Exciting news: Claude Fable 5 ranks #1 on the new Agent Arena leaderboard!
Fable 5 leads by the widest margin ever over Opus-4.8 and GPT-5.5 on two key signals: confirmed task success rate and praise vs. complaint, despite weaker steerability. If Fable can do something, it will do it very well. If it can't/doesn't want to do something, it may be hard to steer the model towards the goal.
In Agent Arena, we measure models on millions of real-world, long-horizon agentic tasks. Models get web search, filesystem, and terminal tools to complete complex workflows: writing code, creating slide deck, researching the web, building apps, and analyzing documents.
We use the causal tracing methodology to measure a model's net improvement which indicates how much it improves outcomes relative to the average model.
Huge congrats to @AnthropicAI for the incredible milestone! Below we break down how Claude Fable 5 (based on Mythos) scored across 5 signals, drawn from tasks submitted by a global community of users.
Introducing Agent Arena: real-world agentic evals at scale.
How do you evaluate agents doing actual work? We measure millions of live sessions where real users accomplish real tasks.
On Arena, models now get web search, filesystem, and terminal tools to complete complex workflows: writing code, creating slide deck, researching the web, building apps, and analyzing documents.
Every session produces rich signals. Users iterate with the agent turn-by-turn: approving, editing, correcting, praise or expressing frustration. The environment gives feedback too: shell errors, tool failures, recovery attempts, and more.
Our leaderboard measures each model's agentic performance using causal inference across five signals: task success, steerability, error recovery, user praise vs. complaint, and tool hallucination.
This leaderboard snapshot is built from 300K+ tasks, 2M+ tool calls, and 40M lines of code by agents.
Top labs in Agent Arena:
- #1 @OpenAI: GPT-5.5 (High)
- #2 @AnthropicAI: Claude-Opus-4.7 (Thinking)
- #3 @Zai_org: GLM-5.1
- #4 @GoogleDeepMind: Gemini-3.1-Pro
- #5 @Kimi_Moonshot: Kimi-K2.6
More analysis in the thread, with the full technical blog below.
Introducing Agent Mode: Agentic AI is now measured in the Arena.
Agent Mode can do deep research, create reports, generate images, build websites, debug code, and more.
It completes more complex tasks by using tools like web search, bash in a sandbox environment, image generation, file writing, and asking follow-up questions.
Frontier models are waiting for you in Agent Mode to take on real-world tasks. GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro, and top open models. Test them yourself.
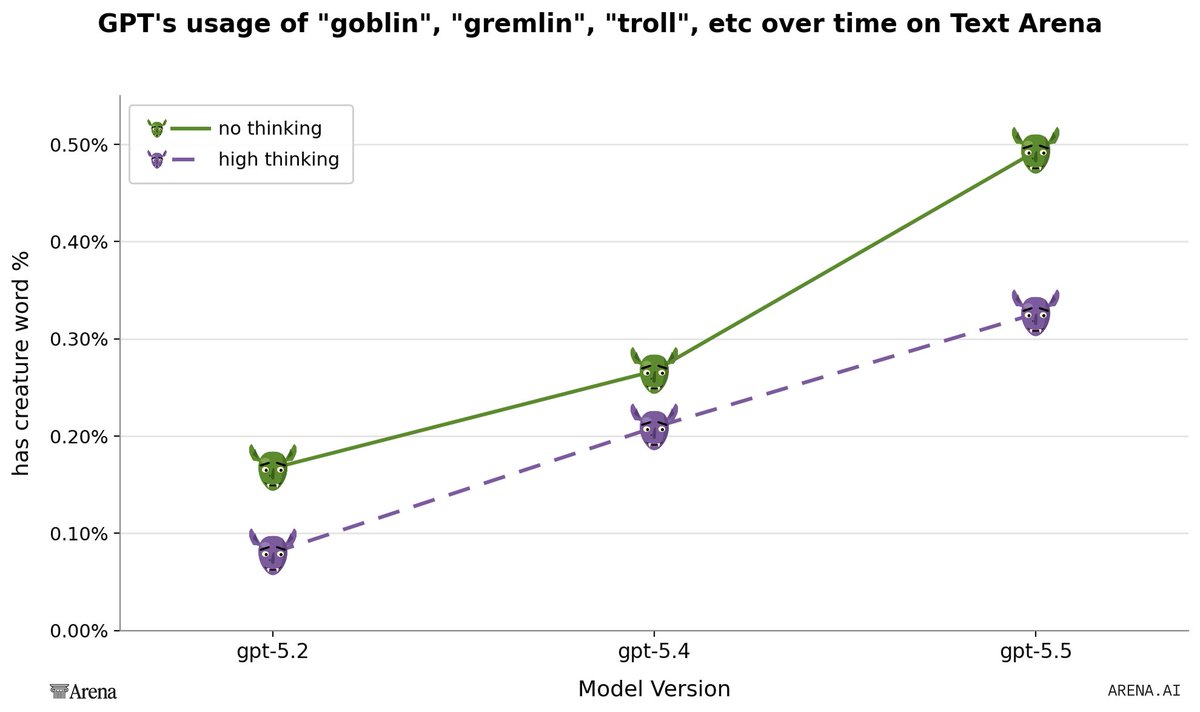
It's true. Here's a plot of GPT models and their usage of "goblin", "gremlin", "troll", etc over time. There's no anti-gremlin system instruction on our side, we get to see GPT-5.5 run free.
