Companion to the Future Salon: Proudly creating a world that works for all. Following all Future Salon presenters on Twitter. Founded and hosted by @finnern
"The seven deadly curses of superhuman AI" is an unusually good and faithful view into part of our argument. Kudos to the animators. https://t.co/pHgTxxi8Nn
"There is nothing special about Elon Musk, Sam Altman, or Mark Zuckerberg. Accepting that requires you to also accept that the world itself is not one that rewards the remarkable, or the brilliant, or the truly incredible, but those who are able to take advantage of opportunities, which in turn leads to the horrible truth that those who often have the most opportunities are some of the most boring and privileged people alive."
-@EdZitron, You Can't Make Friends With The Rockstars
https://t.co/6KWThnQZv7
The #NobelPrizeinPhysics2024 for Hopfield & Hinton rewards plagiarism and incorrect attribution in computer science. It's mostly about Amari's "Hopfield network" and the "Boltzmann Machine."
1. The Lenz-Ising recurrent architecture with neuron-like elements was published in 1925 [L20][I24][I25]. In 1972, Shun-Ichi Amari made it adaptive such that it could learn to associate input patterns with output patterns by changing its connection weights [AMH1]. However, Amari is only briefly cited in the "Scientific Background to the Nobel Prize in Physics 2024." Unfortunately, Amari's net was later called the "Hopfield network." Hopfield republished it 10 years later [AMH2], without citing Amari, not even in later papers.
2. The related Boltzmann Machine paper by Ackley, Hinton, and Sejnowski (1985) [BM] was about learning internal representations in hidden units of neural networks (NNs) [S20]. It didn't cite the first working algorithm for deep learning of internal representations by Ivakhnenko & Lapa (Ukraine, 1965)[DEEP1-2][HIN]. It didn't cite Amari's separate work (1967-68)[GD1-2] on learning internal representations in deep NNs end-to-end through stochastic gradient descent (SGD). Not even the later surveys by the authors [S20][DL3][DLP] nor the "Scientific Background to the Nobel Prize in Physics 2024" mention these origins of deep learning. ([BM] also did not cite relevant prior work by Sherrington & Kirkpatrick [SK75] & Glauber [G63].)
3. The Nobel Committee also lauds Hinton et al.'s 2006 method for layer-wise pretraining of deep NNs (2006) [UN4]. However, this work neither cited the original layer-wise training of deep NNs by Ivakhnenko & Lapa (1965)[DEEP1-2] nor the original work on unsupervised pretraining of deep NNs (1991) [UN0-1][DLP].
4. The "Popular information" says: “At the end of the 1960s, some discouraging theoretical results caused many researchers to suspect that these neural networks would never be of any real use." However, deep learning research was obviously alive and kicking in the 1960s-70s, especially outside of the Anglosphere [DEEP1-2][GD1-3][CNN1][DL1-2][DLP][DLH].
5. Many additional cases of plagiarism and incorrect attribution can be found in the following reference [DLP], which also contains the other references above. One can start with Sec. 3:
[DLP] J. Schmidhuber (2023). How 3 Turing awardees republished key methods and ideas whose creators they failed to credit. Technical Report IDSIA-23-23, Swiss AI Lab IDSIA, 14 Dec 2023. https://t.co/Nz0fjc6kyx
See also the following reference [DLH] for a history of the field:
[DLH] J. Schmidhuber (2022). Annotated History of Modern AI and Deep Learning. Technical Report IDSIA-22-22, IDSIA, Lugano, Switzerland, 2022. Preprint arXiv:2212.11279. https://t.co/Ys0dw5hkF4 (This extends the 2015 award-winning survey https://t.co/7goTtI5Uwv)
The sooner we pivot the critical discussion away from “the issue with AI is that it is isn’t broadly useful to many jobs” to “what are the implications of AI being broadly useful to many jobs,” the sooner we can start to mitigate negative impacts & focus on positive use cases
The fact that an AI system is designed [trained] to imitate human output [given corresponding input] is not an argument against it being intelligent or conscious. From an evolutionary perspective, humans are the result of end-to-end training to mimic human behavior, too.
On Nat Friedman's first day as CEO of Github, at 9am, he had meeting with his leadership team over Zoom.
They were probably expecting a long term strategy, but instead he shared his screen and pulled up a GitHub repo where users could submit and vote on product feedback.
He said "we're going to pick one thing from this list, and fix it by the end of the day."
He initially got pushback that it wasn't possible. But ultimately they found something that would work, and they shipped it that day.
Then he said, we're going to do this again, every day, for the next 100 days.
What did this accomplish?
1. It built trust with their customers: "We needed to show the world we cared about developers, not that we care about Microsoft. If the first thing we did was add Skype integration, developers would have said 'we're not your priority'."
