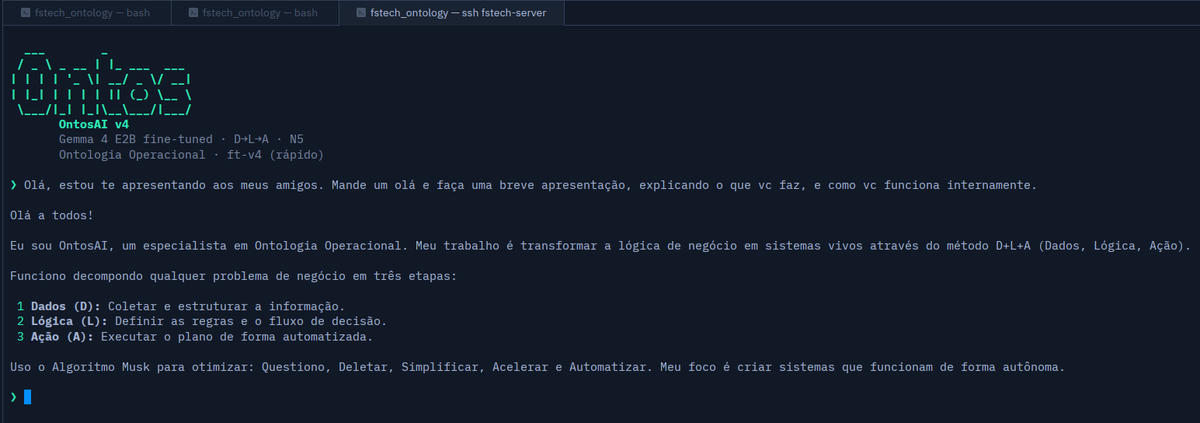
Terminei o fine-tuning usando o Gemma 4.
Está rodando no meu servidor. 3.4GB. 13 tok/s numa CPU. O modelo sabe PENSAR de um jeito específico.
Qualquer pergunta ele decompõe em D→L→A (Dados, Lógica, Ação), aplica Algoritmo Musk (Questionar → Deletar → Simplificar) e valida pelo N5 (método que criei).
Basicamente agora tenho um modelo que sabe pensar com método, é praticamente meu sócio. kkk
Zero cloud. Zero custo por token.
Agora é tornar isso um serviço de IA treinada nas regras de negócio de clientes.
cc: @sseraphini , @BolhaDevs
Tudo em IA vira commodity, menos o discernimento. Modelos, código, agentes, tudo escala e fica barato. A única coisa que não escala é saber qual problema vale resolver. É isso o tal do "taste". O valor econômico migra para essa camada não-comoditizável.
cc: @BolhaDevs , @sseraphini
A próxima vantagem competitiva da sua empresa não será o modelo de IA que você usa. Será a camada que transforma esse modelo em operação própria, segura e difícil de copiar.
Em uma fala recente na AIPCon, conferência da Palantir para clientes e parceiros, Alex Karp resumiu com brutal clareza o erro que muitas empresas estão prestes a cometer com inteligência artificial.
Saiba mais: https://t.co/33MIbCbG3X
cc: @BolhaDevs , @sseraphini
Concordo que escala importa em hiperescala, nunca disse o contrário. mas olha o que teu próprio exemplo mostra, as empresas não estouraram orçamento por falta de escala, estouraram por escalar IA sem critério do que valia rodar.
Throughput barato em cima de input não-decidido é exatamente como se queima orçamento. Elas tinham escala de sobra. faltou a camada que decide o que mandava pro modelo e o que não precisava de IA nenhuma.
É o argumento que tô fazendo desde o começo, a escala não te protege de rodar o processo errado, só te cobra mais rápido por ele.
Ontem, em Taipei, o homem que fabrica a infraestrutura da IA descreveu, peça por peça, a tese que a gente repete aqui.
