Memory cycle topping indicator: demand is so strong and supply so scarce that buyers (ahem, Jensen) fly into Seoul to plead for allocation.
Happened in 1995, now in 2026. Chimaek and chill. Only thing is the party went on for another half decade.
Dylan Patel @dylan522p said the biggest models won't fit on Cerebras $CBRS.
Andrew Feldman's @andrewdfeldman rebuttal: he ran a trillion-parameter model faster than any GPU cloud and called the doubters "empirically proven dead wrong."
Dylan Patel on the biggest risk for $CBRS:
"The big risk for Cerebras is, I mostly think the best models are the ones you want to use fast mode on, and small models you might not necessarily use fast mode on. I could see that being wrong with financial markets, maybe, a Jane Street high-frequency or medium-frequency trading. But ultimately, running really large models at really long context is very difficult on SRAM-based chips like Cerebras, like Groq. So what happens if the models get too big? If OpenAI's model is not on the order of hundreds of billions of parameters, or low trillions, but is actually 10-plus trillion parameters, all of a sudden I don't think that will fit on Cerebras. And then if that's with a long context length, a million context length, now that makes it really difficult."
Wow so this $NVDA video went private but I caught the screenshots if anyone curious.
They can clearly build a Mythos-grade, open-source model whenever they want.
This particular example was Nemotron 3 Super (120bn parameter) built on a few thousand GPUs but the way the team talked about it was almost a throwaway line at the end. They've since moved onto bigger and better things, Ultra (500bn), so this isn't really a question of capability.
Incredible there's a video out there with <100 views of the $NVDA team talking about their GPU fleet and casually training their open source models with a few thousand GPUs. Nothing lifechanging but not <100 view uninteresting. Subscribe (see bio) for more info.
Dylan Patel on the biggest risk for $CBRS:
"The big risk for Cerebras is, I mostly think the best models are the ones you want to use fast mode on, and small models you might not necessarily use fast mode on. I could see that being wrong with financial markets, maybe, a Jane Street high-frequency or medium-frequency trading. But ultimately, running really large models at really long context is very difficult on SRAM-based chips like Cerebras, like Groq. So what happens if the models get too big? If OpenAI's model is not on the order of hundreds of billions of parameters, or low trillions, but is actually 10-plus trillion parameters, all of a sudden I don't think that will fit on Cerebras. And then if that's with a long context length, a million context length, now that makes it really difficult."
A bankrupt chip maker nobody wanted sold for $3 billion in 2011. Today SK Hynix is worth ~$1T, at a margin higher than $NVDA's.
The buyer bet on one memory chip through a decade of losses. Samsung gave up on that same chip, and Micron $MU backed the rival standard that lost. It became the most valuable part in an AI system.
Part II of the Memory Wars: how the perennial runner-up took the throne, and why the lead is already narrowing. Link in bio.
The cost of answering a question is falling toward the cost of electricity. When Aravind of @perplexity_ai walks Joe Rogan through what that reroutes, it runs from Google's search moat to the power grid to a box in your living room. Ideas worth thinking through:
1/ The whole AI industry is reactive, and nobody five years out saw today coming. Srinivas argues the proof is behavioral rather than rhetorical: if any frontier decision-maker in 2021 had actually predicted 2026, they would have pre-bought the compute, manufactured the chips, cornered the fabs, and permitted the power. None did, which is why everyone is now bottlenecked on chips and power at once. He extends the humility to his own forecasting, saying he cannot call even five years out, let alone the 250-year question Rogan kept pressing. The read for anyone modeling this: capacity is being built into demand that already exists, so the shortage is structural rather than a planning miss that gets corrected next cycle.
2/ Power is the bottleneck, and Jensen Huang said the same thing on this couch. Asked what constrains AI today, Srinivas says everyone in the field gives one answer, power, and notes Jensen Huang gave Rogan that identical answer in an earlier episode. The framing decides where the money flows next: the binding constraint is megawatts and the chips that draw them, ahead of model cleverness or talent. That puts the marginal dollar on generation, grid, and fab capacity rather than on another wrapper app. Srinivas ties it to his 2028 call later in the conversation, that the energy crisis around AI becomes a mainstream political fight once the power draw is visible in everyone's life.
