Microsoft cancelando licencias de Claude Code, Uber ha gastado en 4 meses el presupuesto de IA de todo el año. Los precios de IA subiendo hasta un 40%...
Muchas empresas adoptaron IA pensando que los costes seguirían bajado pero ha pasado lo contrario.
Los números no cuadran y alguien tendrá que asumir las pérdidas... Creo que los modelos locales van a asumir más protagonismo.
Personal update: I've joined Anthropic. I think the next few years at the frontier of LLMs will be especially formative. I am very excited to join the team here and get back to R&D. I remain deeply passionate about education and plan to resume my work on it in time.
Obsidian is weird:
- 7 full-time employees
- ~1 million users per employee
- fully remote
- 1 in-person meetup per year
- no scheduled meetings
- no stand-ups
- deep focus is prioritized
- our manifesto guides our product
What works for us may not work for you.
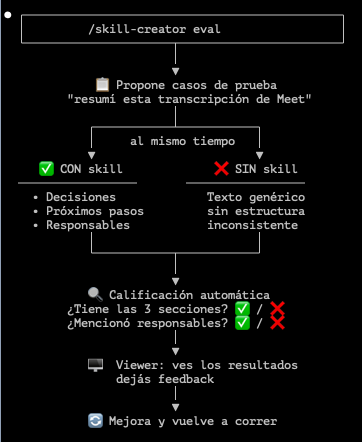
Hace poco Anthropic lanzó una nueva forma de testear Skills en Claude Code:
Evals.
Por ejemplo: creaste una skill para que Claude Code resuma transcripciones de Google Meet. Y siempre querés que siga esta estructura:
decisiones → próximos pasos → responsables
Llamás a /skill-creator (skill oficial de Anthropic) y le decís: “quiero testear mi skill”.
Entonces:
1) Lee tu skill y entiende qué tiene que hacer.
2) Te propone casos de prueba.
3) Lanza dos agentes en paralelo: uno con la skill y otro sin. Ambos reciben la misma transcripción de Google Meet.
4) Califica los resultados: ¿tiene las 3 secciones? ¿menciona decisiones, próximos pasos y responsables?
5) Genera un HTML con los resultados. Comparás output con skill vs sin skill y dejás feedback.
6) Mejora y repite: reescribe las instrucciones con tu feedback y vuelve a correr.
Muy útil cuando querés que una skill devuelva siempre el mismo tipo de output.
Not knowing how to code giving you an advantage is absolute nonsense.
The more you understand, the better your prompts, the better the feedback you give, the better product you ship.
What will change is that the intricacies of syntax, compilers, module systems, the finer details of type systems, won’t matter as much to everyone.
But you should absolutely understand how the pieces fit together. From syscall to pixels. Learn how data flows, because you’ll be able to secure your systems. Learn about performance, because you’ll be able to push your agent further. Learn about APIs, because they determine how to integrate systems. Learn about how systems fail, because you’ll be able to make reliable programs.
Lectura para el fin de semana: “La guía completa de para construir SKILLs para Claude”
Es una guía oficial de @claudeai con muchísimos detalles e instrucciones para tener tu AI setup al 100 y construir SKILLs efectivos para tu día a día
Y es gratis
lean este artículo si quieren entender cómo se diseñan los agentes.
cuenta lo que aprendieron construyendo Claude Code durante 1 año.
lo más difícil fue definir el action space:
qué puede hacer el agente y cómo interactúa con su entorno.
me quedo con estos 3 puntos:
1) elicitation: crearon una tool (askUserQuestion) para que el modelo haga mejores preguntas.
ej: antes de implementar un endpoint, te muestra opciones y te pide confirmar cuál usar.
2) sistema de búsqueda: pasaron de inyectar contexto con rag a darle tools como search para que el modelo encuentre lo que necesita en el código.
ej: busca dónde se define una función y abre ese archivo.
3) progressive disclosure: el agente descubre la información paso a paso, en lugar de cargar todo desde el inicio.
ej: lee un archivo, encuentra una referencia y abre el siguiente.
las tecnologías de hoy se están construyendo sobre agentes, skills y tools.
vale la pena dedicarles tiempo, estudiarlos y entender cómo funcionan.
ahí está la base de lo que viene.
Peter Steinberger is joining OpenAI to drive the next generation of personal agents. He is a genius with a lot of amazing ideas about the future of very smart agents interacting with each other to do very useful things for people. We expect this will quickly become core to our product offerings.
OpenClaw will live in a foundation as an open source project that OpenAI will continue to support. The future is going to be extremely multi-agent and it's important to us to support open source as part of that.
Aparentemente algunos de los mejores ingenieros en Spotify ya no escriben líneas de código, solo usan AI.
Yo he visto algunos ejemplos de proyectos reales y el factor común es que tienen todo lo necesario para
- Entender el código perfectamente ( contexto)
- Hacer pruebas de calidad
- Probar cambios en tiempo real
- Sistema de review adaptado al uso de AI
- Otro mindset para trabajar
No sé si Spotify tiene eso y m��s, pero si es así mis respetos porque no es tan sencillo cambiar tu flujo de trabajo de esa manera
La misma página, el mismo backend y el mismo código.
Aun así, un usuario en Australia la ve en 80 ms (milisegundos) y uno en India espera 600 ms.
¿Por qué?
Cada vez que abrís una página, tu navegador le pide los datos a un servidor físico que está en un lugar concreto del mundo. Ese pedido tiene que viajar hasta el servidor y volver.
En este caso:
- El usuario en Australia habla con un servidor cercano → el viaje es corto → 80 ms
- El usuario en India habla con un servidor lejano → el viaje es largo → 600 ms
Ese tiempo de viaje es latencia de red.
El backend puede ser muy rápido, pero si la request tiene que cruzar medio planeta, el usuario igual lo siente lento.
Por eso dos personas, usando la misma app, pueden tener experiencias tan distintas.
¿Cómo se soluciona?
Con un CDN (Content Delivery Network).
Un CDN guarda copias del contenido en servidores repartidos por el mundo. Así, cada usuario habla con un servidor cercano a su ubicación.
En el ejemplo:
- Australia → servidor en Australia
- India → servidor en India
La app es la misma.
El código es el mismo.
Lo único que cambia es la distancia que tiene que recorrer la request.
En el trabajo estoy aprendiendo bastante sobre logs y la forma correcta de usarlos. Encontré este página muy interesante: https://t.co/V9ZIgRsapf. Se las resumo (así nomás):
Loggear viene de tiempos arcaicos, entornos en lo que una request generaba una sola línea de log.
Si tu app no tiene rate limiting, está expuesta.
Un rate limiter define cuántas veces alguien puede interactuar con tu app en un período de tiempo.
Ejemplos simples:
• 3 sign-ups por minuto
• 2 uploads de archivos por minuto
Podés aplicarlo por User ID o IP.
Si un user (ID: 5) ya hizo 3 sign-ups en 1 minuto, el servidor responde con un 429 (Too Many Requests) y corta el flujo.
Es clave porque:
• protege endpoints sensibles como signup o pagos
• evita saturación y caídas
• cuida recursos caros como APIs externas o modelos de IA
¿Qué puede pasar si no lo tenés?
- Un bot automatiza miles de sign-ups por minuto y te llena la base de datos de usuarios falsos.
- Un script pega a un endpoint de IA en loop y te consume los tokens en minutos.
- Un atacante dispara miles de requests por segundo contra un endpoint público, satura el backend y deja la app fuera de servicio (DDoS).
Lo podés implementar fácil con Cloudflare o Nginx.
La seguridad también se diseña.
Cuiden sus apps (: