🐸 I just released opencode-froggy, a plugin for @opencode bringing #claudecode style hooks on top of #opencode.
```
hooks:
- event: session.idle
conditions: [hasCodeChange]
actions:
- bash: "npm run lint --fix"
```
https://t.co/Ptz5DcZuP9
#videcoding#aicode
If caching is unsupported, it would be useful to expose that explicitly in model metadata/pricing. If supported, could this be an accounting/reporting bug?
Hi @nebiustf, is prompt caching supported fo GLM-5.2 ?
In my tests:
- usage.prompt_tokens_details is null
- cached_tokens is never returned
- repeated long-prefix prompts are billed at full input-token price
-/v1/models?verbose=true does not expose cache support or cache pricing
glm-5.2 is built around 1M token context window. on long-horizon tasks, it stays more focused. on top of that, you can get a noticeably better experience it brings at the same price as before.
after some tests, we felt the more we use it, the smarter it feels. for example, you can keep digging, and it keeps hitting the mark. it can read a dozen of page contract and answer line by line. it can hold a persona across twenty turns without slipping...
I'll be showing some hands on impressions in this thread as I go. feel free to follow and would genuinely love to hear what you're seeing too:)
We somehow got put in the spotlight the last few days! First we'd like to thank the organizers of the AI show for that, we can't get enough of this stuff. I'll say a few things about where we are and what we do.
Over the past few months, we've launched Mistral Small 4, Medium 3.5, Voxtral STT, Voxtral TTS, and expanded Vibe to handle long-running, multi-step agentic workflows across work and code. The team has been pushing hard, and I'm incredibly proud.
Stay tuned! Exciting releases coming soon!
Deepseek pricing is what I’m looking for in all open (and closed) models. Xiaomi and Minimax have adopted this, and they have insane intelligence vs cost ratios rn.
1$/M out and 0.05$/M cache read
(These metrics are glm-5.1, NOT 5.2)
PS: I love glm5.1, its my default RLM model
Intelligence should be open, accessible, and ready to build with, empowering every developer, everywhere.
GLM-5.2 is now available to all GLM Coding Plan users, including Lite, Pro, Max, and Team plans.
https://t.co/AedZACyzej
As our new flagship model, GLM-5.2 delivers powerful coding capabilities, usable 1M-context support, and continued strengths in long-horizon tasks.
API and Chatbot services will launch next week. The model will also be officially open-sourced next week under the MIT License.
The future of AI is open, and it belongs to the people.
MiniMax M3, Open-Weight, Now On Hugging Face , with only ~428B parameters and ~23B activated parameters
Weights:
https://t.co/g4Ybfa2kWH
MiniMax Sparse Attention:
https://t.co/HcTlWRotG3
MiniMax M3, Open-Weight, Now On Hugging Face , with only ~428B parameters and ~23B activated parameters
Weights:
https://t.co/g4Ybfa2kWH
MiniMax Sparse Attention:
https://t.co/HcTlWRotG3
🌘 Kimi-K2.7-Code, our latest coding model, is now released and open-sourced!
🔷 Improved coding & agent performance over K2.6: +21.8% on Kimi Code Bench v2, +11.0% on Program Bench, and +31.5% on MLS Bench Lite.
🔷 Reasoning efficiency: Less overthinking, with 30% lower reasoning-token usage compared to K2.6.
🔷 Long-horizon coding: Improved instruction following, higher end-to-end coding task success rates.
⚡️ 6x High-Speed Mode coming soon!
🔌 Available today via Kimi API and Kimi Code.
🔗 Kimi Code: https://t.co/uvoSJKyGCY
🔗 API: https://t.co/EOZkbOwCN4
🔓 And the best part — we're open-sourcing it.
1,000+ tps on a 1T model wasn't a single breakthrough — it's deep model × system co-design between the MiMo and TileRT teams, all on general-purpose GPUs (no Cerebras-style wafer-scale, no Groq-style SRAM ASICs).
On the model side: FP4 quantization (smaller footprint, less memory traffic) + DFlash, our block-masked parallel speculative decoding that accepts far more tokens per verification. On the system side, TileRT tailors its compiler & kernels to exactly these techniques.
The result: a 1T model breaking 1,000 tps on a single, standard 8-GPU node.
🤗 Open weights (FP4 + DFlash checkpoint): https://t.co/jYQsgeruMg
A strong model evolution needs a solid harness system, and vice versa. 14 days, 5 people, one vibe-coding journey — and MiMo Code was born. It's open source: https://t.co/Yb0aPX5IOH
LLM routing benchmark 🧭
8 models classify dev requests (debug, review, codegen…) to route to the right model.