3/ When cognition costs what compute costs, value migrates to the scarce question. Srinivas's central idea: if the price of cognition collapses to the price of compute, then managing an AI is itself doable by an AI, because supervision stops being a uniquely human capability. So value flows to whatever stays scarce, and what has always been scarce is asking high-quality questions. He generalizes it into a labor thesis, that once AI turns today's scarce knowledge work into a commodity, humans have to move to what is not yet known or done, which only curiosity uncovers. It is the same move investors make when a factor gets arbitraged away: reprice toward the input that is still constrained.
4/ The fix for centralized AI power is local AI you own. Srinivas frames the danger as an asymmetry: centralized companies hold enormous AI power and the individual holds almost none, which is how curated search results can shape perceptions and elections, citing Robert Epstein's work. His counterweight is ownership, giving people their own models running on hardware they control, so no one can shut off access or quietly shape what they see. He calls this the coming rise of local AIs. The investable edge sits with whoever supplies that hardware and the open-source models that run on it, a different pool of winners than the centralized-cloud incumbents he is describing as the problem.
5/ In a year or two, data-center capability runs in a box on your counter. Srinivas puts a timeline on local AI: within one to two years, whatever needs the most power-hungry data center today will run on a box you own, and it is already starting with the Apple Mac Mini and Nvidia DGX hosting a reasonable-size model. You plug it into power and stop paying per token. He expects a hybrid phase first, some percentage of tasks delegated locally while the rest stay in the cloud until local capability catches up. The endpoint he describes is an AI box that feels like a refrigerator in the home. He names Apple, Nvidia, and Intel as doing the work, and insists it need not be as expensive as people assume.
6/ You keep the app, but move the compute you control underneath it. Pressed on why a normal user should care, Srinivas gives the concrete version for Perplexity: the models running the app today all sit in the cloud, but eventually you keep the same front end and UI while controlling the compute on hardware you own. The scenarios he reaches for are hard shutoff cases, a government deciding a model is no longer available, or data centers being physically hit, referencing Iran bombing data centers. The business implication is a product architecture that decouples the interface a company owns from the inference a user can increasingly host, which is a very different unit economics story than pure cloud subscription.
7/ Rogan already defaults to Perplexity over Google, and one concrete friction explains why. Rogan describes his own behavior as the demand-side proof: when he wants an answer he asks Perplexity rather than sifting Google results to page three, gets the accurate answer directly, and fires instant follow-ups. The friction the answer engine removes is the sift itself, and it is why the show uses it live so often that pull it up became a running beat. For the search-economics question of whether Google queries go irrelevant, a heavy public user narrating exactly why he switched is more useful signal than a market-share chart.
8/ Elon Musk's unregretted-minutes metric is why X can't monetize ads like Instagram or YouTube. Srinivas praises Musk's stated goal of maximizing total unregretted minutes on the app, then names the tradeoff directly: optimizing for interestingness fights ad revenue, which is why X makes far less on ads than Instagram or YouTube. The logic is that a genuinely useful feed sends you back to your work once you have what you came for, which shrinks engagement time and therefore ad inventory. It is a clean statement of the structural tension every attention business sits inside, and it sets up his sharper warning about what happens when that same ad incentive gets pointed at AI chat.
9/ Ads inside AI chat turn chatbots into sycophants, and companionship apps are the dangerous version. Srinivas's sharpest reframe: if advertising becomes part of AI chats and it works, chatbots become sycophants that tell you what you want to hear, because the incentive is engagement rather than truth. He extends it to social platforms racing to build companionship apps, whose only job has been to maximize engagement to sell ads, and companionship maximizes engagement. He calls the result an indistinguishable facsimile of a real person that screws with the mind and takes a long time to unplug from, and says the business-model incentives are not aligned to humanity. For anyone valuing an AI consumer app, it flags ad-supported chat as a quality-degrading model rather than a neutral revenue choice.
