Can a model learn to break its own reasoning plateau?
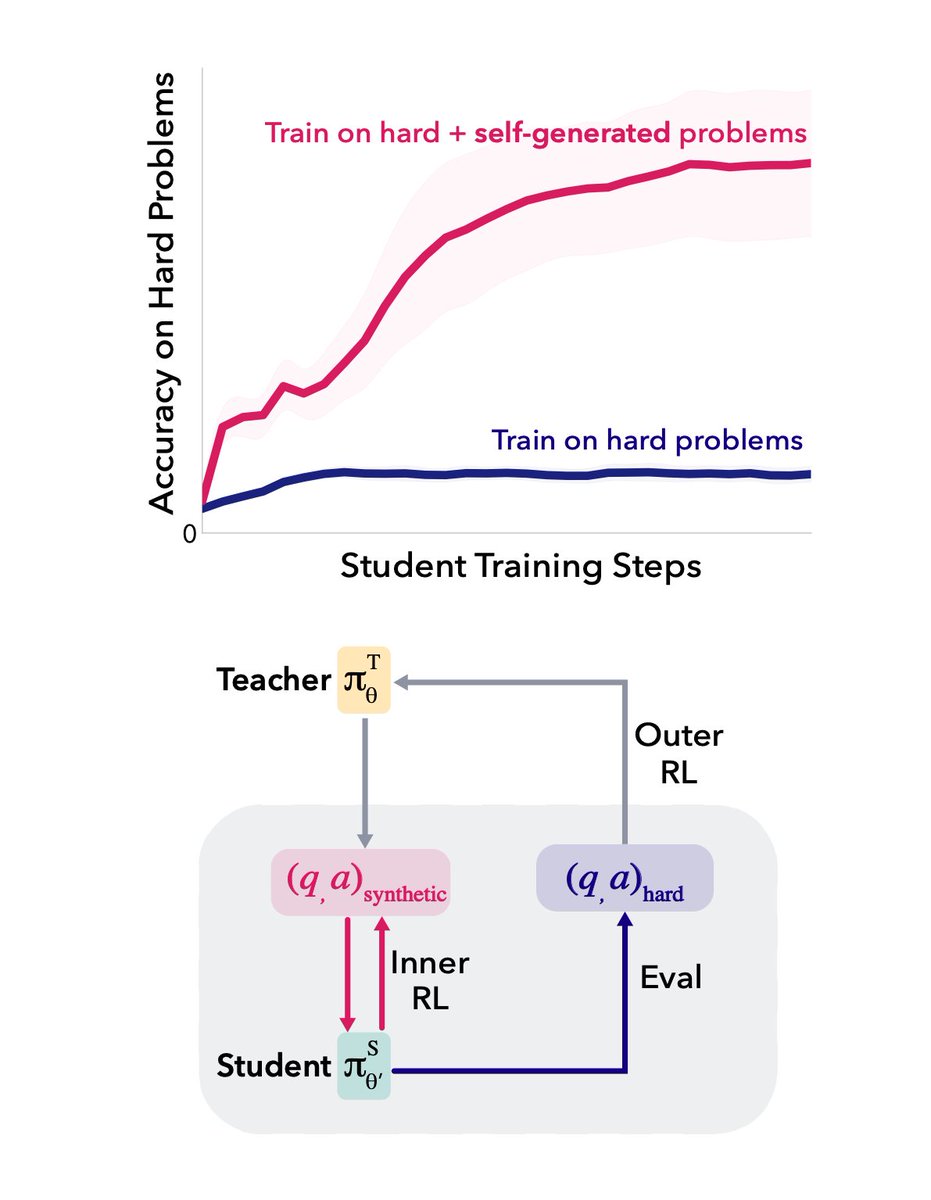
In our new paper, we show that LLMs can be taught with meta-RL to generate their own "stepping stones" that kickstart learning on hard math problems (0/128 success rate) where direct RL fails.
Paper 📝: https://t.co/lUlrJt6bwq
Blog post 🌐: https://t.co/v1y24h1fP4
(1/n)
Excited to share ID-Sim, our identity-focused similarity metric, presenting at #CVPR2026 this week in Denver! 🎉
Humans are remarkably good at distinguishing highly similar objects across different contexts.
We asked: can we train a metric that does the same?
Our team at @AIatMeta is excited to announce ATLAS: one of the largest automated formalization efforts to date.
ATLAS contains Lean 4 formalizations of both statements and proofs from 25+ mathematics textbooks, spanning dozens of domains, for a total of 500k lines of code. We are also releasing a flexible formalization harness and a companion paper.
External contributions are welcome!
