Congrats to @IonQ_Inc, the first public pure-play quantum computing company! Honored and grateful to be part of the journey as an investor. #QuantumComputing $IONQ
Some time ago, I had the idea to port NVIDIA Physical AI stack to AMD. The motivation was to improve hardware diversity and enable world models and VLAs to run beyond a single ecosystem.
We started with NVIDIA Cosmos Predict 2.5-2B. Porting wasn’t trivial: these models are deeply optimized for NVIDIA’s stack. We used this as an opportunity to apply our ROCm kernels.
The results were surprising:
Both encode and diffusion run faster on AMD Instinct MI300X vs. NVIDIA H200 (FA3) and we still saw significant headroom for further optimization.
Quality is unchanged across modalities (validated with WorldJen)
To be clear, this is no luck. We have deep experience with diffusion models and AMD GPUs. But this just gives us a good opportunity to get closer to a true hardware-to-hardware comparison, as we work with less software abstractions than usual. Just to give an example, on AMD, memory instructions are async with a hardware queue of ordered pending instructions, enabling concurrent load/store with compute without warp specialization. Bottom line: there are real architectural advantages on AMD, if you take the time to work with the hardware.
Note, we did tradeoff ~20% higher memory usage,
That being said, AMD has more to give to begin with :)
in the coming weeks:
AMD versions of Cosmos Transfer and GR00T, an even faster version of Cosmos Predict, and open-sourcing an attention kernel faster than AITER v3 (which is closed-source for some reason? cc: @AnushElangovan )
Introducing BackLite: Attention Backpropagation Acceleration Using Dynamic Sparsity 👀
👊Blog post: https://t.co/etn2Ou2KIk
👊Code (open source!) : https://t.co/E1t0tAjpJs
👊Integration example to nanochat: https://t.co/ovb5Sm9puR
It is well known that the attention matrix is highly sparse. Several works have used this sparsity to speed up the forward pass. What if we could also use it to speed up the backward pass?
BackLite is a novel algorithm designed to dynamically discover and exploit the sparsity inherent in attention to skip computation while mathematically approximating the gradients through the attention layer.
Our idea:
Simply track the sparsity in the attention matrix during the forward pass and use it to skip computation during the backward pass.
Under the hood:
🌊 Uses the forward pass to track attention matrix tile weights at negligible overhead
🌊 Builds a mask by skipping tiles with cumulative weight less than a threshold
🌊 Skips masked tiles during backward
👉 Same forward, same model, fewer backward FLOPs
Drop-in kernel replacement, tested on LLMs and video diffusion models, especially good for long sequence lengths 💪
Disclaimers:
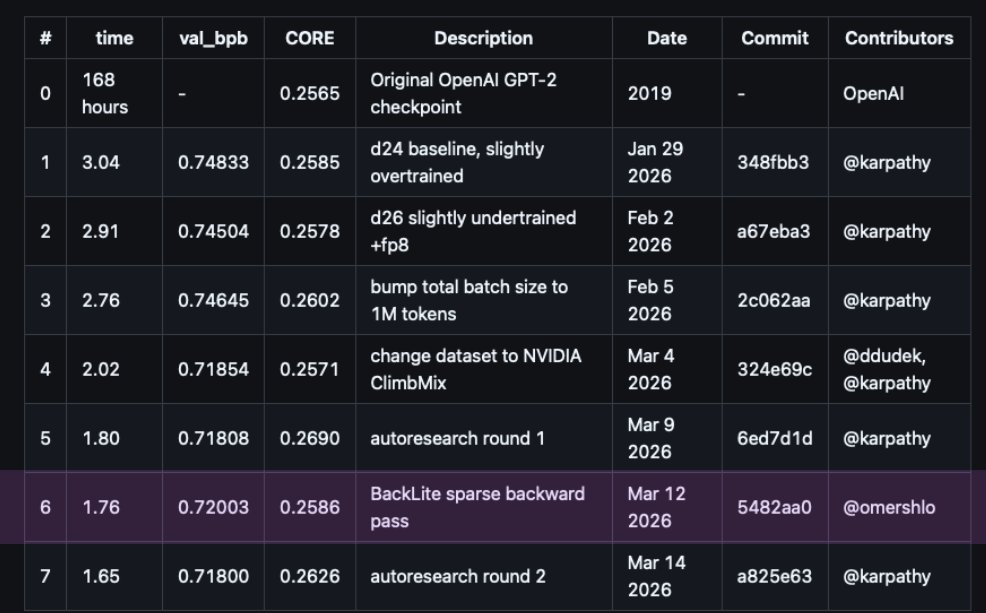
Image shows nanochat leaderboard *IF* @karpathy/ @OxyKodit will merge our PR.
