(a) how did MMLU become the defacto standard benchmark every LLM is trying to beat?
(b) it is estimated to contain 9% questions that human experts think are wrong. do we know if humans and models agree on which ones belong in this 9%?
Papers at #EMNLP2024 #3
A counter-example to the frequently adopted mech interp linear representation hypothesis: Recurrent Neural Networks Learn … Non-Linear Representations
Fri Nov 15 BlackboxNLP 2024 poster
https://t.co/csKUpERrsX
CC @robert_csordas@ChrisGPotts
the term "experts" in "mixture of experts" in the context of LLMs is highly misleading and does way more harm than good in coming up with a conceptual representation of what this component brings to the table.
i think this is the wrong question. yes, CS graduates are very bad in software development, and a dedicated LLM can be better. but put these graduates in a job, and some will develop to be "senior devs" at some point, capable of working on real-life, large systems. LLMs won't.
Great workshop at AAAI about low-rank representations!
These have important consequences for Neurosymbolic: Logical circuits can be understood as low-rank factorisations.
Unless you are an OpenAI employee working on improving their products, I don’t understand why such efforts are science. Why are we (question to faculty) spending taxpayer dollars in doing QA for a closed product by a well-capitalized company that does not give back to science?
Today, we release several Moshi artifacts: a long technical report with all the details behind our model, weights for Moshi and its Mimi codec, along with streaming inference code in Pytorch, Rust and MLX. More details below 🧵 ⬇️
Paper: https://t.co/mMInmjiBIC
Repo: https://t.co/PFak47FMrm
HuggingFace: https://t.co/bqG4IS0ntg
as SAC for EMNLP I was asked to read the discussions between the authors and reviewers and had every intention to do so but the length of the discussions is out of control. many tables with results of new experiments, hundreds of lines of code (!). bring back word limits please.
I agree with much of both @emilymbender’s #ACL2024 presidential talk and @yoavgo’s rejoinder, but I want to comment on just one aspect where I disagree with both: the definition and domain of CL vs NLP. 🧵👇
New essay: ML seems to promise discovery without understanding, but this is fool's gold that has led to a reproducibility crisis in ML-based science. https://t.co/UrHbAsdSz0 (with @sayashk).
In 2021 we compiled evidence that an error called leakage is pervasive in ML models across scientific fields. In our most recent survey the number of affected fields has climbed to 30. https://t.co/mjy8TfKA4U
Leakage is only one of many reasons for reproducibility failures. There are widespread shortcomings in every step of ML-based science, from data collection to preprocessing and reporting results. https://t.co/hFhvM1rSHl
Root causes
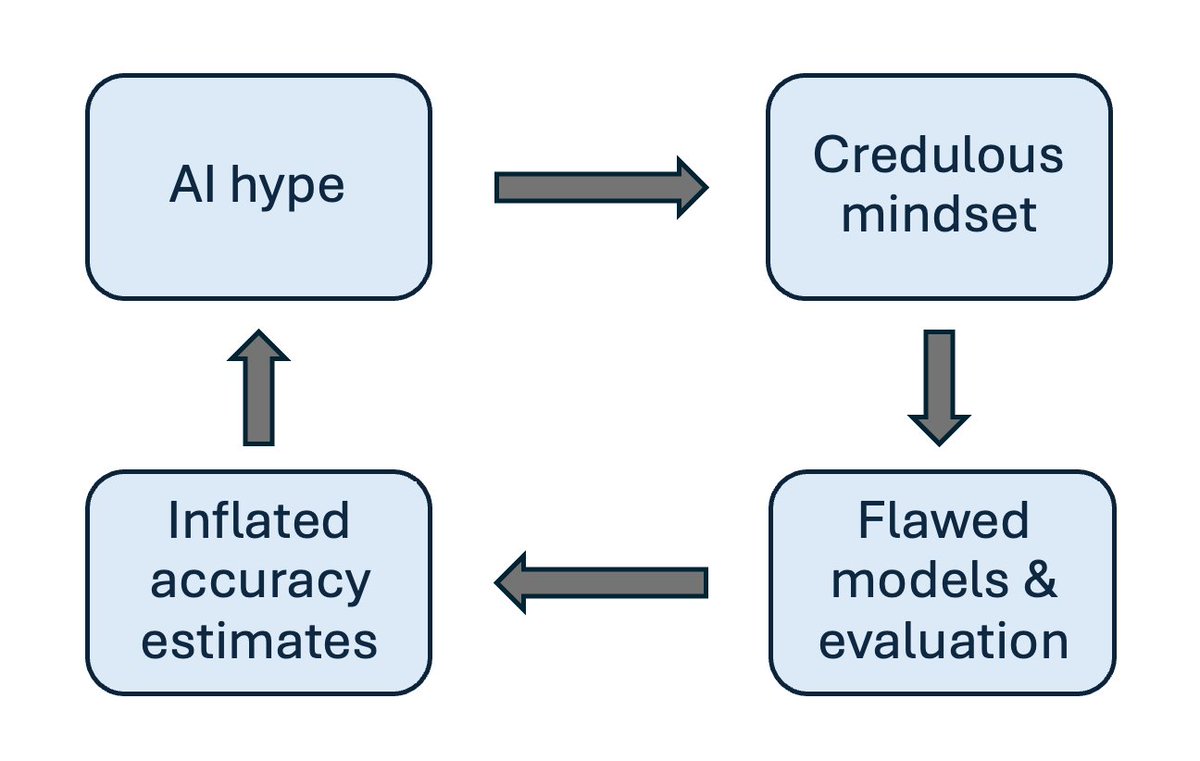
The reasons for pre-ML replication crises, such as publication bias, also apply to ML. But a new and important reason for the poor quality of ML-based science is pervasive hype, resulting in the lack of a skeptical mindset among researchers, which is a cornerstone of good scientific practice.
