The Platonic Representation Hypothesis
https://t.co/eoz1GTBEiU
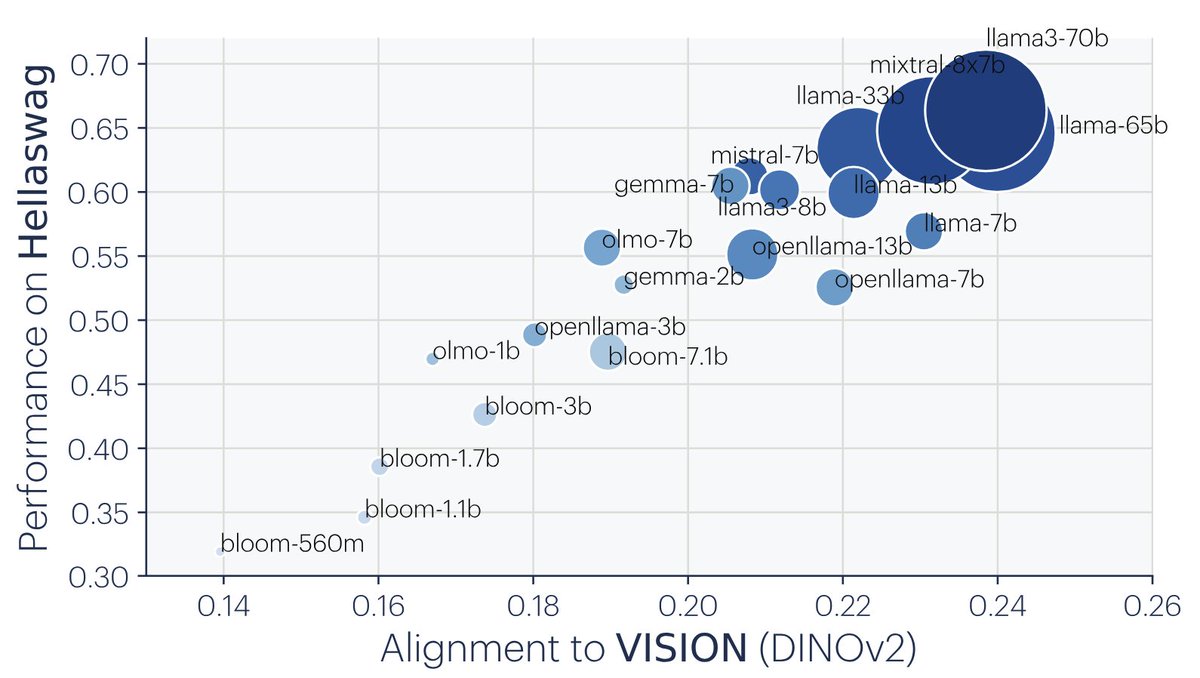
Surprising (?) results:
- Pure vision models align with pure text models as scale increases.
- This alignment correlates with better downstream performance.
Fun work with @minyoung_huh@TongzhouWang@phillip_isola
"The Truth Lies Somewhere in the Middle (of the Generated Tokens)"
In autoregressive language models, mean pooling hidden states across generation yields better representations than any token alone.
project page: https://t.co/kXddYUir4k
w/ @phillip_isola and @thisismyhat
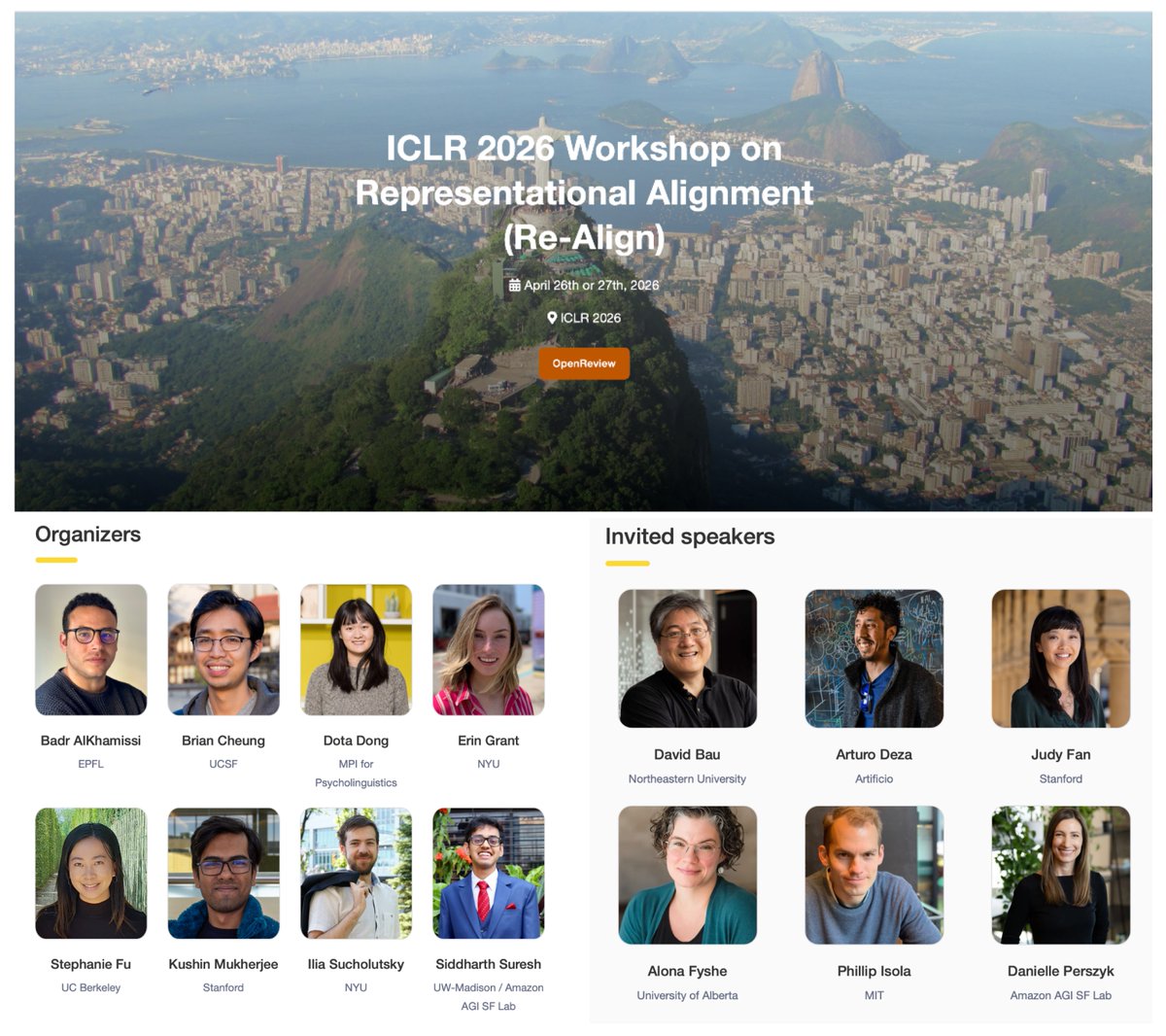
🎉 Re-Align is back for its 4th edition at ICLR 2026!
📣 We invite submissions on representational alignment, spanning ML, Neuroscience, CogSci, and related fields.
📝 Tracks: Short (≤5p), Long (≤10p), Challenge (blog)
⏰ Feb 5, 2026 for papers
🔗 https://t.co/BEtKUM9oQP
Software agents can self-improve via self-play RL
Introducing Self-play SWE-RL (SSR): training a single LLM agent to self-play between bug-injection and bug-repair, grounded in real-world repositories, no human-labeled issues or tests. 🧵
👁️🌋 Our new @ScienceAdvances paper: We replayed the Cambrian explosion of vision by evolving AI agents inside a physics engine to understand the principles that shape visual intelligence.
We believe that this is a promising way to do AI for science and build new forms of AI by computationally mimicking biological design principles of evolution and learning.
Website: https://t.co/xd1Hkt8bvs and paper links at the end of this thread 👇
We discovered an emergent property of VLAs like π0/π0.5/π0.6: as we scale up pre-training, the model learns to align human videos and robot data!
This gives us a simple way to leverage human videos. Once π0.5 knows how to control robots, it can naturally learn from human video.