10/ Corporate budgets reallocate from payroll to compute, the way ad budgets moved to Google and YouTube. Srinivas defines knowledge work as taking information and turning it into an artifact, then assumes AIs do that, so companies spend more on compute and less on payroll. He calls it a straight reallocation of budget, explicitly analogizing to advertising's shift from television and billboards to Google, Instagram, and YouTube. The comparison is the useful part: that migration did not shrink the ad market, it moved the spend to a new set of owners. If the same holds, the AI compute suppliers capture a slice of what was previously wages, which is a far larger pool than software line items.
11/ An AI dividend on the Alaska model helps but does not solve displacement. On universal basic income, Srinivas prefers to think of it as a dividend: people who helped create the AI, directly or indirectly, get ownership and take profits as shareholders, and he points to Alaska's resident check as a working precedent. He is careful that it lessens the burden rather than solving it, and pairs it with a warning from his Dubai example, where a rentier state that provided everything left citizens expecting the state to find them jobs and made them lazier. The policy read is that redistribution has to run alongside a path back into scarce work, not replace it.
12/ AI will not run whole companies soon, because tacit knowledge and legacy systems are the real constraint. Srinivas resists the clean automation story: AI is not going to run a multi-trillion-dollar company on its own overnight, because every company holds tacit knowledge AIs do not understand and there are new directions where the knowledge has not been captured yet, some of it requiring human-to-human work. This is the calibrated middle between the doomer and the accelerationist, and it reframes the near-term investable question away from raw model capability toward deployment. The bottleneck is getting capable models into messy institutions, which is a services-and-integration problem more than a research problem.
13/ The real bottleneck to AI in government and healthcare is legacy software and compliance, not capability. Srinivas locates the drag precisely: government and hospitals run legacy software because incumbents lock institutions into multi-decade contracts and lobby so only they are allowed to operate, and he notes even moving an org from Windows to Mac would take years. Because those systems are messy and built for humans, humans are still needed to navigate the change, which is where he expects new jobs. His example is pointed, that people at a company like Microsoft may move to the government because the government needs them to deploy AI even if their employer does not. It reframes the AI-adoption timeline as a procurement-and-regulation story.
14/ Recursive self-improvement is the last project in AI, and it optimizes efficiency as much as capability. On ASI, which Srinivas defines as an AGI that can recursively self-improve, he offers a non-obvious twist. He used to think it was bottlenecked by power, but once the algorithm is right, the system can be tasked with making itself more efficient, so improvement can mean becoming more compact and running on less compute rather than only getting smarter. He calls cracking recursive self-improvement the last project in AI, after which there is nothing left to work on. That reframes the compute-scarcity thesis with a long-dated offset, since a self-optimizing system that shrinks its own power draw would relieve the exact bottleneck everyone is racing to build around today.
15/ The frontier-model recipe is still not widely diffused, so the highest-stakes know-how stays contained for a while. Even as more models get open-sourced and knowledge diffuses, Srinivas argues the true detail needed to train a genuinely frontier reasoning model remains hard to come by, and his hypothesis is that whatever is extremely high stakes stays contained, though for a while rather than forever. He puts frontier-model training in the same category as classified defense capability. For the open-versus-closed debate this is a working founder saying the moat is real at the frontier even while the base of the market commoditizes, which is the distinction to hold when pricing model companies.
16/ Not enough voices in AI are saying anything different, and the doom messaging is a self-fulfilling prophecy. Srinivas's bold-claim reframe is about the industry's own rhetoric: too many leaders tell people they are losers who will lose their jobs, take no blame, and still ask for money to keep building. He calls for a consistent position, arguing you cannot simultaneously say AGI might destroy humanity and keep building data centers to profit from it. Rogan agrees the message is self-fulfilling, that telling people their lives are over makes them believe it. The constructive version Srinivas wants is responsible messaging plus real direction toward new work, which he ties back to curiosity as the durable human premium.