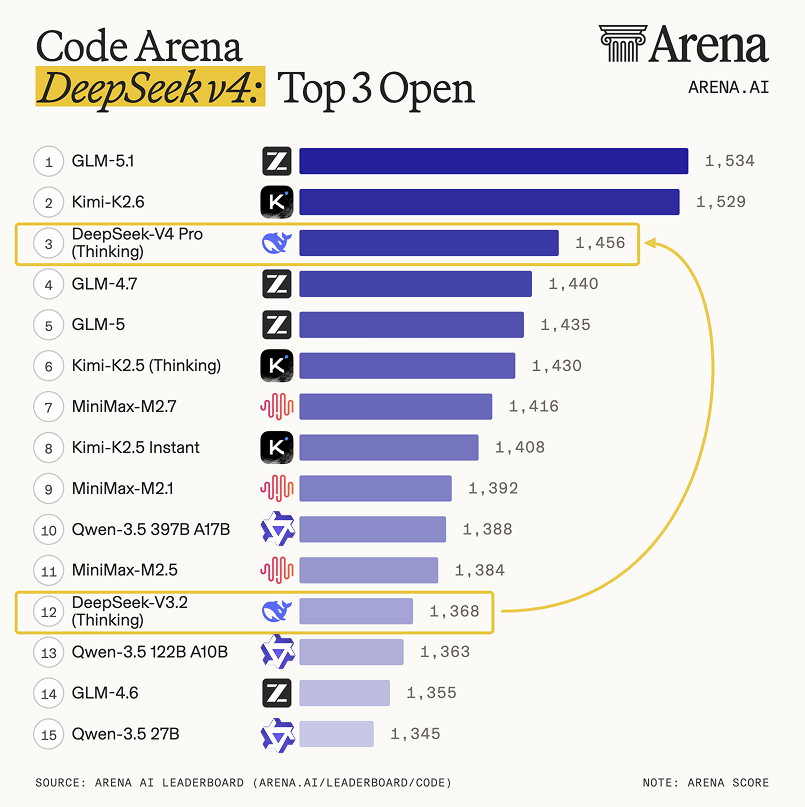
Exciting news - DeepSeek V4 Pro is in the Arena with 1.6T parameters (49B activated) alongside V4 Flash at 284B parameters (13B activated). Both support 1M token context. It’s a major leap over DeepSeek V3.2!
Code Arena:
- DeepSeek V4 Pro (thinking): #3 open model (#14 overall), on par with GPT-5.4-high and Gemini-3.1-Pro in agentic webdev tasks
Text Arena:
- DeepSeek V4 Pro (thinking): #2 open model (#14 overall), matching Kimi-2.6
- DeepSeek V4 Flash (thinking): #10 open model (#47 overall)
Competition at the top of the open model leaderboards keeps heating up. Huge congrats to @DeepSeek_AI on the strong comeback!
Exciting news - GPT-Image-2 by @OpenAI has claimed the #1 spot across all Image Arena leaderboards!
A clean sweep with a record-breaking +242 point lead in Text-to-Image - the largest gap we’ve seen to date.