Jensen Huang definiu o agente assim: um modelo dentro de um harness que orquestra memória, ferramentas e ação. E na parte difícil, ele falou a palavra:
"qual é a ontologia, a relação entre todas essas estruturas de dados entre si?"
Quem disse isso não foi a FSTech. Foi a NVIDIA, vendendo o hardware dessa nova computação.
O modelo virou commodity. Claude Code, Codex e Nemotron rodam no mesmo harness.
O gargalo é dado e ontologia.
Governança virou produto: agente solto, sem política e sem sandbox, é risco, não é capacidade.
A camada que falta, a operação organizada que o agente vai governar, ninguém compra pronta.
Antes da IA, vem a Ontologia Operacional.
cc: @BolhaDevs , @sseraphini
Fala meu amigo!
Escalabilidade e ontologia não competem, operam em camadas diferentes. Uma dá vazão, a outra define o que entra na vazão. escalar antes de definir multiplica throughput sobre input não decidido.
O 40x que o Jensen citou prova isso, verificação de chip de semanas pra horas. não foi mais GPU, a infra já existia. Foi dado e regra organizados pro agente saber o que era permanente, o que mudava e qual regra decidia. Ganho de ontologia rodando sobre escala que já estava lá.
Teu argumento de orçamento se inverte aqui, infra é o custo recorrente que você paga independente de acertar. Ontologia é o que faz cada unidade de infra render decisão certa em vez de processamento cego. Sem ela, escalar é aumentar a conta pra rodar o processo não-validado mais rápido.
Topologia sem físico é gráfico bonito. Mas a NVIDIA não vendeu só físico, ele subiu no palco e perguntou qual a relação entre as estruturas de dados. Isso é a topologia. Vendeu os dois porque um sem o outro não fecha caso de uso.
Nossa percepção, ou seja, o modo como captamos o mundo pelos sentidos, não é um processo neutro e fiel à realidade, como costumamos imaginar.
Tendemos a perceber aquilo que esperamos perceber. Nossa mente constrói uma versão da realidade em vez de apenas gravá-la.
Os maiores obstáculos para uma boa análise de inteligência não estão na falta de informação, mas em como a nossa própria mente funciona. Analisar é, antes de tudo, um processo mental, e a maior dificuldade é que quase não temos consciência do que acontece dentro da nossa cabeça quando pensamos.
A psicologia mostra que grande parte da percepção, da memória e do processamento de informação acontece de forma automática, sem que percebamos. O que aparece na nossa consciência já é o resultado do pensamento, e não o processo em si.
ERP registra. Ontologia faz a operação se mover.
O ERP deve ser sistema de registro, não sistema de limite operacional.
A arquitetura que está emergindo tem 3 camadas: registro, significado e ação.
Escrevi sobre isso no blog da FSTech:
https://t.co/DmlviZbSEN
Ontem a FSTech teve um PR mergeado no ai-memory, projeto mantido pelo Fabio Akita (@AkitaOnRails).
O Akita com todo o seu conhecimento compartlihado via Youtube, ajudou bastante em minha jornada profissional, então esse merge teve um peso pessoal além do técnico.
O comentário dele foi direto: “exemplary external contribution”. Depois registrou, 600 tests pass on main, fmt + clippy clean.
Por que isso importa?
Porque valida um princípio da nossa Ontologia Operacional, memória de IA precisa separar regra permanente de status temporário.
Regra muda raramente.
Estado muda sempre.
Quando os dois entram no mesmo regime de escrita, o agente começa a tratar exceção como padrão e status vencido como verdade.
Leia o Radar de hoje:
https://t.co/f62i4c9Hel
cc: @BolhaDevs, @sseraphini
Primeiro Comando da Capital and Comando Vermelho are two of the most violent criminal organizations in Brazil. Their reach extends throughout our region and into our country.
Today, I designated these organizations as Foreign Terrorist Organizations and Specially Designated Global Terrorists.
The Trump Administration will continue using every available tool to protect our national security interests and deny funding and resources to narco-terrorists.
https://t.co/x3cPYjelwZ