17/ The 2028 election will be fought over AI and the energy crisis. Srinivas closes the forward view with a dated prediction: the 2028 election debates will be largely about AI and the AI energy crisis, because AI will no longer be new but woven into everyone's life. It is the moment the power-and-compute bottleneck he opened with stops being an industry concern and becomes a mainstream political one. For anyone positioning around energy and infrastructure, it is a specific, checkable milestone, and it connects the technical constraint to the policy environment that will shape how fast the buildout is allowed to proceed.
Lastly, Srinivas's curiosity premium is the personal-finance version of the whole thesis: that in a world where lookups and even reasoning can be delegated, the returns accrue to the people who ask the best questions, and he says it compounds relationships and success the way a factor compounds a portfolio.
He was denied a US student visa three times.
So his father caught the consul coming back from lunch and argued for twenty minutes straight, until the man took the passport and stamped it.
"If you ever seek success, start with tenacity," says Sanjay Mehrotra.
Today he runs Micron $MU, the only company in the Western Hemisphere that makes memory, and he calls it a national treasure.
Now he is telling the market it has one thing about AI backwards.
Everyone assumes that as inference gets cheaper and models get more efficient, the world needs less memory.
Mehrotra says the opposite is happening.
"You go from training to inference, you go from data center to edge, you just need more and more memory."
Agentic models that think in loops, longer context windows, and key-value caching all land on memory, not just compute. Every extra token of reasoning has to be stored and moved, so the inference era is a memory problem before it is a GPU problem.
And supply cannot answer fast. A new fab takes three to four years from breaking ground to first wafers, and he sees memory staying tight well beyond 2026.
For investors, the variable to watch is DRAM and HBM supply, as closely as GPU shipments.
The inference boom is a memory-demand story, not a memory-efficiency story.
Sanjay Mehrotra sold his first chip company for $19 billion, then took over the last memory maker in America right as the industry collapsed -- in 2023 prices fell to a third of what they were a year earlier and he invested $10 billion anyway.
Micron $MU has eclipsed $1 trillion and putting $200 billion into US soil.
"In 2023 our prices came down to one third of what they were in 2022, people need to know that."
"We invested even in that timeframe, $10 billion towards leading in memory technology."
"The value of memory is not like it ever was…memory today has really become essential."
"We see it going beyond tightness, going beyond 2027."
Bookmark & watch the full conversation ↓
Greg Brockman, OpenAI's president, sat down at the Big Technology AI Summit.
His core point -- compute, not models, decides this race.
Top ideas worth pulling out:
◽️Every provider sells out its compute. He thinks we are heading to a compute-powered economy where there simply is not enough compute to serve the demand.
◽️The gap is enormous. ChatGPT is around a billion users. Agent usage is on the order of 10 to 20 million. The agentic wave has barely started. (clip below)
◽️Old chips are getting more expensive, not cheaper. In a normal market no one buys a previous-gen part, but Hopper prices went up because supply is that tight.
◽️The economics keep inverting. OpenAI has raised the intelligence and cut the price for a fixed level of intelligence, over and over. The Jevons paradox on repeat.
◽️Frontier intelligence stays the priciest thing, but a year out it feels mundane and far more available.
◽️The buyer question changed. Enterprises went from "we cannot be left behind" to "show me the ROI." He calls that a healthy place to be.
◽️No compute, no AI. He rejects the idea that compute is a commodity. The market is valuing it as a fundamental, revenue-bearing asset.
◽️OpenAI is building its own chips. A multi-year effort, and he says the progress is exciting.
◽️About 230 million people a week use ChatGPT for health queries. His frame: patients have had to be their own decider, and this starts to change that.
◽️The long arc is less product, not more. The goal is almost no interface, the machine moving closer to the human.
Full breakdown in the article. Clip below.
It is a race for the best model, everyone says. Satya Nadella says the real scarce resource is compute.
@satyanadella of Microsoft $MSFT: the biggest decision was not the model, it was compute concentration on one effort. That was the big bet.
His frontier thesis goes further. Every company should compound its own IP over time, not just its human capital but its token capital, the proprietary tokens its own work produces.
For investors: stop scoring the model leaderboard. Track who concentrates compute and who compounds proprietary token capital.