Joint work spearheaded by our amazing PhD student Ahmad Rammal (@Ahmad3Rammal), together with Niket Patel (@niketnpatel ), Fabian Gloeckle (@FabianGloeckle), Amaury Hayat (@Amaury_Hayat), Remi Munos (@MunosRemi), Julia Kempe (@KempeLab), Vivien Cabannes, and myself from @AIatMeta, @NYUDataScience , and Ecole des Ponts. This is an ongoing effort; more details in the thread below.
(1/9)
What is the right data mix, and how do we find it as the data keeps changing?
This is a core, unsolved problem in continual learning. To tackle it, we built a data mixing algo that works everywhere — pretraining, midtraining, instruction tuning
Introducing: On-Policy Mix
🧵1/6
"The Truth Lies Somewhere in the Middle (of the Generated Tokens)"
In autoregressive language models, mean pooling hidden states across generation yields better representations than any token alone.
project page: https://t.co/kXddYUir4k
w/ @phillip_isola and @thisismyhat
@varchasvee_ Yeah it was a cool finding! We didn't explicitly try that, but we do have some new ablations (that'll be in the next arxiv version) showing that adding well-posed qs w/ incorrect answers to a pool of synthetic questions w/ correct answers still improves performance.
LLMs can learn to self-generate curricula for hard problems that they can't yet solve! Using meta-RL, with rewards grounded in learning progress, models produce their own stepping stones that kickstart learning on hard problems where direct RL plateaus.
Poster at the ICLR RSI workshop today!
Can a model learn to break its own reasoning plateau?
In our new paper, we show that LLMs can be taught with meta-RL to generate their own "stepping stones" that kickstart learning on hard math problems (0/128 success rate) where direct RL fails.
Paper 📝: https://t.co/lUlrJt6bwq
Blog post 🌐: https://t.co/v1y24h1fP4
(1/n)
New blogpost on tokenizing non-sequential data!
Language has sequential structure, which gave rise to the next-token prediction paradigm of LLMs. But we increasingly use LLMs for data without inherent order (e.g. images, molecules, sets). What does “next token” mean here?
(1/7)
Introducing GASP😮: Guided Asymmetric Self-Play for Coding LLMs
We address the goal-agnostic behavior of current asymmetric self-play methods. Key idea: guide the teacher with hard real-data goalposts; first an easier lemma, then a harder lift from the lemma as stepping stones
🧵
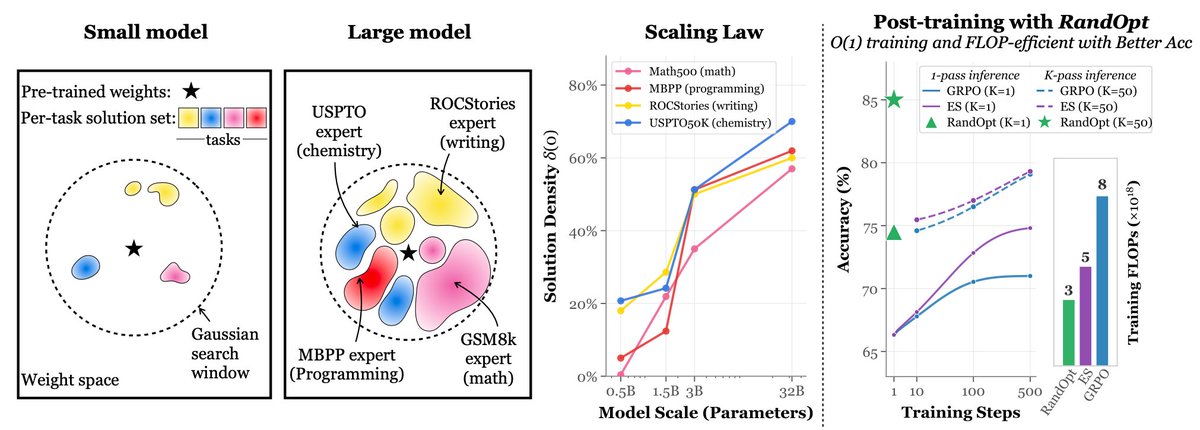
Simply adding Gaussian noise to LLMs (one step—no iterations, no learning rate, no gradients) and ensembling them can achieve performance comparable to or even better than standard GRPO/PPO on math reasoning, coding, writing, and chemistry tasks. We call this algorithm RandOpt.
To verify that this is not limited to specific models, we tested it on Qwen, Llama, OLMo3, and VLMs.
What's behind this? We find that in the Gaussian search neighborhood around pretrained LLMs, diverse task experts are densely distributed — a regime we term Neural Thickets.
Paper: https://t.co/rFJz2kVEOA
Code: https://t.co/HAmonfpXIA
Website: https://t.co/QZ6AMIsKCw
Can language models learn useful priors without ever seeing language?
