Biotech R&D is generating more scientific AI models than ever, from protein structure prediction to molecular docking to sequence analysis. But the infrastructure to run them hasn't kept up.
Today we're announcing Benchling Inference, powered by Baseten. Together with @benchling, we're delivering on-demand GPU capacity built for the bursty, high-stakes demands of scientific workloads. With Benchling Inference, scientists can:
→ Deploy models in seconds, not weeks
→ Keep proprietary models inside their VPC if needed
→ Benefit from economics that work even at small and mid-size biotech scale
Benchling and Baseten decided to team up because we believe that research teams shouldn't have to manage HPC queues, negotiate cloud contracts, or become GPU experts to run frontier models on their own data.
Six years of inference expertise are now available where science happens.
Read more here: https://t.co/vqmtnXnAT1
@bluequbit Pretty cool! Index select will cost ~1% overhead. I found if you are using decent kernels (e.g. https://t.co/ikew6Jt23L or torch.index_select on recent torch versions), it works well.
OpenAI is shutting down text-embedding-3-small?!?
I strongly believe that if you shut down a closed-source embedding model that you should open-source. Imaging the trillions of tokens that will no longer be queryable.
cc @romainhuet
We are excited to have @baseten as a day 0 launch partner for Kimi K2.6!
Their inference stack brings KV-aware routing, NVFP4 on Blackwell, multi-modal hierarchical caching, and prefill-decode disaggregation, so K2.6 runs the way it's meant to in production.
Try it out at: https://t.co/ol3lIkaH6m
Named Entity Recognition is a core workload used by Search and Healthcare companies to filter queries and anonymize queries.
We shipped the fastest inference on the market: 1 ms P50 and 3 ms P99 server-side latency, 7.7x faster than an optimized PyTorch baseline, fixing several bottenecks: HTTP parsing, networking, load-balancing.
Over 1 million clinical questions hit OpenEvidence every day. More than half the practicing physicians in the US rely on us at the point of care, mid-decision, with a patient in front of them. Downtime in that moment has real consequences.
We partner with @baseten for our inference infrastructure to make sure answers are always there when physicians need them. They stopped by our office to talk about what that looks like under the hood.
@art_zucker Making the token+position a u64 is a good idea for lookups, e.g. I did this also a couple of times. https://t.co/A9YSOTpVCc
I cross compiled the package from the blog post, so `pip install fastokens-b10` is a thing.
Really good blog by the dynamo and crusoe team. https://t.co/0DwEXFdoP0. tl;dr: Ported some of the learnings back to hf/tokenizers. https://t.co/5ks163ScKX https://t.co/im9XSO0aaJ at the scale of transformers, will save probably save M$ if done right. @art_zucker.
As result current engines wastes around 5 to 500% in prefill performance during inference and training, when using shared prefixes.
implementation: https://t.co/53lC6Wl4kd
paper: https://t.co/jMVTMwgskl
tldr: We open-source a inference engine that deduplicates prefill tokens and wrote a paper (@juliuslipp).
RadixMLP was missed chance by the community that developed varlen (THD-packed) inference, and overlooked by people working on training and inference engines.
[1/x]
Introducing RadixMLP: intra-batch prefix deduplication for 1.4–5x faster prefill.
Tokens with identical prefixes (like system prompts or shared queries) produce identical activations. @feilsystem developed RadixMLP to eliminate this redundancy, then open-sourced it and added it to TEI and BEI.
https://t.co/LFBJ2RsVzp
Turns out that all engines do just prefill multiple requests, at the same time, even when prefixes are shared. KV-style caching for training systems is possible, it just needs to look different to a vllm-style paged kv-cache.
[2/x]
Introducing Kimi K2.5 on Baseten’s Model APIs with the most performant TTFT (0.26 sec) and TPS (340) on Artificial Analysis.
Even among a landscape of incredible open source models, Kimi K2.5 stands out with its multi-modal capabilities and it's ability to accommodate an alarmingly large number of tool calls.
Get the good stuff here: https://t.co/X1yWULgvjM
If you need an adrenaline rush to wake up from your post-Thanksgiving stupor… we got you.
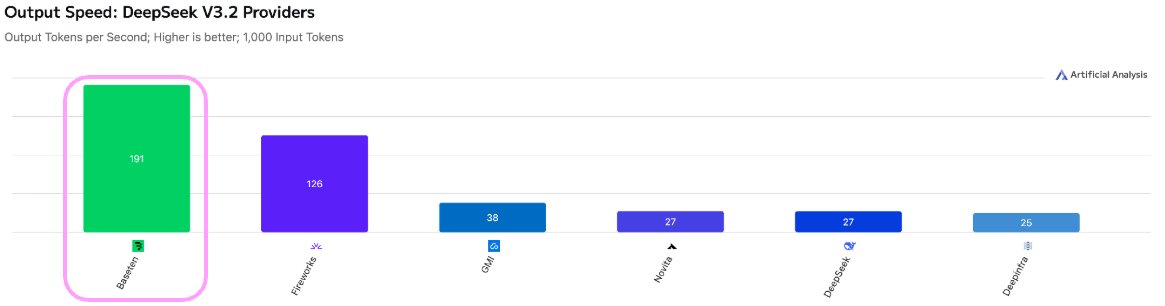
@deepseek_ai V3.2 dropped this week and is now available on Baseten. It’s so smart your mother will ask why you can't be more like DeepSeek. V3.2 is currently on par with GPT-5 all whilst being multiples cheaper.
V3.2 is now live on our Model APIs and on @openrouter and @ArtificialAnlys. Baseten is the fastest provider with 0.22 TTFT and 191 tps (that’s 1.5x faster than the next guy). For a model this size, it’s screaming. Get the brains, without trading off performance.