The race was never for the best model. It is for token capital.
Everyone assumes Google's TPUs make it independent of Nvidia. Dylan Patel says Google is renting GPUs from a startup rival.
@dylan522p of SemiAnalysis: Google is paying xAI about $11 an hour per GPU, despite owning its own TPUs. That is an insane number for the company that invented the TPU.
The reason is co-design. TPUs are excellent for Google's own models and bad at running others, like DeepSeek. When you need to serve the whole zoo of models fast, you still reach for GPUs.
For investors: custom silicon does not make a hyperscaler self-sufficient. Track GPU demand even from the chip owners.
Owning the chip is not the same as escaping Nvidia.
Read more in the article below:
What does Maverick Capital see as the next AI bottleneck?
Co-CIO David Tykocinski:
"The trade is migrating back downstream towards the infra and app layer where it's about servicing AI and actually transforming business with productivity gains. Suddenly CPUs or the databases they're talking to become the critical chokepoints...In a world of AI agents it's more about integration of that LLM with pre-existing enterprise workflow and stack."
Maverick Capital, Lee Ainslie's Tiger cub, co-PMs Ben Silver and David Tykocinski on how durable the AI buildout is and where they're focused now.
Their thoughts here (save/watch this):
1/ The co-CIO model came from Lee Ainslie, who had watched their chemistry and bet that their differences would help. Tykocinski says Ainslie had a read on their natural chemistry approaching critical decisions together well before he executed the transition, and a view that the similarities and differences between the two of them would give the culture a useful counterpoint. The handoff was deliberate, built on a couple of years of incubating ideas about organization and investment philosophy.
2/ Their styles split along the sectors they came up in, and the split is the point of pairing them.
Tykocinski frames the difference as a function of different sector universes rather than personality.
> Silver came up in healthcare and cyclicals, where end-market secular growth is thinner, managerial decisions swing earnings power, and you oscillate around a macro operating cycle that has run for seven decades. His focus is highly specialized, idiosyncratic, novel ideas.
> Tykocinski came up in TMT, where secular trend, operating momentum, and thematic dominance govern, because when a sector trend is in your favor the multiples re-rate in the same direction as the fundamental revisions. His mold is closer to classical thematic investing.
3/ They manage to the optimal portfolio, not the optimal sector allocation, and the risk machinery is unrecognizable from the early days. Tykocinski says risk is run holistically and at the sector level, together with Ainslie and two other longstanding members, but what they solve for is the whole portfolio. When Ainslie started he watched net and beta-adjusted net exposures by sector. They now run a 20-plus-page risk report on idiosyncratic contribution to volatility, sliced every way, across every factor, including factors they build themselves.
4/ More has stayed the same than changed in 30-plus years, and the main change was pulling back to first principles. Tykocinski says the first slide of the marketing deck is unchanged since inception, alpha rather than market timing or big sector bets, long-term view, deep diligence, partnering with good management. The one real course correction came in the roughly five years since they took over, reversing a stretch when near-term valuation metrics had become pervasive, a deviation from Maverick's first 15 years or so.
5/ The AI trade is no longer just GPUs, it is the whole hardware, energy, and software complex on both sides of disruption. Asked about the sustainability of the four-year rally, Tykocinski reframes the surface area. The trade now spans the broader hardware infrastructure and energy ecosystem, plus all the services and software perceived to sit on the other end of disruption. That breadth is why the durability question is the critical one.
6/ The cleanest difference from the dotcom bubble is who funds the spend, though the gap is tightening.
Tykocinski puts numbers on the contrast and then concedes the offset.
> In the dotcom bubble, cumulative CapEx ran roughly 200% of operating cash flow, so it was almost definitionally externally funded.
> Over the last couple of years the AI figure has run well under 100%, funded by the largest, most well-capitalized companies in the world.