🏆 Accuracy: Gemini 3.5 Flash & Qwen 3.7 Plus - 97.5%. Qwen is 4× cheaper.
⚡ Trade-off: Gemini 3.1 Flash Lite , -1.7 pts, faster & cheaper: 802ms median.
Anthropic has released Claude Fable 5, the first publicly available Mythos-class model that ranks #1 in our agentic real-world knowledge work benchmark GDPval-AA
Claude Fable 5 shares the same underlying model as Claude Mythos 5, with added security guardrails for potentially harmful cybersecurity, biology, chemistry, and distillation-related queries. The release also introduces a fallback mechanism, allowing Claude Fable 5 to route flagged queries to a second model such as Claude Opus 4.8.
@AnthropicAI shared access with us ahead of public release to benchmark this model. Claude Fable 5 scores 1932 on GDPval-AA, our benchmark for agentic real-world work tasks, taking the #1 position and putting Anthropic models in 3 of the top 4 spots. The result was measured using adaptive reasoning at max effort, with Claude Opus 4.8 configured as the fallback model. Fable 5 falls back to Opus 4.8 on 2% of GDPval-AA tasks, with Anthropic stating that fallback occurs in fewer than 5% of sessions on average.
Full benchmarks for Claude Fable 5 are in progress - we will share the full Intelligence Index and publish scores on our website shortly
Meet Kimi Work - a local AI agent on your desktop that does the work for you.
🔹Native agent swarm: Up to 300 AI agents running in parallel on your local machine.
🔹Browser use: Paired with WebBridge extension, your agent will navigate websites in your browser: search, scroll, click, type and complete tasks.
🔹Built for Finance: Native global market data tool call from Yahoo Finance and World Bank - no complex API setup required.
🔹Memory system: Kimi Desktop keeps a running diary of your preferences, past decisions, and context to know you better.
Available for macOS (Apple Silicon) and Windows.
🔗Try it now: https://t.co/yhiai2VWIy
Macaron-V1-Preview-749B 👀 a Mixture-of-LoRA personal agent model from MindLab
✨ 744B base + 5 specialist LoRAs
✨ Generative UI as a core skill
✨ Personal agent focused
✨ 202K context
✨ MIT license
🌞This is big Local AI news! A new open-source Computer-Use LLM has just launched.
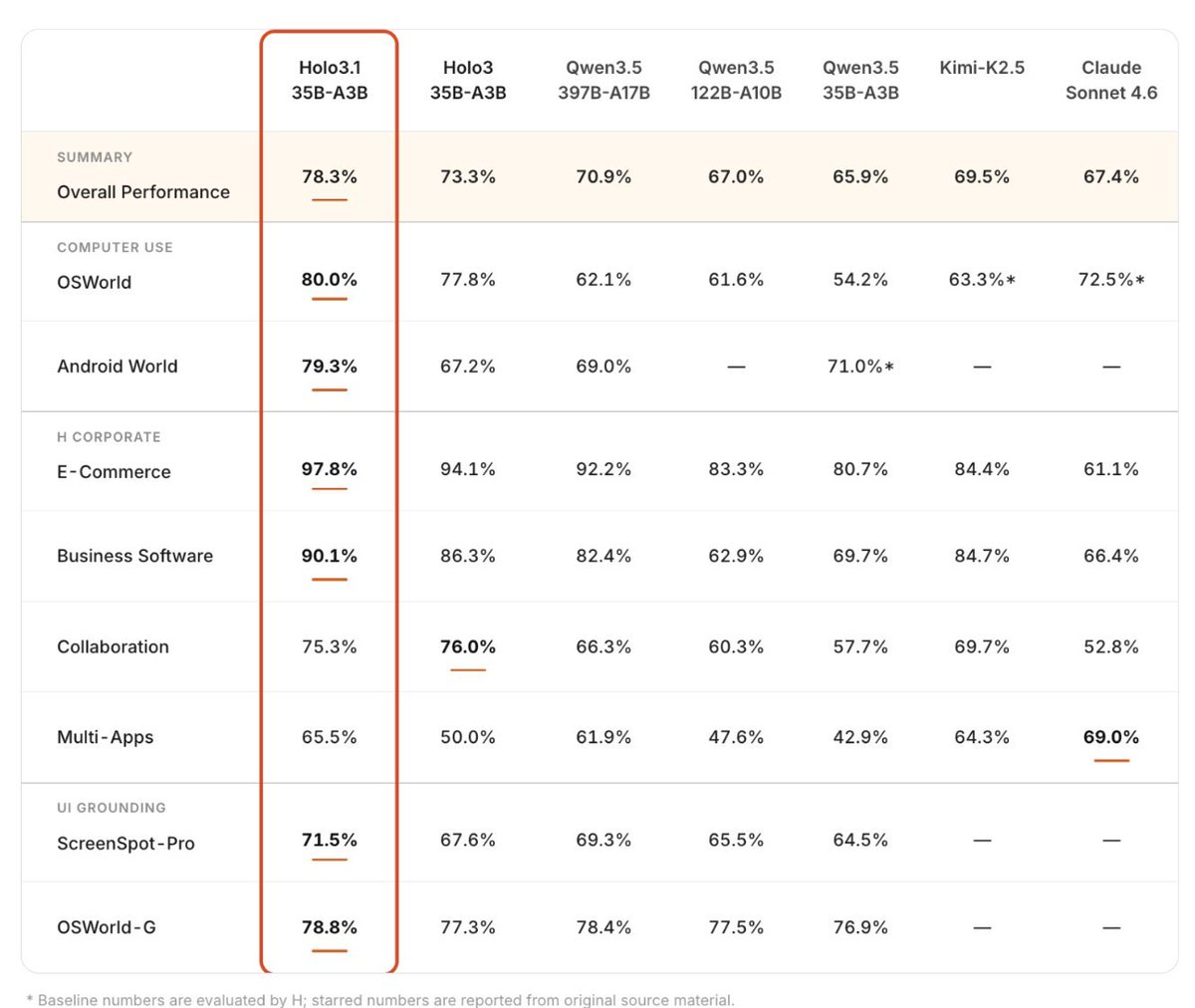
