SeamlessStreaming is an AI translation model that can deliver state-of-the-art results on streaming translation with <2 seconds of latency. One core piece of our latest Seamless Communication research work by teams at FAIR.
More on this project ➡️ https://t.co/pPgkrTvryg
Opt for lang-specific encoders for real-world applications in lang like French. LeBenchmark 2.0 is here with 3 new pre-trained speech SSL models (until 1B), tested on 6 tasks, powered by Jean Zay #HPC from @Genci_fr.
Paper: https://t.co/sqA1nMAnMz
Models: https://t.co/NWB4ZcmuYx
Congratulations to the team on this exciting release featuring an all-in-one massively multilingual multimodal machine translation model! What I'm particularly excited about for this work👇
Projet ANR Pantagruel accepté :) Construction et évaluation de giga modèles de langue multimodaux et inclusifs (écrit, oral, pictogrammes) pour le français général et clinique https://t.co/K63U17ld3f
Presented this week at ACL (from NLP@NLE): Memory-efficient NLLB-200: language-specific expert pruning of a massively multilingual machine translation model - Naver Labs Europe https://t.co/N2UezdJAf5
Presented this week at IWSLT@ACL: NAVER LABS Europe’s Multilingual Speech Translation Systems for the IWSLT2023 Low-Resource Track (were ranked 1st on the 2 lang pairs they participated in this track) - https://t.co/gRf9NhrtM1 with @mzboito I.calapodescu, a.berard & e.gow-smith !
We are doing🏔️ALPS 🏔️again, 4⃣th edition
A week full of insightful lectures, knowing fellow researchers and dreaming of joint projects
≠ this time: we actually meet in the Alps. Close to a French National Park, at 1500m, surrounded by mountains
https://t.co/pNqBUzvo6g
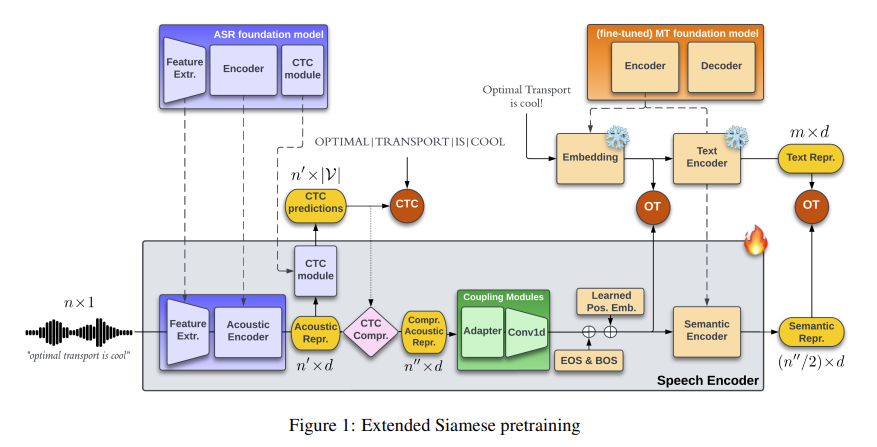
Excited to share our submission to #IWSLT 2023. We utilized large speech & text foundation models, and pretrained them with Optimal Transport to adapt the speech representations to the text space, before supervised ST fine-tuning.
Check our method here: https://t.co/8iMJror1vU
Many papers recently exploit optimal transport-based losses, and it is great to see how this can be done to improve ST models in https://t.co/wCMLPIGOZS. I would have been curious to see results on the Conformer model and with CTC compression!
Happy to share our recent work on speech translation (ST): https://t.co/xS5hsAorRS, which will be presented at ICML 2023. We make two contributions: 1) showing that CTC can reduce the modality gap in ST pre-training... 1/2
@khainb_ml Many thanks Khải @khainb_ml! Congrats on your paper as well!! Unfortunately I won't be able to attend due to visa issues :( Enjoy Hawaii and the conference. Hope to meet you at another venue in the future.