We’ve observed that when researchers have overoptimistic expectations, and their ML model performs poorly, they assume that they did something wrong and tweak the model, when in fact they should strongly consider the possibility that they have run up against inherent limits to predictability. Conversely, they tend to be credulous when their model performs well, when in fact they should be on high alert for leakage or other flaws. And if the model performs better than expected, they assume that it has discovered patterns in the data that no human could have thought of, and the myth of AI as an alien intelligence makes this explanation seem readily plausible.
This is a feedback loop. Overoptimism fuels flawed research which further misleads other researchers in the field about what they should and shouldn’t expect AI to be able to do. https://t.co/UrHbAsdSz0
Glimmers of hope
Researchers should in principle be able to download a paper’s code and data, review it, and check whether they can reproduce the reported results. And the vast majority of errors can be avoided if the researchers know what to look out for. So we think that the problem can be greatly mitigated by a culture change where researchers systematically exercise more care in their work and reproducibility studies are incentivized.
We have led a few efforts to change this. First, our leakage paper has had an impact. Many researchers have used it to avoid leakage in their own work and to check previously published work. https://t.co/u2eJayGky9
Beyond leakage, we led a group of 19 researchers across computer science, data science, social sciences, mathematics, and biomedical research to develop the REFORMS checklist for ML-based science. It is a 32-item checklist that can help researchers catch eight kinds of common pitfalls in ML-based science. It was recently published in Science Advances. Of course, checklists by themselves won’t help if there isn’t a culture change, but based on the reception so far, we are cautiously optimistic. https://t.co/SWu8E6O4am
A tool, not a revolution
Of course, AI can be a useful tool for scientists. The key word is tool. AI is not a revolution. It is not a replacement for human understanding — to think so is to miss the point of science. AI does not offer a shortcut to the hard work and frustration inherent to research. AI is not an oracle and cannot see the future.
We are at an interesting moment in the history of science. Look at these graphs showing the adoption of AI in various fields (by Duede et al. https://t.co/pKhvCfzNnp):
These hockey stick graphs are not good news. They should be terrifying. Adopting AI requires changes to scientific epistemology. No scientific field has the capacity to accomplish this on a timescale of a couple of years. This is not what happens when a tool or method is adopted organically. It happens when scientists jump on a trend to get funding.
Given the level of hype, scientists don’t need additional incentives to adopt AI. That means AI-for-science funding programs are probably making things worse. We doubt the avalanche of flawed research can be stopped, but if at least a fraction of AI-for-science funding were diverted to better training, critical inquiry, meta-science, reproducibility, and other quality-control efforts, the havoc can be minimized.
https://t.co/UrHbAsdSz0
P. S. Our book AI Snake Oil is all about how to separate real AI advances from hype. It's now available to preorder (and we're told preordering makes a big difference to the book's success).
https://t.co/foQpEhRfhs
https://t.co/fHa32jM5Es
"A random half of panelists were shown a CV and only a one-paragraph summary of the proposed research, while the other half were shown a CV and a full proposal. We find that withholding proposal texts from panelists did not detectibly impact rankings."
https://t.co/IVXjvGqUDI
So here's a story of, by far, the weirdest bug I've encountered in my CS career.
Along with @maciejwolczyk we've been training a neural network that learns how to play NetHack, an old roguelike game, that looks like in the screenshot. Recenlty, something unexpected happened.
One core learning we had with Chameleon is that the intended form of the modality is a modality in itself. Visual Perception and Visual Generation are two separate modalities and must be treated as such; hence, using discretized tokens for perception is wrong.