This also shows up in the representations learned by the model. We plot the model’s representations of human and robot images. As pre-training is scaled up, the representation of humans and robots become more aligned: to a scaled-up model, human videos "look" like robot demos.
@chris_j_paxton Data is just information. There's always something to learn from data, maybe not what you need right now. But can become important later.
@JieWang_ZJUI The human data was originally out of domain and unusable becomes useful after a certain scale of model capability https://t.co/wIa62hyNG5
This also shows up in the representations learned by the model. We plot the model’s representations of human and robot images. As pre-training is scaled up, the representation of humans and robots become more aligned: to a scaled-up model, human videos "look" like robot demos.
Impromptu NeurIPS meetup: "representational convergence by the beach." We will meet at ballroom 20c (near lunch) 2pm Fri and walk over to Marina. Will chat about platonic reps, fractured reps, or anything else about where all these models are heading.
Anyone is welcome to join!
This paper is really interesting to me -- it shows substantially stronger representational convergence than previously measured!
In the PRH we found ~0.2 mknn alignment between vision and text models. This new paper reaches ~0.4. Challenge: find a setting where it reaches ~1.0.
Sakana AI’s CTO says he’s ‘absolutely sick’ of transformers, the tech that powers every major AI model
“You should only do the research that wouldn’t happen if you weren’t doing it.” (@thisismyhat) 🧠
@YesThisIsLion
https://t.co/cGdHONcqDV
Over the past year, my lab has been working on fleshing out theory/applications of the Platonic Representation Hypothesis.
