@karpathy Congrats on joining Anthropic, Andrej! 🚀 Truly exciting news for the AI community. We’re all eagerly looking forward to seeing your impact and can't wait for the amazing new features and models you'll help ship! Best of luck!
🧵Google DeepMind just dropped a bombshell:
An AI agent that autonomously writes algorithms better than humans.
It’s called AlphaEvolve, and it could completely change how we build software and solve problems.
Here’s why this changes everything👇
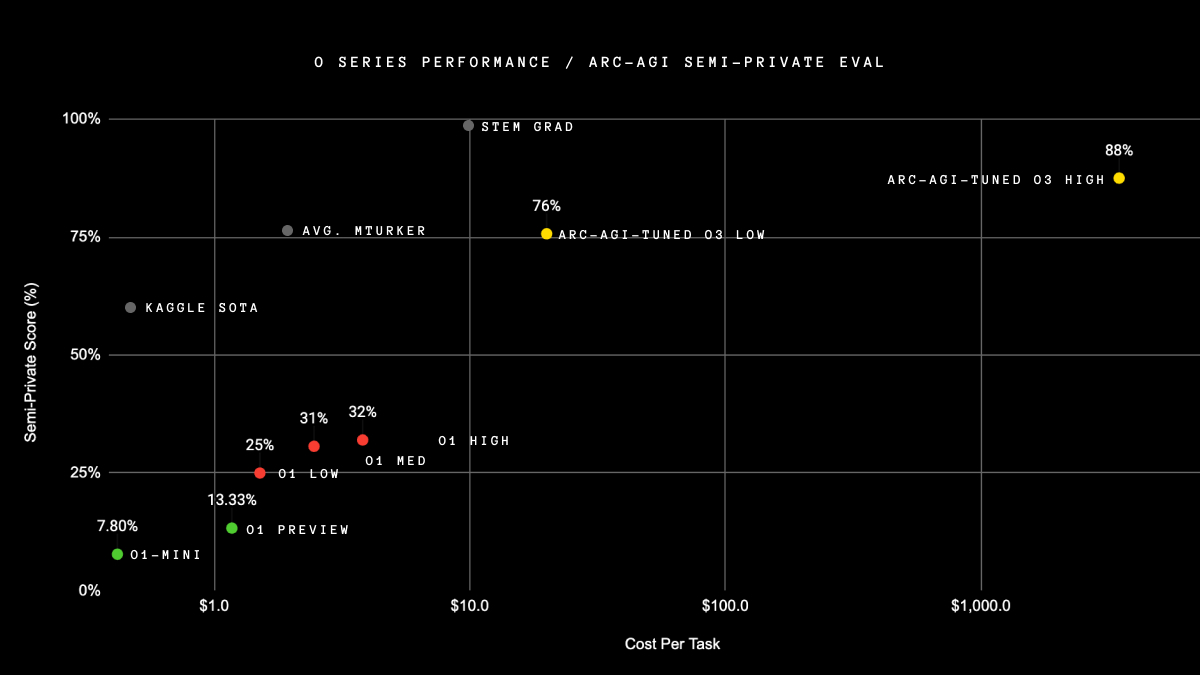
Evaluations are essential to understanding how models perform in health settings.
HealthBench is a new evaluation benchmark, developed with input from 250+ physicians from around the world, now available in our GitHub repository.
https://t.co/s7tUTUu5d3
Entre emocionado y acojonado al saber que nos ha tocado vivir la época en la que el ser humano desarrollará la AGI.
El descubrimiento del fuego se queda corto en comparación con esto.
Las implicaciones son dignas de catapultarnos en pocas décadas a escenarios impensables.
Implementing Contextual Retrieval RAG 🔎
@AnthropicAI recently released a cool RAG trick that significantly improves retrieval and is made cost-effective through prompt caching: prepend metadata to each chunk that details where it’s situated within the entire document.
This requires N LLM calls where each call has the entire document stuffed in as a prefix, so this depends heavily on prompt caching for token cost reduction.
Thanks to @ravithejads, we’ve created a full reference notebook that allows you to easily build a RAG pipeline with contextual metadata extraction + @llama_index abstractions. We also have a full evaluation section demonstrating improved BM25 + embedding retrieval performance with contextual retrieval implemented!
Check out our notebook here: https://t.co/8qtX8Qzq0a
I've been wanting to try out ColBERT for a while - and this made it so easy I had no reason not to!
Added a page on how to use RAGatouille in LangChain! The RAGatouille interface lined up nicely with the LangChain one so was quite easy 😎
👏👏 @bclavie
https://t.co/Cz88bk0GOs
In collaboration with the @googledevs team, we’re excited to release the most comprehensive workshop on building with Google Gemini - in both the advanced RAG and multi-modal settings! 🌟
Advanced RAG: use the Google semantic retriever, with the Google AQA model (with uncertainty scores/safety settings), with @llama_index reranking modules
Multi-modal RAG: Present high-level architecture and showcase how you can do it with Gemini.
Video: https://t.co/yfUIL0YDYt
We have two main Gemini notebooks for you to walk through after watching this video. Check them out as well 👇
Advanced RAG with semantic retriever + AQA: https://t.co/9pB7VRV7Cs
Multi-modal Notebook: https://t.co/jrzmB0MWPG
Come join us for a special holiday workshop on 12/21 ❄️🧑🏫 where we cover two cool LLM + RAG use cases with Google Gemini:
1️⃣ Multi-modal RAG: Use the Gemini model to extract structured outputs from images. Then learn how to index these texts + images and build a QA system from it (also using Gemini).
2️⃣ Advanced RAG: Learn how to use the brand-new Semantic Retrieval API. You can decompose it into different components - custom embedding-based retrieval and custom response synthesis.
We'll be joined by some folks from the Google Labs team as well!
Next Thursday at 9am PT. Signup here: https://t.co/sBZNNgBgCY
The LVM (large vision model) revolution is coming a little after the LLM (large language model) one, and will transform how we process images. But there’s an important difference between LVMs and LLMs:
- Internet text is similar enough to proprietary text documents that an LLM trained on internet text can understand your documents.
- But internet images – such as Instagram pictures – contain a lot of pictures of people, pets, landmarks, and everyday objects. Many practical vision applications (manufacturing, aerial imagery, life sciences, etc.) use images that look nothing like most internet images. So a generic LVM trained on internet images fares poorly at picking out the most salient features of images in many specialized domains.
That’s why domain specific LVMs – ones adapted to images of a particular domain (such as semiconductor manufacturing, or pathology) – do much better. At @LandingAI , by using ~100K unlabeled images to adapt an LVM to a specific domain, we see significantly improved results, for example where only 10-30% as much labeled data is now needed to achieve a certain level of performance.
For companies with large sets of images that look nothing like internet images, I think domain specific LVMs can be a way to unlock considerable value from their data. Dan Maloney and I share more details in the video.