🎉[openings] I’m hiring postdoctoral researchers to join our @FunAILab at UTN through the Alexander von Humboldt Research Fellowship (@AvHStiftung), via the Henriette Herz Scouting Programme.
As a Henriette Herz Scout, I can nominate outstanding international researchers for this fellowship route. I’m especially keen to hear from candidates working on multimodal learning, video and image pretraining, and post-training.
Fellows would be hosted in our lab at UTN and work closely with us on these topics.
Key requirements:
* finished your doctoral studies less than 4 years ago or will finish in the next 6 months
* did not live/work in Germany in the last 10 years
* applications from female, trans* and/or non-binary candidates are highly encouraged!
Interested? Please send a short note with your CV, PhD year, current affiliation, 2–3 key publications, and a few lines on how your work connects.
Please share! 🔀
Today we visited Japan's hottest AI startup @SakanaAILabs🎏🇯🇵!
We met their research scientists and discussed the implications and impact of some their works like "The AI scientist" and "Continous Thought Machines".
We presented our @FunAILab works, "Better Language Models Exhibit Higher Visual Alignment" and "Data Repetition Beats Data Scaling in Long-CoT Supervised Fine-Tuning". Got lots of cool questions and discussions! Thanks, Masanori Suganuma, @_yutaroyamada, @ciaran_regan_
Start of our workshop, organised by our postdoc fellow @FragileGoodwill!
Today we'll be getting to know each other's research directions and make some personal connections!
@AIST_EN, @TUS_PR_en, and @noagarciad and more: https://t.co/yDS9DCvZth
'cc @HirokatuKataoka
[new CVPR'26 paper]
🔄 SSL works great when you have tons of data.
But in 3D… we don’t.
High-quality 3D scans are expensive, slow, and hard to scale. So what if we could pretrain 3D models without any real 3D scans? 1/
Happy to share what we've been cooking! 🎊🎊
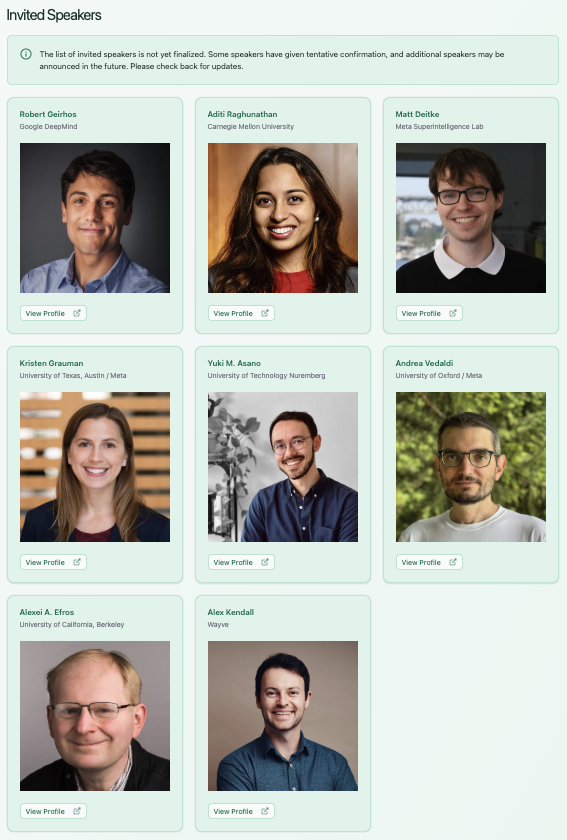
Our next iteration of the ELLIS PhD school is set to be an *absolutely amazing* one with this stellar lineup of speakers. ..And we even have some more speakers to be confirmed. 👀
If you haven't yet, go apply :)
Now finally accepted at @emnlpmeeting!
I think the technique and high-level ideas i) allow bidirectional attention for prompt & ii) (maybe) process input-query differently from answer generation will stick around.
Today we release Franca, a new vision Foundation Model that matches and sometimes outperforms DINOv2.
The data, the training code and the model weights (with intermediate checkpoints) are open-source, allowing everyone to build on this.
Methodologically, we introduce two new SSL components, one is a multi-granularity SK clustering loss that utilizes Matryoshka representations and a quick post-pretraining scheme to remove unwanted spatial biases.
This is the result of a close and fun collaboration @valeoai (in France) and @FunAILab (in Franconia)
Hello FunAI Lab at UTN 👋
I’m excited to start a new chapter of my research journey here in Nuremberg as a visiting postdoc.
Excited for inspiring collaborations and impactful research ahead with @y_m_asano and the amazing students😀
LoRA et al. enable personalised model generation and serving, which is crucial as finetuned models still outperform general ones in many tasks. However, serving a base model with many LoRAs is very inefficient! Now, there's a better way: enter Prompt Generation Networks, presented today @BMVCconf
Is the community trying to surprise us today? 🤯
Because these benchmark-related papers from different research labs all dropped on the Daily Papers page at once! 🎉📑https://t.co/vE0f1FcZwF
✨ LOKI: A Comprehensive Synthetic Data Detection Benchmark using Large Multimodal Models by Opendata lab
✨ MMIE: Massive Multimodal Interleaved Comprehension Benchmark for Large Vision-Language Models by @richardxp888
✨ MEGA-Bench: Scaling Multimodal Evaluation to over 500 Real-World Tasks by the TigerLab
✨ LiveXiv -- A Multi-Modal Live Benchmark Based on Arxiv Papers Content by @TelAvivUni@IBMResearch
✨ Omni-MATH: A Universal Olympiad Level Mathematic Benchmark For Large Language Models by @PKU1898@AlibabaGroup
✨ TemporalBench: Benchmarking Fine-grained Temporal Understanding for Multimodal Video Models by @MuCai7
✨ LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory by @DiWu0162@TencentGlobal
✨ TVBench: Redesigning Video-Language Evaluation by @FunAILab@_akhaliq
Today, we're introducing TVBench! 📹💬
Video-language evaluation is crucial, but are we doing it right? We find that current benchmarks fall short in testing temporal understanding. 🧵👇




















![y_m_asano's tweet photo. 🎉[openings] I’m hiring postdoctoral researchers to join our @FunAILab at UTN through the Alexander von Humboldt Research Fellowship (@AvHStiftung), via the Henriette Herz Scouting Programme.
As a Henriette Herz Scout, I can nominate outstanding international researchers for this fellowship route. I’m especially keen to hear from candidates working on multimodal learning, video and image pretraining, and post-training.
Fellows would be hosted in our lab at UTN and work closely with us on these topics.
Key requirements:
* finished your doctoral studies less than 4 years ago or will finish in the next 6 months
* did not live/work in Germany in the last 10 years
* applications from female, trans* and/or non-binary candidates are highly encouraged!
Interested? Please send a short note with your CV, PhD year, current affiliation, 2–3 key publications, and a few lines on how your work connects.
Please share! 🔀](https://pbs.twimg.com/media/HHKGfgWXoAA-4Ga.jpg)




![y_m_asano's tweet photo. [new CVPR'26 paper]
🔄 SSL works great when you have tons of data.
But in 3D… we don’t.
High-quality 3D scans are expensive, slow, and hard to scale. So what if we could pretrain 3D models without any real 3D scans? 1/ https://t.co/73EFPE6iFH](https://pbs.twimg.com/media/HEpq_KjXAAEUaXD.jpg)

