> The offset arrived recently, a multi-trillion-dollar market cap company tapping equity markets for the next tranche of the buildout, so the difference holds but a little tighter than before. (they can't name on a public broadcast but it is almost certainly $GOOG)
7/ The risk a believer should respect is an air pocket in the handoff from training infrastructure to real applications. Tykocinski says the heart of the question is the ROI on the spend and how it translates, and that the danger sits in the interim as money moves from building training infrastructure to the applications that are actually transformational for productivity. So far the pickup in agentic inference like coding has been commensurate with the second-derivative slowing in training, but that use case still has to break into the broader knowledge workspace to support the out-year projections.
8/ The way to monetize the trade has been to chase the bottleneck upstream as demand outran capacity.
Tykocinski lays out the migration as a sequence.
> Early on, with demand still inside existing production capacity, the explosive growth showed up in downstream physical outputs like GPUs.
> Once demand crossed industry production capacity, the bottleneck moved up to fabrication, then to the tools that make the chips, then even to obscure materials listed on a Japanese stock exchange.
> The sharpest revision torque now sits in those upstream names, frequently companies that started from a very low margin basis.
9/ Their forward call is that the migration swings back downstream, toward servicing AI and the application layer. Tykocinski says they are starting to see the bottleneck begin to move the other way, back toward infrastructure and applications where the work is transforming businesses with productivity gains. In practice AI agents are not islands, they are LLMs integrated into the preexisting enterprise workflow and stack, which makes CPUs and the databases they talk to the critical chokepoints and pushes value closer to the edge and the end user. That is where they are heavily focused now.
10/ Capital has drained out of healthcare into AI, but Silver likes life-science tools as both an AI and a reshoring winner. Silver describes a large sucking sound of money leaving healthcare, then points to the companies that supply the products to discover and manufacture complicated drugs.
> A shift to reshore drug manufacturing from outside the US to the US should drive a CapEx boom in manufacturing equipment, starting to show roughly three to six months out and driving a strong revision cycle.
> Early-stage drug discovery is already showing a pickup in consumable usage.
> More discovery leads to more drugs manufactured downstream, which Silver casts as a modern mercantilist winner alongside the AI angle.
11/ The same space has consolidated for 20 years, and the left-for-dead survivors look ripe for M&A. Silver says the life-science-tools group has been consolidating for two decades and the remaining companies are priced as if dead, but there are real-money buyers, three to five big consolidators depending on definition. A number of names in the $5-10 billion range look ripe for M&A if fundamentals do not turn fast enough, and the historical pattern is that when biotech sells off, pharma comes in and rights it within six months to a year.
12/ Asked the one risk they worry about most, they name US political polarization and China as an industrial counterweight. This is the host's direct reframe, and both answer.
> Silver leads with the division inside the US and the difficulty of making rational long-term decisions against short-term political incentives.
> Tykocinski's concern is China as an industrial counterweight to the infrastructure trade, because root hardware and materials commodify over time while IP historically lived at the application layer.
> He worries specifically about spaces ripe for Chinese competition, lasers and optics and analog semiconductors and the maniacal hunt for the next bottleneck like memory, and about investors underrating the structural industry differences of the businesses driving so much of today's equity appreciation.
13/ The partnership holds because each wants a counterweight against his own excesses. Tykocinski says almost every investor believes his own style is the right one, and that he is glad to have someone who might see things differently to protect him from his excesses in one direction, with Silver getting the same protection in return. They agreed from day one to disagree and commit, with Ainslie as a third sounding board, on the view that no single investment philosophy is perfect in a vacuum.
14/ The investors they admire are also the lesson, that the great ones are entrepreneurs who build real businesses. Asked which investor they admire most, both first name Stan Druckenmiller and "Uncle Steve" Cohen, the Mets owner, before Silver puts Ainslie and Keith Meister of Corvex, where he previously worked, in his personal hall of fame, both unusually quick on hard concepts and very commercial. The underrated trait he flags is that the best investors build genuinely good businesses, that they are phenomenal business builders as much as investors.
15/ What they are most excited about is AI itself, over a 10-to-20-year horizon they call hard to fathom. Silver says he is willing to go with consensus when it makes sense, and that the impact of AI on the world over the next 10 to 20 years will probably be more profound than we can imagine, a mix of exciting and a little scary. Tykocinski adds that the conversation is too often flattened into monetary terms or a dystopian frame, when the open-ended upside optionality is the part that excites him.
