We are currently hiring for 2 RS/RE positions as well as 1 Postdoctoral position. We are conducting research on exciting topics related to speech-to-speech translation with the aim to solve live multilingual communication. Please reach out if you are interested to learn more!
We're happy to announce the 3rd edition of the simultaneous shared task at @iwslt ! Novelty this year: en-de/en-ja/en-zh, en-de manual eval and human interpretation benchmark, text-to-text and speech-to-text evaluated together. Consider participating! https://t.co/RsN0ogUdas
We've taken another step toward eliminating language barriers. In collaboration with @huggingface, we recently released 4 direct speech-to-text models that translate English to Arabic, Catalan, German & Turkish. Try out the models for yourself: https://t.co/mKSGLwYnBn
We’re proud to announce that we won 1st place at this year’s annual multilingual speech translation competition hosted by @iwslt. Read the details on building a state-of-the-art speech translation system: https://t.co/AWvMwvKUoO
Happy to share our large-scale multilingual speech corpus, VoxPopuli:
- 400K-hour unlabelled speech in 23 languages
- 1.8K-hour transcribed speech in 16 languages
- 17.3K-hour speech-to-speech interpretation data in 15x15 directions
https://t.co/P1vH4jARCR
#ACL2021NLP
To help #NLP researchers create advanced translation & speech recognition systems for more languages spoken around the world, Facebook AI is releasing VoxPopuli. This data set provides 400K hours of unlabeled speech data in 23 languages. Learn more: https://t.co/yipgc4VFdb
Multilingual Speech Translation from Efficient Finetuning of Pretrained Models. A simple recipe for SoTA speech translation for 36 pairs. https://t.co/H23nDIcApA session oral 3D with @ChanghanWang Yun Tang @juanmiguelpino@MichaelAuli and other colleagues at FAIR #ACL2021NLP 2/n
How much can we improve speech translation without adding expensive labeled data? We achieve SOTA performance on CoVoST 2 (average +2.6 BLEU) by combining several techniques to leverage large-scale unlabeled speech/text data.
https://t.co/5wrmmLYHsH
Fairseq models coming soon
Happy to share our work "Large-Scale Self- and Semi-Supervised Learning for Speech Translation"
New state of the art (+2.6 BLEU on average) on CoVoST-V2 with a simple approach, lot of unannotated data and less supervision
Paper: https://t.co/SqmTNz0QbV
Models coming soon
We're happy to announce the start of the four challenge tracks for the 2021 evaluation campaign!
🗓Feb 1: Training data released
🗓Apr 5-16: Evaluation period
See more at https://t.co/8ynQZdOwqY and register your interest below: https://t.co/To4oPbTRhG
We've just released our award-winning news translation models for #WMT2020. This features low-resource languages pairs: Tamil<->English and Inuktitut<->English Download the model here:
https://t.co/LrZYC8DGHa
We're sharing our work on improving translation for low-resource languages (Tamil and Inuktitut) at #wmt2020. By combining various techniques, we improved translation quality for these underserved languages. Tune in tomorrow at 12pm EST. Here's the paper: https://t.co/POnAmjY73z
Check out @xutai_ma's #EMNLP2020 demo today 6pm Pacific! SimulEval is a new toolkit to standardize latency measurement for simultaneous speech and text translation. Paper: https://t.co/5Sx9VrWNac Code: https://t.co/3ZvkbTUfYR with Javad Dousti, @ChanghanWang, @thoma_gu
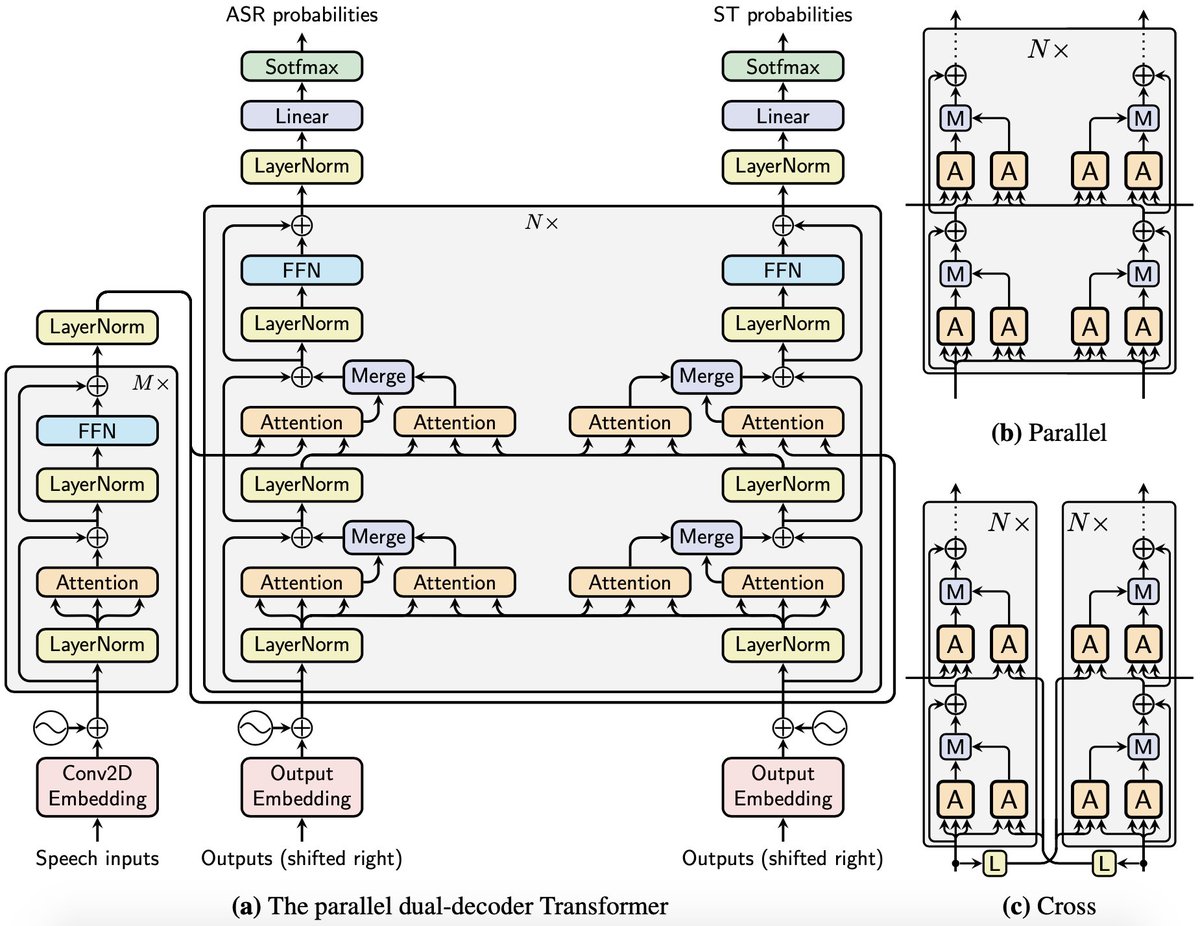
Happy to share our recent work on a new architecture called the dual-decoder Transformer for joint speech recognition and multilingual speech translation (oral presentation @coling2020).
Paper: https://t.co/uamKw0h2Ht
Code: https://t.co/XSuDBz62dF
Check out https://t.co/T2hQPk1qH6: summary of the simultaneous task at 1:39:36, awesome panel on offline speech translation at 2:43:46 and another awesome panel on simultaneous speech translation at 3:45:55
We're looking for a postdoctoral researcher to work on speech to speech translation at @facebookai Please apply at https://t.co/J2mqXxzmtG and/or DM me