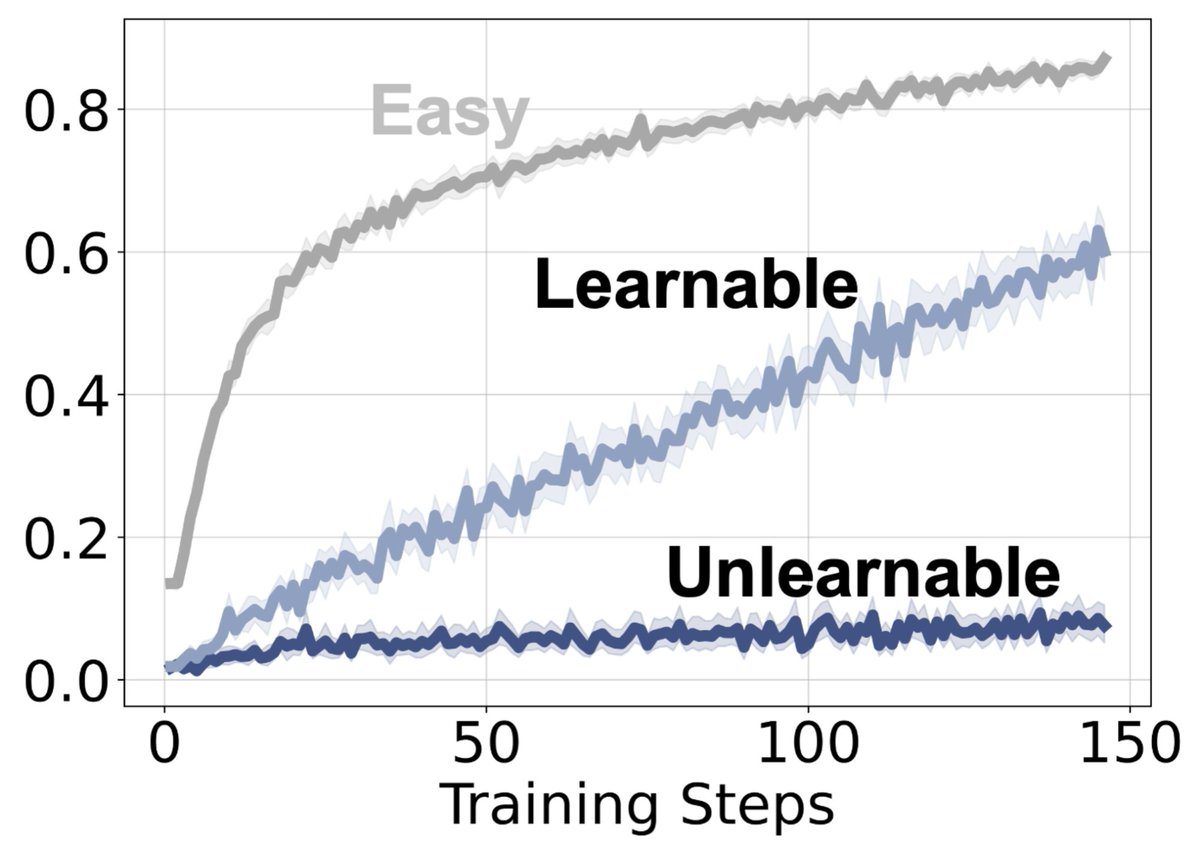
Most assume unlearnable examples never get positive reward. They do.
In our ICML paper, We reveal that a hard problem can receive positive reward during RLVR but remain unlearned.
We show the phenomenon is more likely a representation issue rather than RL optimization artifact.
🚀 Excited to share our new paper: “Lossless Anti-Distillation Sampling” (LADS)!
We propose a sampling-based defense against multi-account distillation that weakens distillation while preserving a lossless experience for benign users. 🛡️
Paper: https://t.co/lAvcDxmvac
RL on LLMs inefficiently uses one scalar per rollout. But users regularly give much richer feedback: "make it formal," "step 3 is wrong."
Can we train LLMs on this human-AI interaction?
