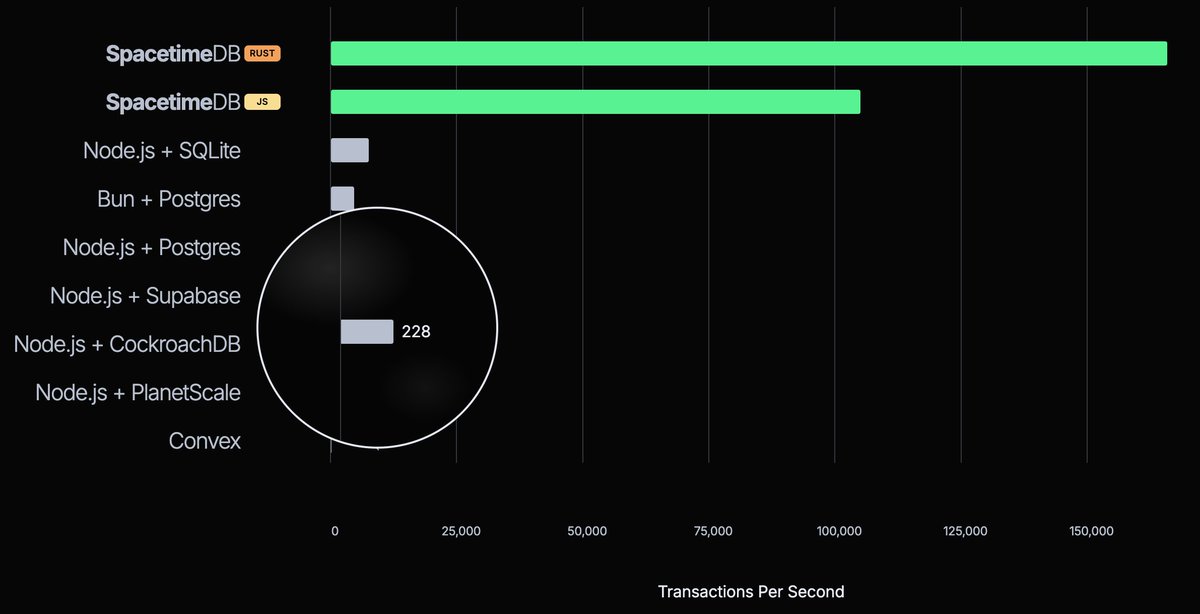
Specialized models are becoming a practical path to better AI UX.
Olive moved from a frontier model to a custom model trained with Inference Catalyst for their food verdict workflow.
After a user scans a product, the model now delivers near-instant verdicts on what to watch out for, making the in-store experience faster and more seamless while cutting inference cost significantly.
Results:
- p50 latency: 2,721ms → 591ms
- p99 latency: 6,414ms → 998ms
- time to first word: ~0.25s
- inference cost: ~70% lower
Great working with @oliveholistic on this!
Full case study here: https://t.co/4j3rXJcrHU
3 weeks ago we open-sourced HALO
this led to talking with dozens of teams running agents at scale
we realized the current agent monitoring tools aren't built for the future that we so clearly see ahead of us
today we’re releasing native OpenTelemetry-compatible agent tracing on @inference_net, powered by the same open-source core behind HALO
We’re introducing HALO 😇
Hierarchal Agent Loop Optimizer
HALO is an RLM-based agent optimization technique capable of recursively self-improving agents by analyzing their execution traces and suggesting changes.
This work is inspired by the Mismanaged Genius Hypothesis proposed by @a1zhang and @lateinteraction earlier this month.
