi92468945@andrewgwils@dongkyucho@ShikaiQiu@rumichunara@Pavel_Izmailov We find that models with spare capacity are easier to finetune but we haven't tried expanding the capacity of a model. I think that would be an interesting experiment, although the resulting model might be impractical in terms of inference serving
We can even generate replay data from an instruction-tuned LLM. For example, when finetuning Llama-3.2-1B, we can prompt the model with a BOS token (without a chat template) and generate pretraining-like data. With a KL penalty, this data significantly reduces forgetting. 4/8
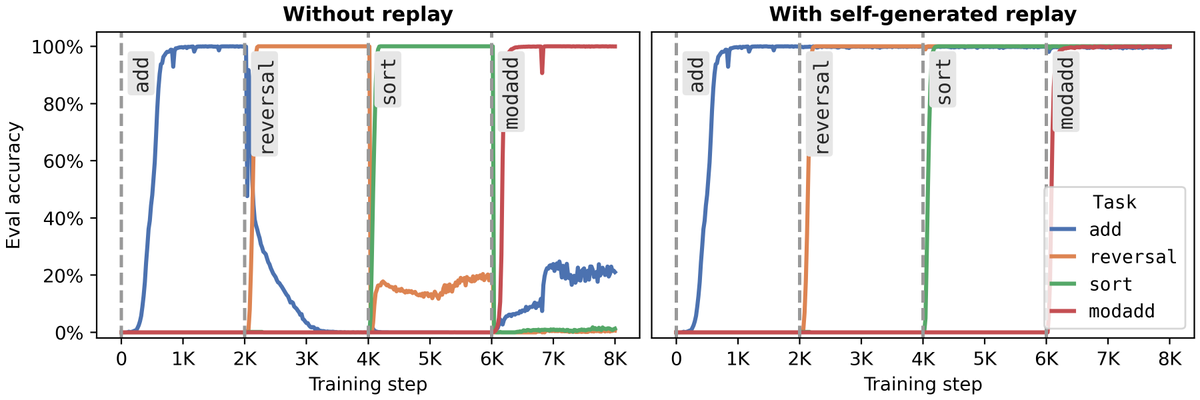
When does forgetting still happen? When the model has no spare capacity. Small models trained to saturation cannot absorb new information without overwriting old information. 5/8
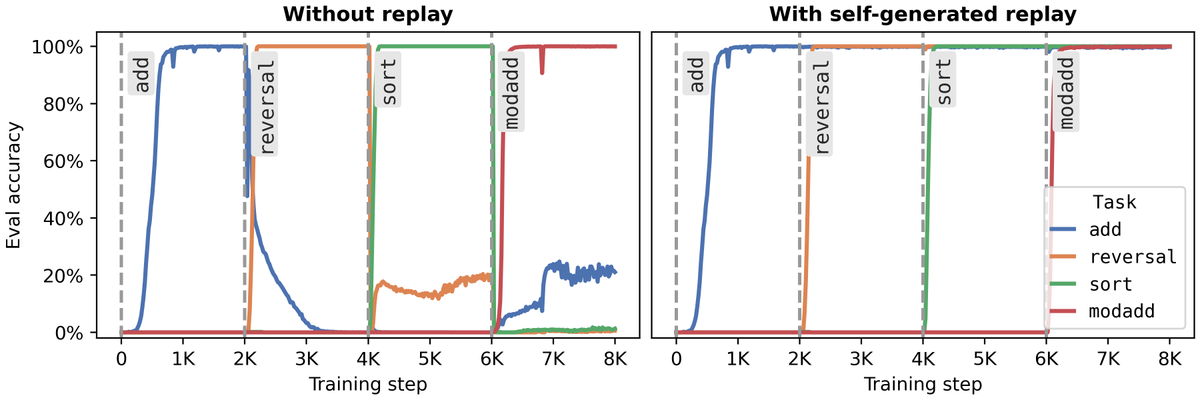
Unfortunately, pretraining data is often unavailable! But since LLMs are generative models, we can use them to directly sample data. In this continual learning experiment with a 2M parameter language model, self-generated replay entirely eliminates forgetting. 3/8