@andrewmccalip How do you prevent developers from just click farming?
If they get 50% of the click revenue every click is financially incentivized and a low-quality lead by default without benefit to the advertiser.
It was great working with @oliveholistic to improve their product experience! If you want faster and cheaper inference at frontier model quality, shoot me a DM.
Specialized models are becoming a practical path to better AI UX.
Olive moved from a frontier model to a custom model trained with Inference Catalyst for their food verdict workflow.
After a user scans a product, the model now delivers near-instant verdicts on what to watch out for, making the in-store experience faster and more seamless while cutting inference cost significantly.
Results:
- p50 latency: 2,721ms → 591ms
- p99 latency: 6,414ms → 998ms
- time to first word: ~0.25s
- inference cost: ~70% lower
Great working with @oliveholistic on this!
Full case study here: https://t.co/4j3rXJcrHU
@benhylak@hnshah Check out @inference_net We track every request across every provider and you get insight into the aggregated result and the cost of each individual inference.
3 weeks ago we open-sourced HALO
this led to talking with dozens of teams running agents at scale
we realized the current agent monitoring tools aren't built for the future that we so clearly see ahead of us
today we’re releasing native OpenTelemetry-compatible agent tracing on @inference_net, powered by the same open-source core behind HALO
We're releasing Schematron V2, a family of Specialized Language Models for converting messy HTML to structured JSON
frontier performance at 1/10th the cost
Schematron V2 was designed in partnership with some of the largest web-scraping companies in the world to meet the demands of their heaviest workloads
Schematron-V2-Turbo and Schematron-V2-Small are available today on @inference_net
Get started: https://t.co/8ojqgqnDqx
Introducing Catalyst: a developer platform to monitor, train & deploy self-improving AI models
built for teams operating AI products at scale
Catalyst can automatically:
- collect traces from your agents
- curate training data & evals
- train & deploy models on par w/ Opus 4.6
I’m hosting dinner parties again.
8-10 people, twice per month in San Francisco.
If you are a founder, and especially if you are NOT a founder, and you would like to come for an evening of good food and conversation, send me a DM
First dinner is March 27
@Anubhavhing Well this was already a thing with firecrawl and nothing huge happened so I don’t imagine this would be much different. Cloudflares also self identifies as a bot so can get blocked more easily. Schematron-3b is the best model for extracting good page data for the cost.
Day Zero fine-tuning & hosting support for Nemotron 3 Super by @nvidia is now live
Fine-tune on real production traces & deploy on high-performance infrastructure optimized for Nemotron 3 Super
Your data, your weights, your performance edge
Learn more: https://t.co/VoLBVnq49z
What if a codebase was actually stored in Postgres and agents directly modified files by reading/writing to the DB?
Code velocity has increased 3-5x. This will undoubtedly continue. PR review has already become a bottleneck for high output teams.
Codebase checked-out on filesystem seems like a terrible primitive when you have 10-100-1000 agents writing code.
Code is now high velocity data and should be modeled at such. Bare minimum, we need write-level atomicity and better coordination across agents, better synchronization primitives for subscribing to codebase state changes and real-time time file-level code lint/fmt/review.
The current ~20 year old paradigm of git checkout/branch/push/pr/review/rebase ended Jan 2026. We need an entirely new foundational system for writing code if we’re really going to keep pace with scale laws.
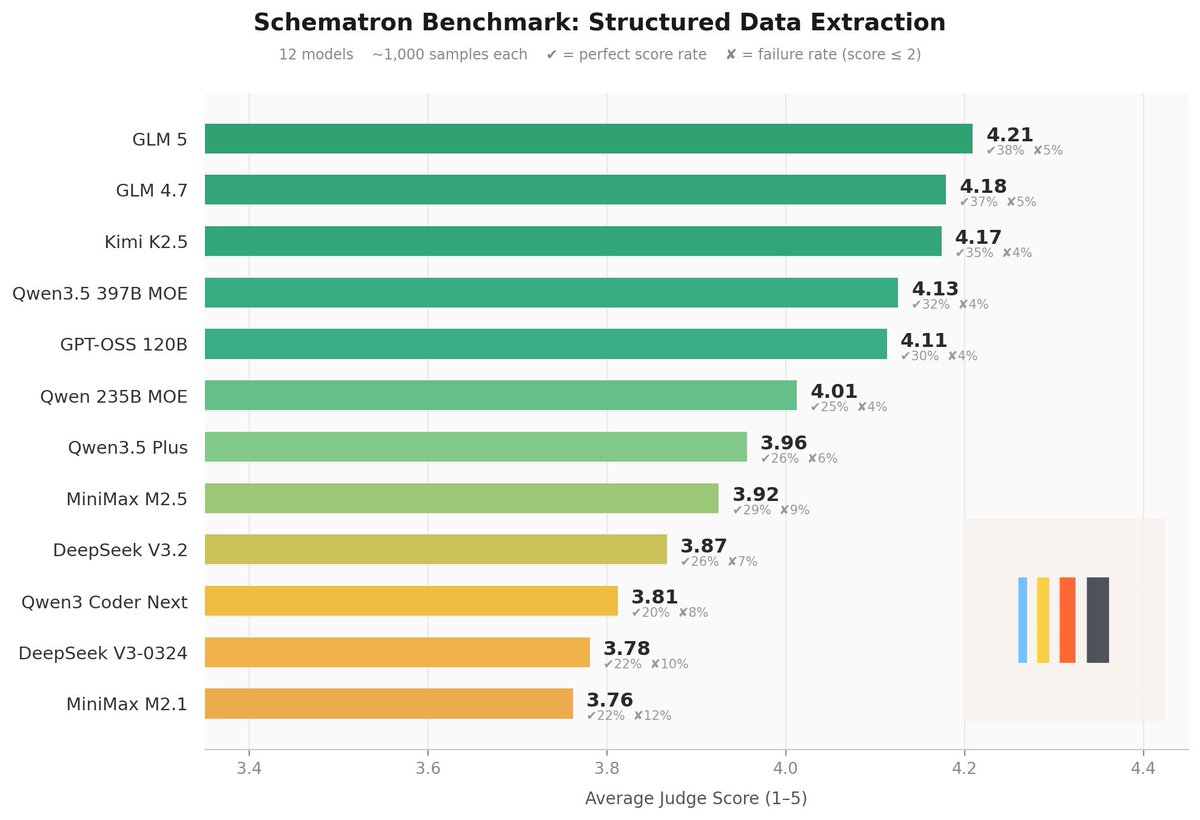
Introducing our new Schematron benchmark. We took some time to compare all of the latest open source models to see which one takes the crown.
The benchmark essentially measures the ability of LLMs to take raw HTML along with a JSON schema, and then fill out that schema. We measure things like recall/precision, hallucinations, and ability to handle ambiguity.
The benchmarks are graded with an ensemble of frontier models on a 5 point rubric.
We can see that GLM 5 is the best open source model currently for schema extraction. Surprisingly, GPT-OSS 120B does very well at these type of extraction tasks as well.
Another interesting result is we noticed degradation of quality using Qwen3.5 Plus on this task versus the original Qwen3.5 397B MOE.
The inputs can be up to 120K tokens, so this is akin to a long context benchmark, with an additional reasoning layer.
We will be open sourcing this benchmark if it gains sufficient traction. Also, more benchmarks coming from our side!