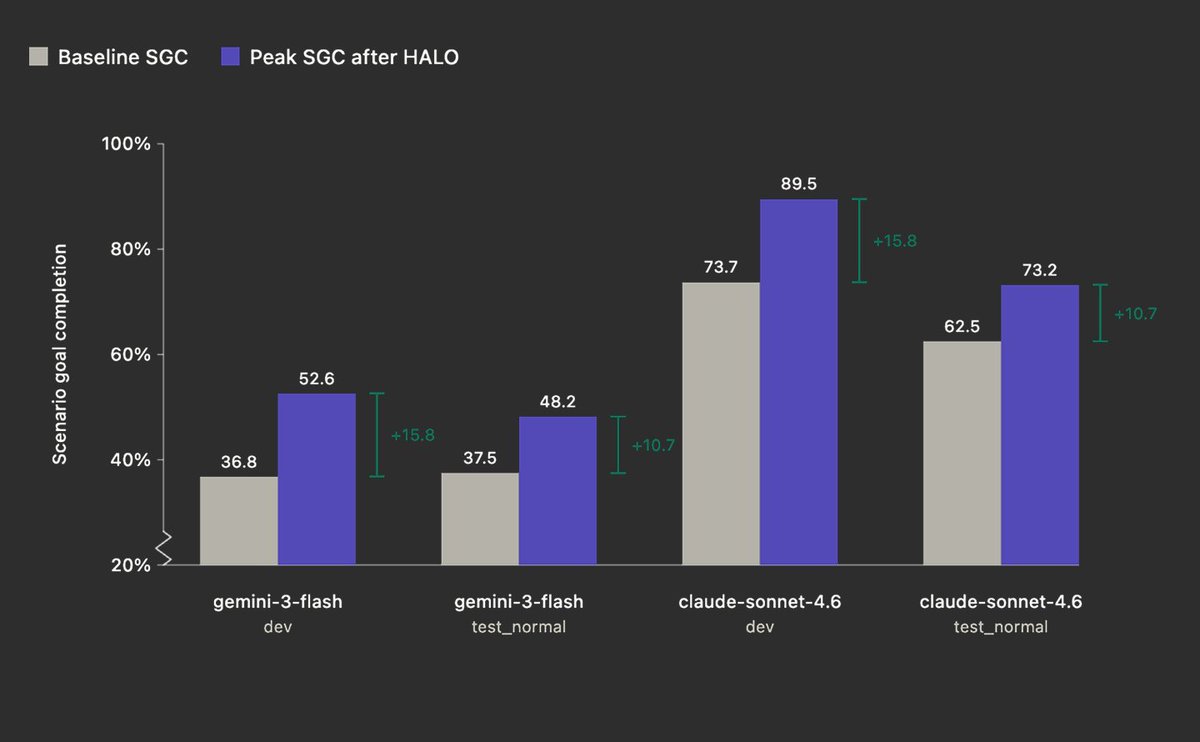
tldr; we improved performance on AppWorld (Sonnet 4.6) from 73.7 --> 89.5 (+15.8) by giving HALO-RLM access to harness trace data and asking it to identify issues.
The feedback from HALO surfaced failures in the harness such as hallucinated tool calls, redundant arguments in tools, refusal loops, and semantic correctness issues. Each issue mapped cleanly to a direct prompt update.
We then fed these finding into Cursor (Opus 4.6), and asked the coding agent to update the underlying harness.
We repeated this trace -> HALO-RLM analysis -> code update loop until the score plateaued.
Today we’re open-sourcing the core HALO-RLM framework, evals, and data for further review.
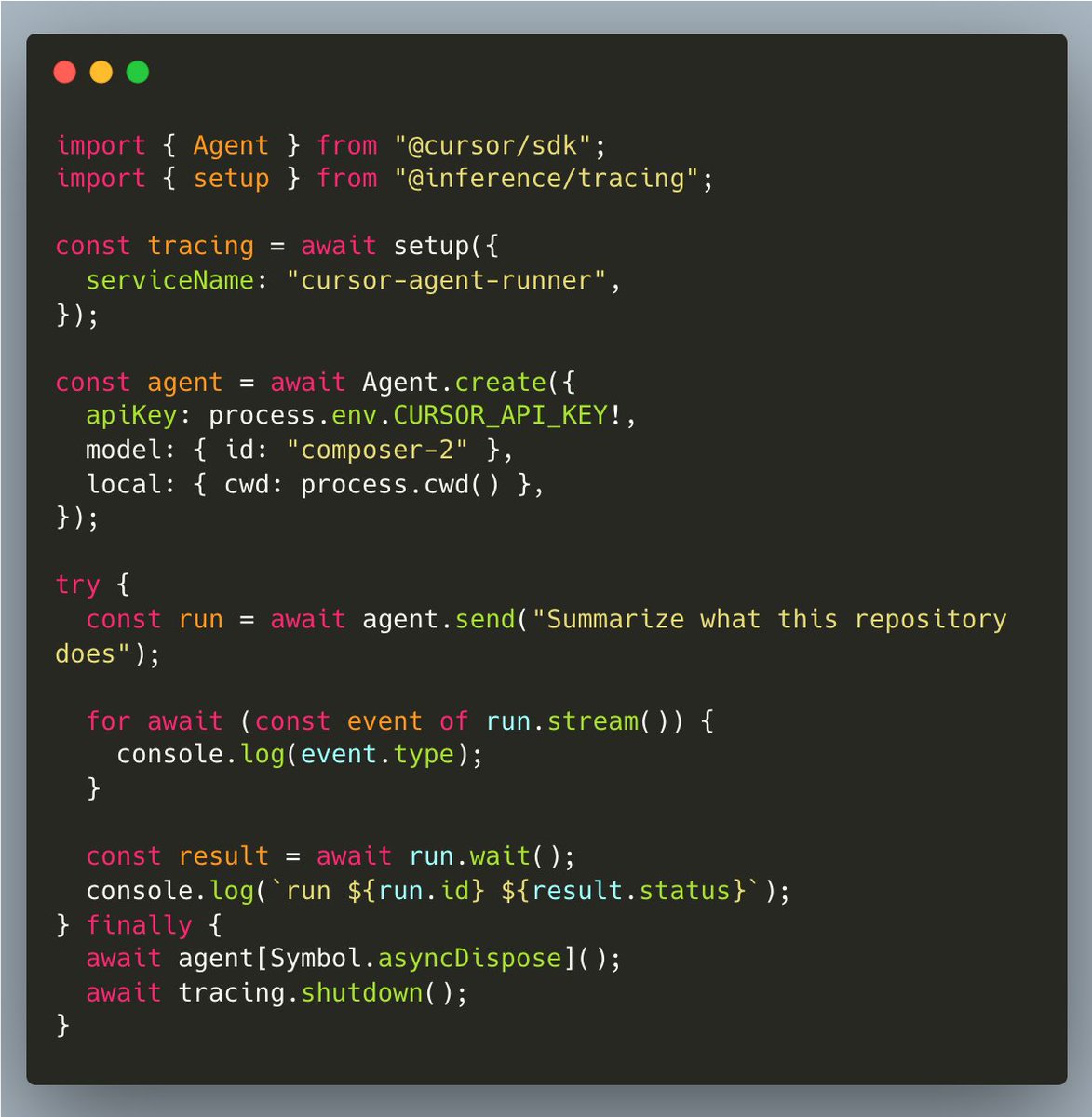
Excited to launch Day One support for tracing the Cursor Agent SDK with @inference_net
3 lines of code is all you need to track agent performance across executions and iterate to perfection
Docs below 👇
Frontier LLMs can do a lot—but can they write good flashcards?
Turns out: not yet! @andy_matuschak and I created an eval for flashcard generation and found surprisingly poor results.
Worse, newer models aren’t helping: GPT 5.4 performs worse than 5.2, Opus 4.7 worse than 4.6.
We're releasing Schematron V2, a family of Specialized Language Models for converting messy HTML to structured JSON
frontier performance at 1/10th the cost
Schematron V2 was designed in partnership with some of the largest web-scraping companies in the world to meet the demands of their heaviest workloads
Schematron-V2-Turbo and Schematron-V2-Small are available today on @inference_net
Get started: https://t.co/8ojqgqnDqx
Introducing Catalyst: a developer platform to monitor, train & deploy self-improving AI models
built for teams operating AI products at scale
Catalyst can automatically:
- collect traces from your agents
- curate training data & evals
- train & deploy models on par w/ Opus 4.6