We introduce RL from Text Feedback, with 1) Self-Distillation; 2) Feedback Modeling (1/n) 🧵
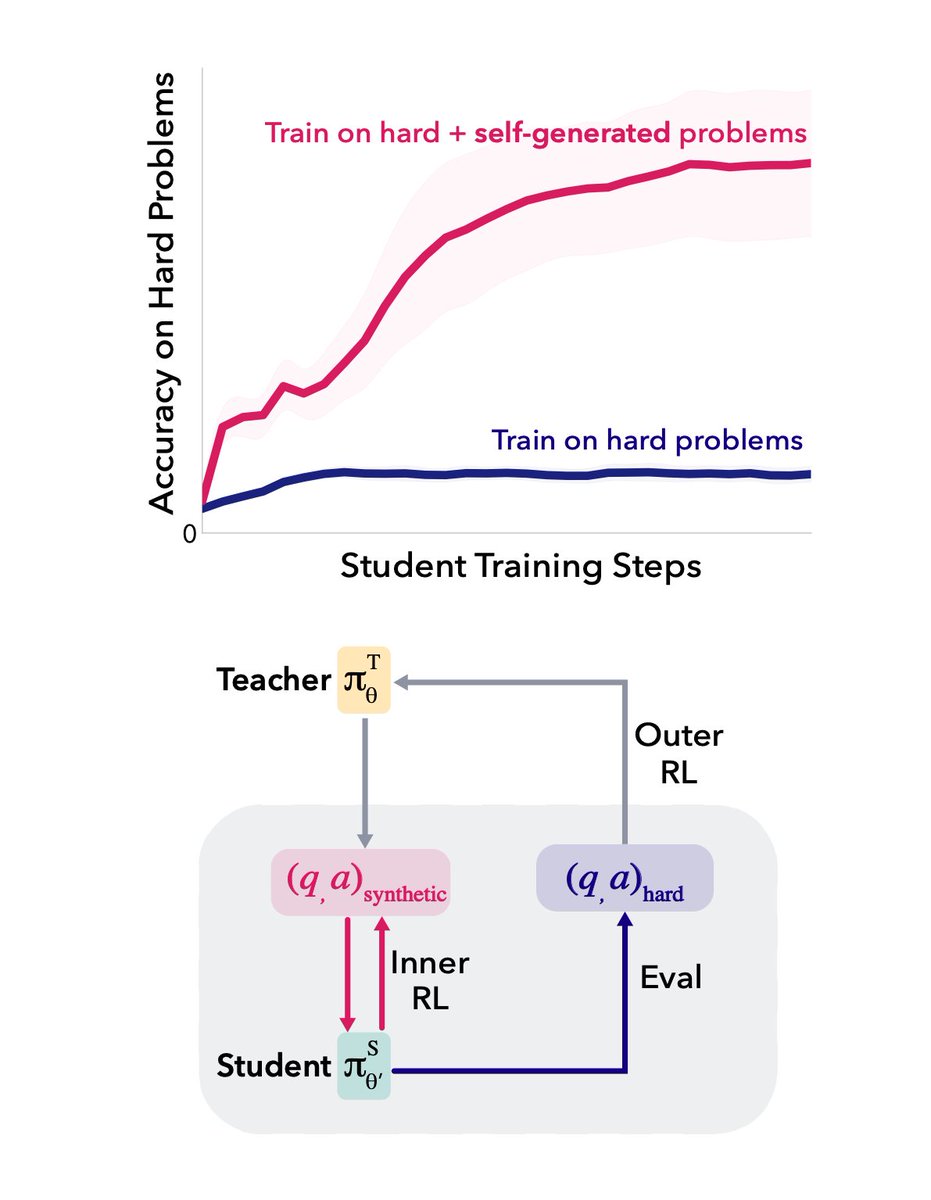
Can a model learn to break its own reasoning plateau?
In our new paper, we show that LLMs can be taught with meta-RL to generate their own "stepping stones" that kickstart learning on hard math problems (0/128 success rate) where direct RL fails.
Paper 📝: https://t.co/lUlrJt6bwq
Blog post 🌐: https://t.co/v1y24h1fP4
(1/n)
🚀 ML / Applied Math / Stats PhD Opportunities @JohnsHopkins
I'm recruiting PhD students excited about generative modeling, probabilistic inference, and scientific applications (biochemistry, physics, and more), with strong backgrounds in CS/Math/Stats/Basic Science and curiosity for advancing ML and solving real-world problems!
Apply to our Applied Mathematics and Statistics PhD program by Dec 15, 2025, and become part of the broader @HopkinsDSAI community!
https://t.co/2YJwqS4FzK
I’ll be at #NeurIPS2025 until 12/7!👋
Please reach out if you want to chat about RL, reasoning, self-evolving, or LLM diversity.