2. It built excitement internally about shipping: "Github was a company that had a little bit of stage fright about shipping, so when we broke that static friction it felt great."
3. It helped Friedman ramp up as leader: he quickly figured out which teams were standouts, where there was a lot of tech debt, which stuff they shipped was good and which was bad.
The big strategy (including becoming a leader in AI) would follow. But first, he shipped 100 things.
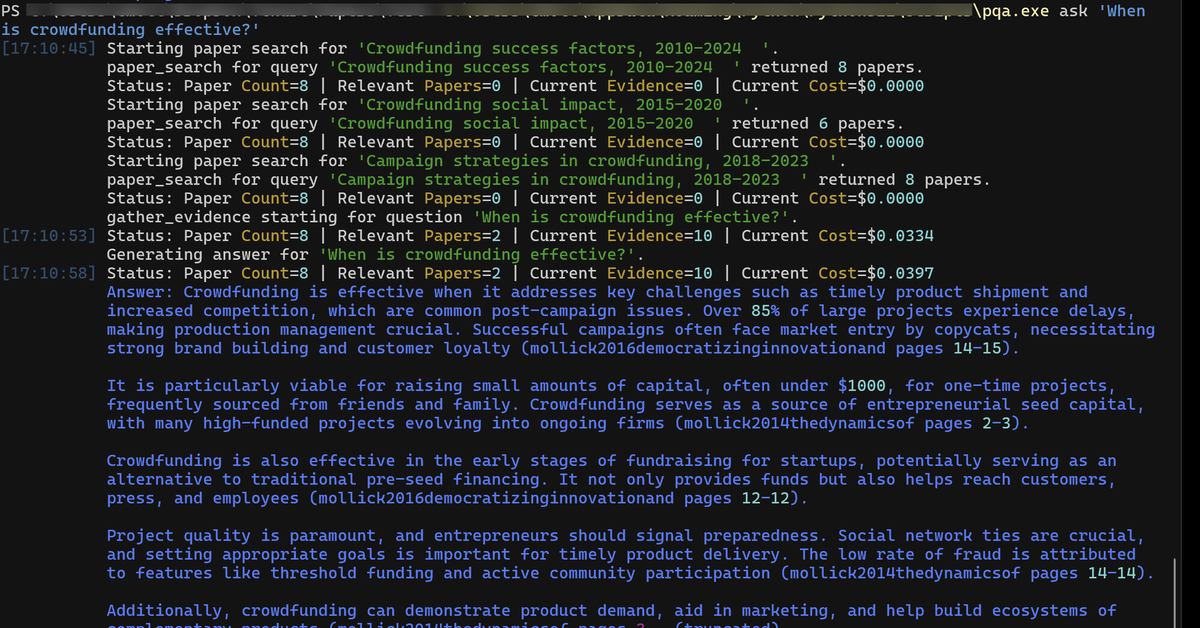
Wow: Just tried PaperQA, an open source AI-powered literature review whose research paper claims it achieves "superhuman synthesis of scientific knowledge"
I tested it against papers I wrote and it seems like the real deal, putting together a good summary with accurate details.
High praise: ASML, the sole provider of advanced chip litho tools, has adopted my Moore's Law abstraction.
Building on Kurzweil's work, I think it is the most important thing ever graphed. It covers a 10,000,000,000,000,000,000x improvement in computation/$ over 125 years.
ASML converted every data point into their slide format, and Jos Benschop, SVP of Technology at ASML, presented it today in his opening talk at IMEC in Leuven: https://t.co/cbzlFlfDdr
My original 𝕏 post on the 125-year version of Moore's Law:
My earlier post on the history of lithography and the semi industry: https://t.co/btb5QSSBr7
Why I don't yet use AI for more than 10 lines of code
By a many decades experienced coder.
The two iron pillars of coding:
Does it work?
Is it easy to change? <- there's a lot packed in here
1) I've never met anyone using Replit or seen it used by a YouTuber. No shade. Just what I see. It could be amazing.
2) the buzz around AI coding reminds me of the endless new framework demos, always promising to do more for you but playing to WYSIATI bias. In practice, each framework took almost as much productivity as it gave, which is why there are endless frameworks!
It's an illusion.
3) I love using AI, it is the best thing to hit coding. But the productivity gain comes from already being a very experienced coder. The best two things are a) rapidly learning new things, explain or spot why something doesn't compile, explain errors, b) having it write boilerplate or do brainless work, one time work, scaffolding. It quickly stops being useful the larger the app gets. There are tools for much of this anyway.
Larger apps already have all the reusable code written. As coders, our job is to write everything once, and reuse it, and share it to the team, world. So we get faster and faster as we build up the pieces.