Today I want to share two new works on this topic:
Eliciting higher alignment: https://t.co/KY4fjNeCBd
Unpaired rep learning: https://t.co/vJTMoyJj5J
1/9
So going back to the original takeaway, much like what @sama, @ericjang11, and @noampomsky have said in the past:
You can just ask for things.
Something interesting might happen.
Paper: https://t.co/4bgbJagRH3
Code: https://t.co/VylkC7oOg8
Website: https://t.co/GG6F8fLIIm
3/3
A takeaway I learned from LLMs:
You can just ask for things.
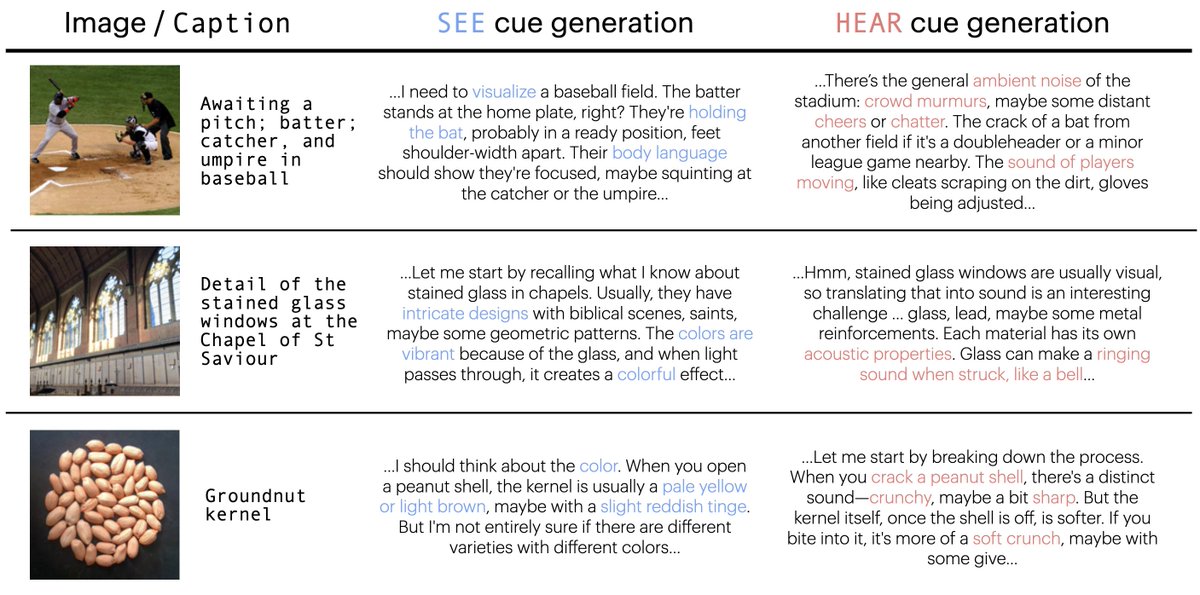
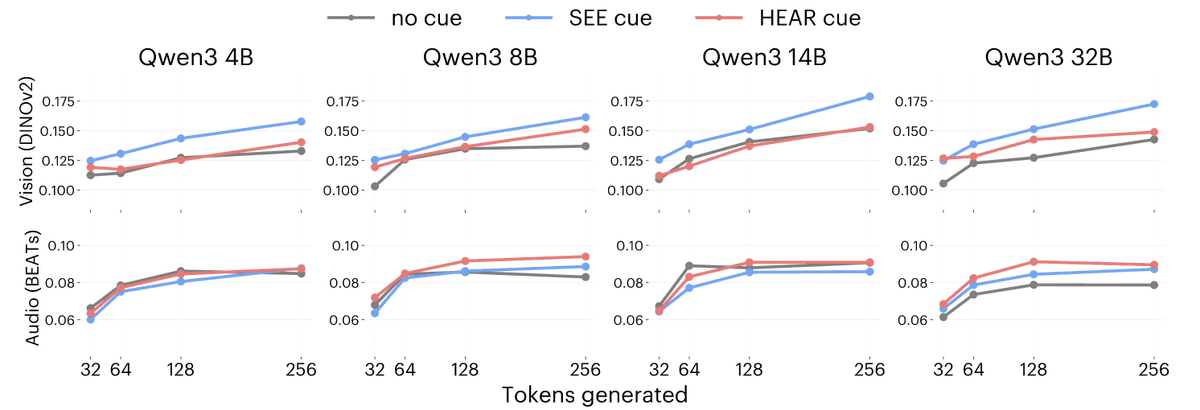
What if you asked a language model to imagine senses it never experienced?
@SophieLWang , @phillip_isola and I asked language models to "Imagine seeing..." and "Imagine hearing...".
1/3
It turns out, a simple cue like asking the model to ‘see’ or ‘hear’ can push a purely text-trained language model
towards the representations of purely image-trained or purely-audio trained encoders.
2/3