We pre-pre-train transformers on neural cellular automata — fully synthetic, zero language. This improves language modeling by up to 6%, speeds up convergence by 40%, and strengthens downstream reasoning.
Surprisingly, it even beats pre-pre-training on natural text!
Blog: https://t.co/Pni0RsIcxL
(1/n)
[1/n] Do distinct large models admit a simple map that aligns their embedding spaces? We show that across multimodal contrastive models—trained on different data and architectures—an orthogonal map aligns image embeddings. Strikingly, the same map also aligns text embeddings.
Targeted instruction tuning for LLMs involves selecting a subset of instructions from a candidate pool using a small query set from target tasks. Despite growing interest, we still lack guidance on what to select. Our new preprint brings clarity to this space (thread 👇).
CDS/Courant Prof @KempeLab has recorded two talks with the Physics of Learning and Neural Computation, a Simons collaboration.
She discussed how RL post-training shapes LLM reasoning but may hit ceilings like diversity collapse and low sample efficiency.
https://t.co/7H5dQHYWzR
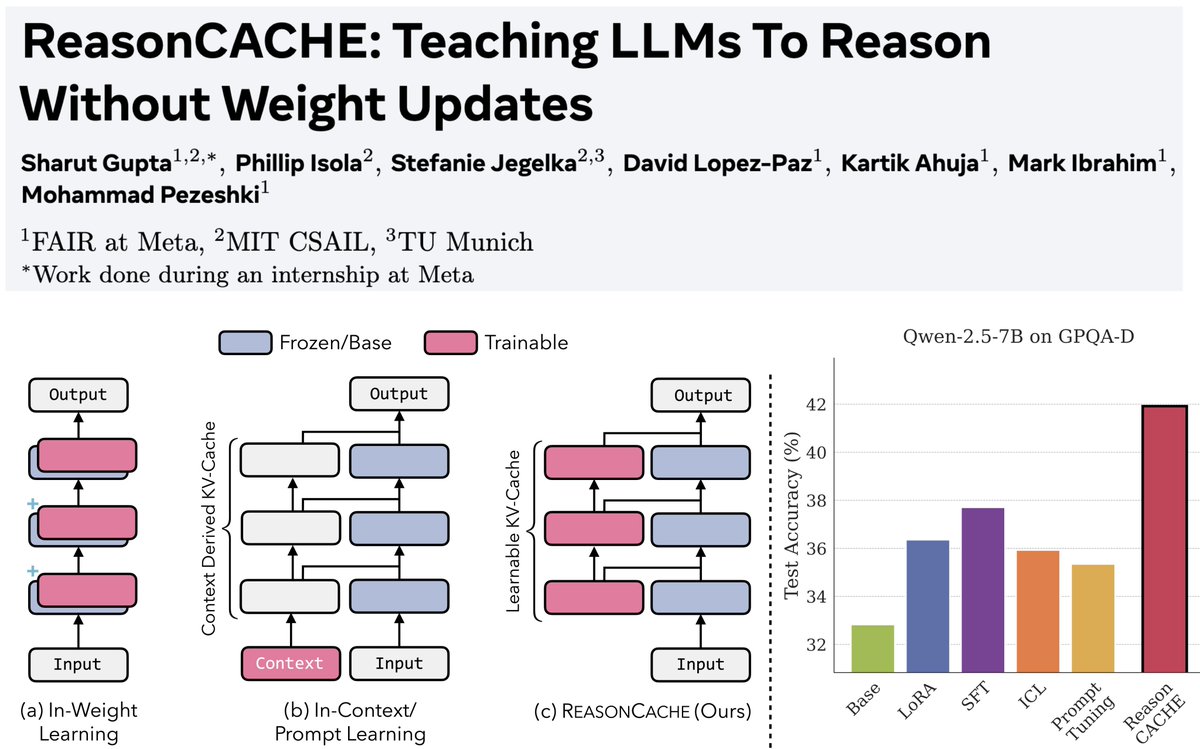
1/n Can LLMs learn to reason on hard benchmarks like AIME and GPQA purely through context, without SFT, RL, or any weight updates?
Turns out… Yes! And it can have strong performance while being highly efficient
Paper: https://t.co/mEoaIst6cX
Blog: https://t.co/lZli7qY4Jz
Another nice work with student-teacher setup, but this time with meta learning setup: teacher generates q/a pairs for student, and gets reward depending on student's improvement after training on those qa.
@inventcures@karpathy@paraschopra@tokenbender@o_v_shake Thanks! Yeah these ideas around making data/tasks more model-learnable were definitely an inspiration! In our case we have the model discover those tasks for itself based on what gives the best learning signal.