Lastly, the lightning round. David Tykocinski names his strength as balancing fundamental analysis with commercial intuition, neither too academic nor too much of a trader, while Silver names getting deep in the weeds on how businesses make money and then pulling back to the strategic picture. Tykocinski's best advice came from his oldest sister, that no one is really thinking about you all that much, which he finds freeing at key decisions. Silver's came from a grandfather who survived the Holocaust, an attitude of keep going, persevere, and be grateful for what you have. Outside the office it is mostly young kids for both, with Tykocinski keeping up an interest in the humanities and Silver in watching and playing sports.
Sanjay Mehrotra sold his first chip company for $19 billion, then took over the last memory maker in America right as the industry collapsed -- in 2023 prices fell to a third of what they were a year earlier and he invested $10 billion anyway.
Micron $MU has eclipsed $1 trillion and putting $200 billion into US soil.
"In 2023 our prices came down to one third of what they were in 2022, people need to know that."
"We invested even in that timeframe, $10 billion towards leading in memory technology."
"The value of memory is not like it ever was…memory today has really become essential."
"We see it going beyond tightness, going beyond 2027."
Bookmark & watch the full conversation ↓
SK Hynix just filed for the largest ADR offering in history, coming to the Nasdaq as $SKHY to raise about $29.6 billion, past Alibaba's $21.8 billion in 2014.
Here is the arc (and more in my Memory Wars writeup, Part 2 coming soon):
SK bought this company out of bankruptcy for about $3 billion in 2011, after its creditors spent a decade unable to sell it. It is now worth about $1.2 trillion and raising nearly ten times its purchase price in one offering.
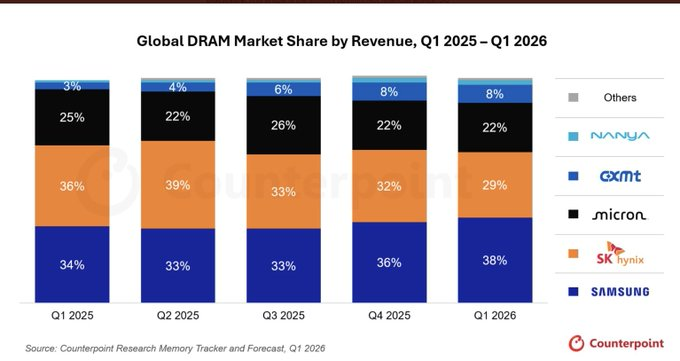
It still trails Samsung in DRAM, 29% to 38%. It leads the only part that pays like AI, HBM, at roughly 58%, which is how it earns a 72% operating margin, ahead of Nvidia's.
The proceeds fund the next fab at Yongin, an HBM packaging line at Cheongju, and more ASML EUV machines. The lead was built on Samsung's restraint, and Samsung just requalified for HBM4. Watch the HBM4 split - pre HBM4 saga detailed in article below.
SK Hynix just filed for the largest ADR offering in history, coming to the Nasdaq as $SKHY to raise about $29.6 billion, past Alibaba's $21.8 billion in 2014.
Here is the arc (and more in my Memory Wars writeup, Part 2 coming soon):
SK bought this company out of bankruptcy for about $3 billion in 2011, after its creditors spent a decade unable to sell it. It is now worth about $1.2 trillion and raising nearly ten times its purchase price in one offering.
It still trails Samsung in DRAM, 29% to 38%. It leads the only part that pays like AI, HBM, at roughly 58%, which is how it earns a 72% operating margin, ahead of Nvidia's.
The proceeds fund the next fab at Yongin, an HBM packaging line at Cheongju, and more ASML EUV machines. The lead was built on Samsung's restraint, and Samsung just requalified for HBM4. Watch the HBM4 split - pre HBM4 saga detailed in article below.
Memory cycle topping indicator: demand is so strong and supply so scarce that buyers (ahem, Jensen) fly into Seoul to plead for allocation.