Yes, there's still much work to do on the code and tests to run. Contributions/questions are welcome.
Publication Update: ICICLE is heading to ICLR!
Our work on Provable Watermark Extraction has been accepted to the first GenAI Watermarking Workshop: https://t.co/MeJ6EoLQCs
zkDL++ ensures watermark provability while preserving extractor privacy, advancing practical AI security.
🔗 Read our technical blog: https://t.co/8m3OdsjF2I
📄 Full paper coming soon.
Stunned that after 40 years, Montgomery multiplication just got faster! @yuval_domb's reduction from n²+n to n²+1 digit multiplications might seem like a small change, but at scale this transforms cryptographic performance. These fundamental algorithmic improvements remind us that even "settled" math still holds hidden efficiencies.
Big up @Ingo_zk
Barrett-Montgomery modular reduction, reimagined.
A novel multi-precision algorithm that reduces computational complexity from n² + n to n² + 1 digit multiplications—significantly boosting performance in key primitives like NTT.
Groundbreaking work by @yuval_domb.
Read the full technical note: 🔗 https://t.co/gRTkhbCfKU
Imagine hiring a lawyer based on just attributes plus benchmark data. Cleary doesn't work. Instead, we combine with an evaluation of past experience & performance in similar situations. Critical job or role ==> need more real world history/longer resume. (2/2)
#AI#Enterprise
As AI takes on more complex tasks, "tasks" will be replaced by "jobs" & "roles". This means that how we assess the AI will become closer to how we evaluate people. Which means: evaluate past experience & performance in similar situations in the real world. (1/2)
#AI#Enterprise
I'll be speaking on a panel focused on AI and Medicine, at the Taiwan Science and Technology Hub@Stanford Annual Conference tomorrow.
https://t.co/dqgPPOJNXv
#AI#medicine#biotech
Today, we announced an agreement with @bearingpoint - a leading European management and technology consulting firm with offices in 24 countries - to offer IonQ quantum system access and professional services to clients across Europe.
BearingPoint consultants can now propose use cases and solutions for public and private groups that leverage the power of IonQ’s systems, helping them formulate positions on the rapidly evolving technology.
Read more: https://t.co/KJ2Zac4JAc
Why AI + ZK lets us amplify our communications with the power of generative AI while maintaining trust/privacy/authenticity via the power of zero knowledge. Nicely meta in its use of AI to communicate this. And more efficient ZK computation will be a foundational enabler.
Presenting The ZK Movie 🎬
Dive in and experience some AI magic 🧙♂️
Behind the Scenes Blogpost 👇
https://t.co/4W0nbZylxv
Ingonyama #YouTube channel 👇
https://t.co/bbVzEPtyIx
#AI#zk#shortfilm#Video#film#shorts
Great first day at #2023quantumkorea ! IonQ Co-founder Jungsang Kim spoke about our roadmap for growth and market leadership, and shared our vision for the future of #quantumcomputing.
If you are attending, make sure to stop by our booth in Art Hall 2 and say hello!
#quantum
🛎️#Ingopedia V3 is now LIVE on our website! 🚀
🔹Opensource
🔹Community-driven
🔹Contributions welcome
It's your opportunity to share anything that can help the Zero-Knowledge community
Website: https://t.co/Wv7onn3k3q
Github: https://t.co/5ElSmpZZfM
#ZKP#opensource
Introducing: 🔥Blaze🔥
A @rustlang Library for ZK Acceleration on FPGA 🥳🥳
TL;DR:
Blaze makes #FPGA integration into your #ZK project seamless and easy
With Blaze, any engineer can instantly start working with FPGAs! 🙌
Integrate our FPGA in @awscloud F1, or your own
🧵1/
Join @fho888 at Commercialising Quantum Global taking place on May 17th – 18th 2023 organised by @economistimpact. From qubits to profits: achieving near-term quantum advantage. Find out more & register here >>
https://t.co/ZaQuG05P97 #EconQuantum#Quantum@EconomistEvents
1/6: We are excited to share IonQ’s President and CEO, Peter Chapman’s, letter to stockholders. We are on track to achieve #AQ 35 which, for the first time, exceeds the capacity of quantum simulators on classical hardware
Big for zk acceleration as well 💪🏻
https://t.co/2T75eLYoGd
“the Chrome team ships WebGPU which allows high-performance 3D graphics and data-parallel computation on the web”