@ZechenZhang5 I like the idea a lot, my recent agent work requires commits for all artifacts so we can reproduce/investigate all previously claimed results.
I'm interested in search extending this system. We want to be able to find things we remember and explore on top of just reproducibility
This is similar to implicit CoT work, which is all pretty cool stuff. But this is a new way to internalize reasoning and a new control mechanism over performance.
Check out the paper for details and the ablations that narrow down explanations!
I use task arithmetic/model merging to limit degradation (0.25 * SFT) and during evaluation, I noticed that with <cot>, the model doesn't reason out loud, but removing <cot> still degrades performance.
Thus, internalized reasoning.
I made a paper!
https://t.co/MnHn1ritGs
Essentially:
Extract evidence from pages and sort the top K to make a reasoning trace.
Add in a control token and we can turn it on or off.
Internalize with model merging.
So, I used a control tok - <cot> - and trained the model without the CoT when it is not in the prompt.
If you train entirely without the synthetic CoT traces, it performs **very** similarly to not prompting <cot>.
So, the model can turn the internalized algorithm on or off? Cool
I also trained two versions of the models, one with the mixed think + non-think examples and one with only non-think examples.
I evaluate both versions with and without the <cot> token in the system prompt:
When building examples, I make most examples with a control token <cot> in the system prompt. These examples include the reasoning trace.
This gives me a switch that affects the model's reasoning or path to the answer.
There are two exclusive branches next:
- Vision: receives the sorted pages and the question only
- Text: sorted, extracted evidence, the question, and context on the input (ties the answer causally to the reasoning reasoning trace).
Both branches generate a final answer.
This seems to be key to getting good performance. The first version just had each page's evidence from the whole document (some pages as "irrelevant"), but during inference, the model tends to loop on "irrelevant".
I believe the model learns v2's RAG-like algorithm.
Thus, ground truth pages are ~always marked relevant, with some score flexibility.
I filter for scores above a threshold, sort the pages + their evidence from greatest to least and take the top K (16).
I take a document and a synthetic question. For each page, I task a VLM with extracting evidence relevant to the question, along with a relevance score in [0.0, 10.0].
If the page was used to generate the question, I prompt the model to score between [6.0, 10.0].
I trained Qwen3 VL 32B to a new SOTA on MMLongBenchDoc, 58.3 (leaderboard update coming soon).
I also trained Mistral Small 3.1 24B and the method is highly impactful across both models.
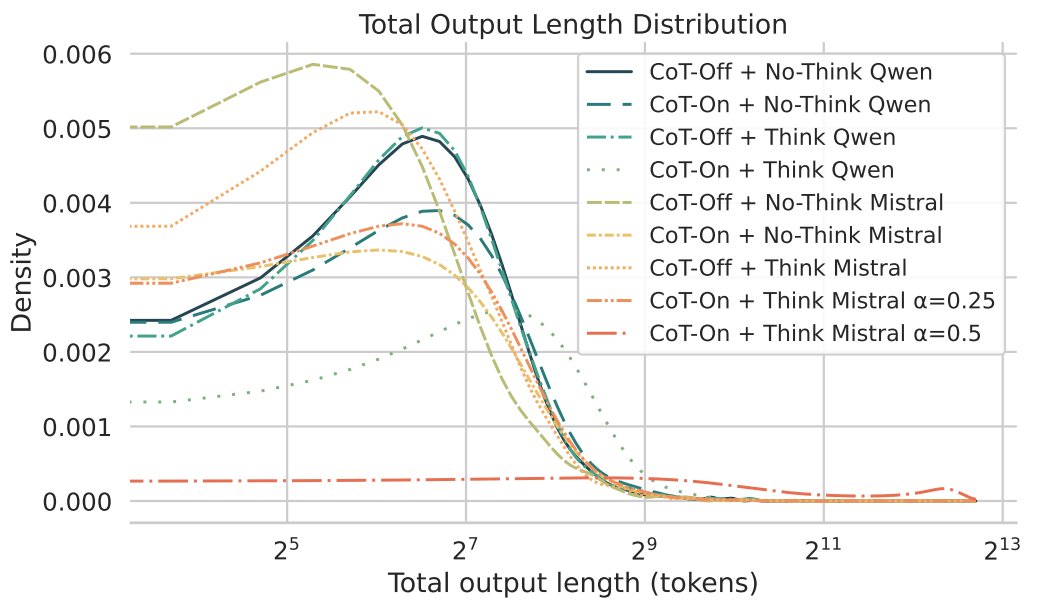
These models are also very token efficient. Here's a little more detail on how it works:
@thsottiaux Code can be 10x as many lines as needed with hasattr()s, .get()s , etc. and it raises errors for everything (assert isinstance(count, int), "3 line message") even when we fully know that count is an int. These waste space with insanely defensive code and it can fallback silently
Excited to share my work "How to Train Your Long-Context Visual Document Model." (https://t.co/oE5WTVIHbZ)
Research and recipes for training long-context VLMs for document understanding is entirely lacking. In this paper, I explore this frontier with extensive ablations.
For reproducibility and open insights, I am releasing a full leaderboard of my training runs with data recipes included for the community to explore!
Please enjoy
https://t.co/7Jn9BjVYay



![further_ai's tweet photo. I take a document and a synthetic question. For each page, I task a VLM with extracting evidence relevant to the question, along with a relevance score in [0.0, 10.0].
If the page was used to generate the question, I prompt the model to score between [6.0, 10.0]. https://t.co/tybyIft4nc](https://pbs.twimg.com/media/HFcjV0kXUAAEBUz.jpg)






