Inference processes trillions of AI tokens a week for their customers. When something breaks, the @inference_net team needs to ship a fix in minutes, not wait an hour for CI to finish.
@TheHarryET and @francescodvirga tell the story of how they got there. 👇
You're overpaying by $30,000/month running AI models at scale.
Here's why (and how to fix it)
How OpenAI & Anthropic work
Per-token pricing:
→ OpenAI (GPT-4o): $2.50 / $10 per million tokens
→ Anthropic (Sonnet 4.5): $3 / $15 per million tokens
At 1M queries/month: $30,000 - $38,000/mo
The problems:
1️⃣ You pay for capabilities you don't use
Frontier models are trained for everything. Your task needs maybe 1% of those capabilities.
You're paying for the other 99%.
2️⃣ No economies of scale
Token #1: $0.003
Token #1,000,000: $0.003
Your costs never decrease.
3️⃣ Smaller frontier models and off-the-shelf open-source models mean worse quality
You're forced to choose to pay more or get worse results.
The solution:
Dedicated GPUs + Specialized Models
Instead of per-token pricing, rent dedicated GPUs at a fixed monthly cost.
Then train custom models specialized for your specific task:
→ Distilled from frontier models and large open source models (GPT-5, Claude, Gemini, Kimi, GLM)
→ Match or exceed frontier quality for your use case
→ 2-3x faster inference
At 1M queries/month: $8,600/mo
That's 71-77% cheaper with no quality sacrifice.
And the biggest misconception is that "custom models can't match frontier quality."
The reality:
When specialized for your task, they can exceed frontier intelligence.
—
Most teams don’t need “the smartest model in the world.”
They need the smartest model for one job.
Running on infrastructure they control.
At a cost that actually scales.
We're hiring ML Engineers and Researchers!
@inference_net is building end-to-end automated LLM training pipelines. Our customers include the fastest-growing companies across the Fortune 500, consumer mobile, and AI-native SaaS.
$10,000 referral bonus.
Links below. DMs open.