Holo 3.1 is H Company’s (🇫🇷) new local computer-use agent model that beats Qwen3.5-397B, Kimi-K2.5, and Sonnet 4.6!
Since it is built for local deployment →
⬩ Runs fully on your machine (MacBook, Windows PC, DGX Spark, RTX Spark)
⬩ Based on Qwen architecture, specialized for GUI understanding & computer control
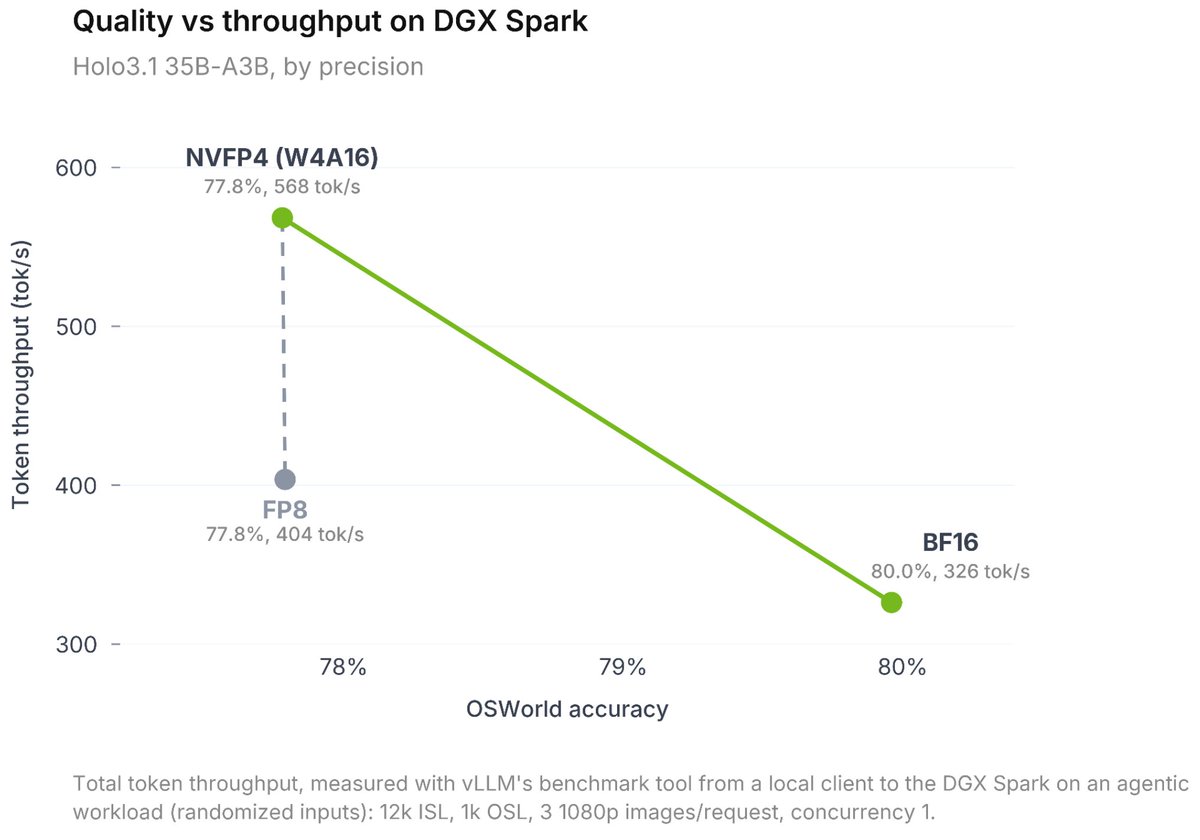
⬩ Optimized checkpoints: NVFP4, FP8 & Q4 GGUF (0.8B to 35B sizes)
⬩ Strong gains: 79.3% on AndroidWorld benchmark (35B model)
💻 Comparison to Qwen3.5:
Holo 3.1 is fine-tuned specifically for computer-use agents (screen understanding, planning, clicking, navigation). Better at real GUI tasks than general-purpose Qwen3.5, especially when running locally.⚡
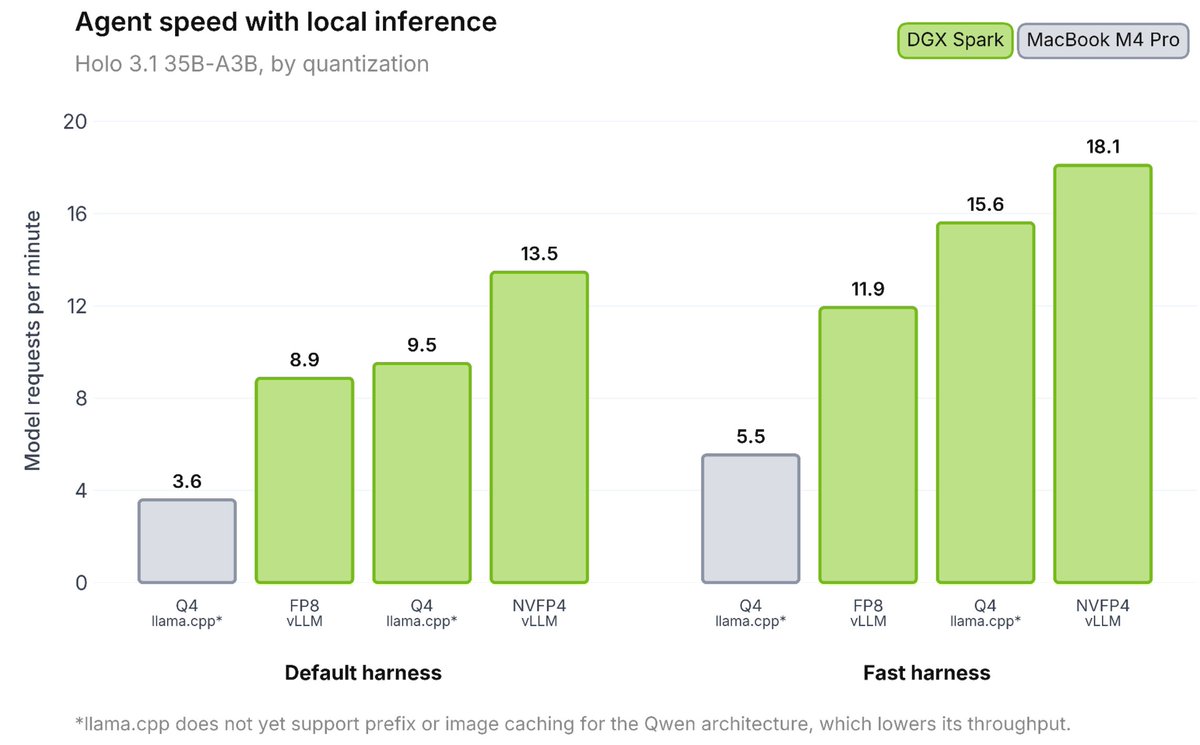
Computer-use agents are moving from the cloud to your local machine. Fast.
When we launched Holo3 two months ago, the production feedback was clear: digital agents need to be blazing fast, cost-effective, and versatile.
Today, we're dropping Holo 3.1, engineered to run anywhere, instantly.
Massive token throughput. Low latency. Ready for your local workflow!