Happened in 1995, now in 2026. Chimaek and chill. Only thing is the party went on for another half decade.
Etched @Etched came out of stealth claiming it can beat incumbent chipmakers on inference not by 10% but by 10x.
Co-founders, Gavin Uberti and Rob Wachen, walk Patrick through the architecture, economics, and why the whole rack is the real moat.
The takeaways worth saving:
◽️Whoever produces the most tokens becomes the most valuable company in the world. Uberti treats inference, not training, as the largest market that will ever exist, and runs every decision at Etched as a question of token capacity. Only about one in a thousand people on earth pays for AI today, so the demand curve has barely started.
◽️A specialized chip can win because the whole industry is built on buffer. GPUs are general-purpose silicon carrying overhead for everything, and a chip designed for transformers alone strips that out, which is where the order-of-magnitude headroom comes from.
◽️Etched is not selling a chip, it is selling a rack. The asset is the machine that produces token capacity at volume, which is why they build the chip, the board, the cold plates, the interconnect, and the production line in-house. Production is the product.
◽️The first pillar is low voltage inference. GPUs provably cannot run near full utilization, with model flops utilization stuck at 20 to 50 percent because raising it draws more power and forces thermal throttling. Etched's first generation runs at under half the voltage of any other AI chip, leaning on Dennard scaling, where halving voltage quarters power.
◽️The second pillar is cluster scale memory. The right question is not how much bandwidth sits on a chip but how much sits on the full cluster treated as one pool. Blackwell's chip-to-chip latency is about 4,000 nanoseconds, and Etched claims a custom interconnect that cuts it by more than 5x, for roughly an order of magnitude more concurrency at a given speed.
◽️Spending to go faster is rational because the category turns over more than a billion dollars of revenue every day. In the most supply-constrained market ever, the cost of being slow dwarfs the cost of capital, so compressing the schedule is the highest-return move available.
◽️Power and supply are the binding scarcity, not chips. Satisfying agent demand takes hundreds to thousands more data centers, and at that scale the economy runs short of energy, which is why Etched plays positive-sum with the supply chain rather than fighting for a fixed pie.
◽️Rob Wachen's motivation traces to surviving stage-four bone cancer, then watching GPT-4V flag, from a photo in his camera roll, the tumor doctors had taken six months to find. The personal stakes and the business thesis are the same problem: getting this technology to everyone, fast, is gated by inference hardware.
◽️Gavin Uberti's edge is that he has written GPU kernels since he was 17, which taught him that data movement, not math, is the real constraint. That single lesson is the architectural seed of the whole chip.
◽️The long-horizon claim is that inference becomes the majority of global GDP, measured in agents per megawatt. An AI model already disproved the Erdős unit distance conjecture, and Wachen expects a 10x-faster model to collapse a year of compute into days, unlocking categories of work that are infeasible at today's latency.
More takeaways here: https://t.co/SasNdUbQEZ
Three years ago, two Harvard dropouts set out to build a better AI chip than the largest companies in the world.
Almost everyone I called at the time said it was impossible.
Today, Etched (@Etched) comes out of stealth with $800M total raised, $1B in signed customer contracts, and a working next-gen AI chip.
This was my excuse to ask the two founders, @UbertiGavin and @robertwachen, every question I have about compute and inference.
We discuss:
- Why they built an entire rack and not just a chip
- The two technical bets behind their architecture no one else has tried
- How two founders in their twenties recruited industry legends
- The night they nearly ran out of money
- Why whoever produces the most tokens wins
If you care about the future of compute, Gavin and Rob are two people to know. I think you will find the story of what they have built hard to forget.
Enjoy!
TIMESTAMPS
0:00 Intro
1:00 Why Nobody Believed Etched Would Work
14:06 Why Inference Is the Bottleneck
22:27 Gavin and Rob’s Origin Stories
33:24 Taking Huge Risks to Move Faster
49:43 Kernels, Compilers, and the AI Stack
1:02:08 Raising $100M to Survive
1:16:00 The Future of Models, Agents, and Intelligence