My Pre:
🌟 Fri, Dec 5 (11a-2p): Spotlight on Synthetic Data Scheduling, #4108
🌟 Sat, Dec 6 (11:30a & 4:30p): Spotlight on evaluating CoT, Hall F
I will be recruiting 1-2 PhD students at @NYUDataScience or @NYUCourant CS to work on Machine Learning & applications in NYU's vibrant top ML ecosystem. Check Google Scholar to see our latest research interests. Interested? Please mention my name in your application. Deadl. 12/12
🔥 NEW PAPER: What makes reasoning traces effective in LLMs? Spoiler: It's NOT length or self-checking. We found a simple graph metric that predicts accuracy better than anything else—and proved it causally. 🧵[1/n]
RL has led to amazing advances in reasoning domains with LLMs.
But why has it been so successful, and why does the length of the response increases during RL? In new work, we introduce a framework to provide conceptual and theoretical answers to these questions.
three years ago, DiT replaced the legacy unet with a transformer-based denoising backbone. we knew the bulky VAEs would be the next to go -- we just waited until we could do it right.
today, we introduce Representation Autoencoders (RAE).
>> Retire VAEs. Use RAEs. 👇(1/n)
Current GRPO wastes compute on negative groups — when all K samples are wrong, you get zero gradient despite full generation cost.
We propose a principled fix by bridging reward modeling and policy optimization:
👉 Penalize highly confident wrong answers more to create signal.🧵
@josancamon19@KempeLab@YaqiDuanPKU@jparag123@tonyjhartshorn Are you referring to the dynamic sampling in DAPO? In DAPO, they oversample and then filter out all the negative groups. In contrast, we aim to recover training signal from those discarded groups.
@siddarthv66 Prompt changes does affect eval. But both the baseline training and our method use the same eval setup - for fair comparison.
The experiments are run with university compute, so I wish I could run more. We are experimenting using LoRA to train.
@siddarthv66 It was for page limit so we put the Numina 1.5 in the appendix.
The eval challenge is mostly for Llama. The accuracy is <1% for AIME25. We do not want GSM or AMC because they're saturated. What else benchmark are there for math that is not contaminated?
@KempeLab@YaqiDuanPKU@jparag123@tonyjhartshorn@AIatMeta@NYUDataScience Key observation:
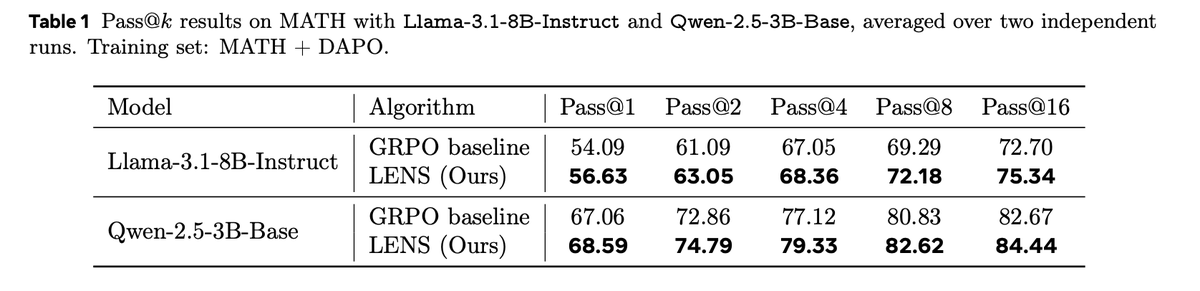
(1) Our method continues to improve accuracy when GRPO saturates ⬆️
(2) Our method improves all Pass@k metrics
This matches our intuition—by learning from negative groups, we get better exploration on hard problems where it matters most.
@KempeLab@YaqiDuanPKU@jparag123@tonyjhartshorn@AIatMeta@NYUDataScience We experiment on two different training sets with Llama-3.1-8B and Qwen-2.5-3B 📈
For MATH+DAPO, we run two random seeds. Our method consistently outperforms GRPO across training, with significant improvements on hard problems (Level 4-5)




















![feeelix_feng's tweet photo. 🔥 NEW PAPER: What makes reasoning traces effective in LLMs? Spoiler: It's NOT length or self-checking. We found a simple graph metric that predicts accuracy better than anything else—and proved it causally. 🧵[1/n] https://t.co/m7EY906Azm](https://pbs.twimg.com/media/G1lPOuuW0AAoty1.jpg)