4) there's a trope that adding coders to software slows it down. Too much to say on why this is, but keep it in mind what happens when adding an agent that'll be writing spaghetti, code that needs understanding, changing.
5) many problems in code are about getting logic way over here working with code on the other side of the codebase, without breaking anything. The other big problem is designing/coding in a way that will make this fundamental problem easier in the future.
6) we've had "code we didn't write" for years, they're called libraries or packages. We now have a choice; code it ourselves with AI (and create a lib?), or use an existing library. The proliferation of OS libs has been awesome, but never killed coding, though libs made life easier for people to learn to code.
7) most people don't like coding nor have sufficient interest, detail orientation, ability to deal with the learning curve/pain barrier, IQ, deep focus on a screen, sitting all day, anti-socialness, playing 3D chess, everyday, continually relearning. Similarly, I don't want to e.g. play tennis all day, every day, or work on car engines.
8) it's possible that agents may collaborate to grow a codebase when paired with test/QA/visual agents like adversaries, but...
9) by far the BIGGEST barrier to me using AI is simply that to understand someone else's code takes longer than writing it yourself.
Thinking == Writing.
Even if I read someone else's code, I don't remember it like I wrote it, because I didn't do the deeply creative thinking around it.
That's the no.1 problem.
Developers are "shared understanders". We know what can be done and converse with colleagues, users, managers, because we deeply know how the system works, line by line, and how much change is needed, what is possible.
Regular employees coding is banned in most companies because no one understands how it works except them.
Developers hate it when they pick up an employee-made system because it's unpleasant to read, try and learn how it works, and it's impossible to change because designing for change is the hard thing of coding.
So long as no one will ever have to maintain and edit large AI codebases, you're good, but if humans are in the loop, then we need to know how it works, and that means spending as much time as if we wrote the code in the first place. The other world might be that the AI has all the code in its context and is invited to all the meetings.
The biggest threat to us developers is the collapse of the workflows of all our users which will negate the need for the software in the first place.
For this, we need to consider why we write an app: Data input, decision support, reporting, visualisation, guiding rails, regulation and record keeping, audit, access control. And consider the human form factor: eyes, ears, fingers, voice, limited memory, fallible/careless.
I think many devs today will tear into the world's hard problems, tomorrow. Atoms not bits.
AI is a bicycle for the bicycle for the mind. It multiplies what you already know and what you're already like.
Ok, my mind is blown with Replit Agents.
I started using it because I was bored on a train ride a couple of days ago.
So today I tried to build a Trello clone and build a fully functional app in like 45 mins.
I showed it to a few people in the office and the guy is like "I should quit my job." He built a stock tracking app in 2 mins and added a few features he wanted.
I can't imagine the world being the same in 10 years if software writing could be supercharged like this.
Replit has really hit it out of the park.
I don't need ChatGPT now. I'll just build apps in Replit.
I'm a fan and a convert.
There is a set of careful papers examining the ability of AI to help forecast future events. They show that human forecasters using AI outperform humans alone & that “crowds” of AIs are as good as crowds of human forecasters, but also that individual LLMs are not good forecasters
We have increasing evidence that today's AIs can, indeed, generate novel ideas
This paper shows that the AI generates research ideas that are more novel and exciting (to other researchers!) than experts in the field, with no significant difference in the idea's feasibility.
We are absolutely at a place where, if AI development completely stopped, we would still have 5-10 years of rapid change absorbing the capabilities of current models and integrating them into organizations and social systems.
I don't think development is going to stop, though.
I can hardly believe what I'm reading here: an LLM that fixes its own bugs, corrects itself and beats all current models, including GPT-4o in all benchmarks? And the model is still OpenSource?
"It's the top LLM in (at least) MMLU, MATH, IFEval, GSM8K. Beats GPT-4o on every benchmark tested. It clobbers Llama 3.1 405B. It's not even close."
The 405b model is coming next week! What's happening right now?
Khanmigo, Khan Academy's $99/year Generative AI, teaches kids how solve math and reading problems, how to debate, and the AI takes on personas of many historical and literary figures, allowing conversational inquiry, debate, and learning. Khanmigo typically answers a question with another question, one that contains a hint of the answer, and the kind of thinking that builds active inference, logic, and critical thinking skills. Socratic pedagogy, and the kids seem to like it too. Are your kids using it yet? #Foresight https://t.co/31qXFafynL
Always demand a deadline because it weeds out the extraneous and the ordinary. A deadline prevents you from trying to make it perfect, so you have to make it different. Different is better. #excellentadvice
The future of AI is neurosymbolic.
#longread about @GoogleDeepMind’s new work (cc: @demishassabis) that is easily the most positive and important essay I have written this year.
If you care about what happens in AI after the generative AI bubble bursts, please have a look.