- #1 Text-to-Image (1512), +242 over #2 (Nano-banana-2 with web-search aka gemini-3.1-flash-image)
- #1 Single-Image Edit (1513), +125 over #2 (Nano-banana-pro aka gemini-3-pro-image)
- #1 Multi-Image Edit (1464), +90 over #2 (Nano-banana-2)
No model has dominated Image Arena with margins this wide.
Huge congratulations to @OpenAI on this major breakthrough in image generation! More performance breakdowns by category in the thread below.
We’ve added Pareto frontier charts to the leaderboard.
Now available across:
Text, Vision, Search, Document, and Code Arena.
The Pareto frontier curve demonstrates which models are most efficient at their level of performance (by Arena score) vs. a blended price per 1M tokens (3:1 Ratio).
Text Models on the Pareto Frontier curve today:
- Claude Opus 4.6
- Gemini 3.1 Pro Preview
- Grok 4.20 Beta Reasoning
- Gemini 3 Flash
- Grok 4.1 Thinking
- DeepSeek v3.2 Exp Thinking
- Deepseek v3.2
- Mimo v2 Flash (non-thinking)
- Gemma-3-27b-it
- Gemma-3-12b-it
- GPT-OSS-20b
- Gemma 3n-e4b-it
Model count by Lab for Text Arena:
- 5 models @GoogleDeepMind
- 2 models from @xai
- 2 models from @deepseek_ai
- 1 @AnthropicAI
- 1 @Xiaomi
- 1 @OpenAI
Dig into the Pareto frontier for Document, Search, Video or Code Arena, by lab, or the expert categories most relevant to you.
Did you know? We’re funding independent research in AI evaluation and measurement—up to $50k per project.
The Q1 deadline to apply for Arena’s Academic Partnerships Program is March 31.
Today we’re launching the Video Edit Arena to evaluate the frontier capability of video models!
- #1 Grok-Imagine-Video, @xAI
- #2 Kling-o3-pro, @Kling_ai
- #3 Kling-o1-pro, @Kling_ai
- #4 Gen4-aleph, @Runwayml
The leaderboard is powered by thousands of real-world community votes. Click the Edit button in Video Arena to edit any video and compare top model outputs.
More models coming soon!
Today, we’re launching a dedicated Multi-File React leaderboard. When Code Arena first launched, we evaluated models on single-file HTML.
Then we raised the bar → multi-file React apps (routing, hooks, components, state management) and now have a leaderboard to match!
Single-file HTML tests instruction following.
Multi-file React tests more complex agentic capabilities:
• Cross-file coordination
• Component architecture
• Dependency management
• State management
• Build reliability
Now see how models stack up under both scenarios. Learn more in thread 🧵👇
⚡️Who powers the Arena leaderboard? You do.
But not all votes are Arena level research-grade quality.
Every score is built from real-world prompts and human input, continuously refreshed as the way we use AI evolves.
In this video, ML Scientist @cthorrez explains how votes are processed and validated into high-quality data trusted by leading AI labs. Dive into:
▪️ Filtering low-signal and bot-like activity
▪️ Our quality control and validation pipeline
▪️ Ensuring all votes are based on blind pairings
▪️ How diverse user prompts differ from static benchmarks
Arena scores reflect how models perform in the wild: across coding, creative work, expert tasks, and everyday use.
Watch the breakdown to see how your vote helps shape the frontier.
✨NEW: Arena Leaderboard UI Updates
Millions of votes power the leaderboard. Now you can filter for what matters to you.
A new side panel lets you filter and break down ranked results to find the best model for your task. Some highlights:
• Filter by category (e.g. Coding, Expert prompts)
• Open vs. Proprietary Models
• Rank labs by their top-performing models
…just to name a few. Check it out, and let us know what you think.
The new @xAI Grok-Imagine-Image model is a Pareto-optimal model in Image Arena:
The Pareto frontier tells us which model has the highest Arena score at each price point. @xAi’s latest models have improved the frontier, giving optimal performance in the mid-price tier. For a wide range of prices between 2c and 8c per image, @elonmusk’s @xAI has the leading model, delivering the maximum performance.
Top models on the Pareto frontier for Image Arena (Single Image Edit):
- @OpenAI: GPT-Image-1.5-high-fidelity
- @xAI: Grok Imagine Image Pro
- @xAI: Grok Imagine Image
- @bfl_ml: Flux 2 Klein 9B
- @bfl_ml: Flux-2-Dev
- @reve : V1.1 Fast
See thread for how the frontier changes for Text-to-Image 🧵
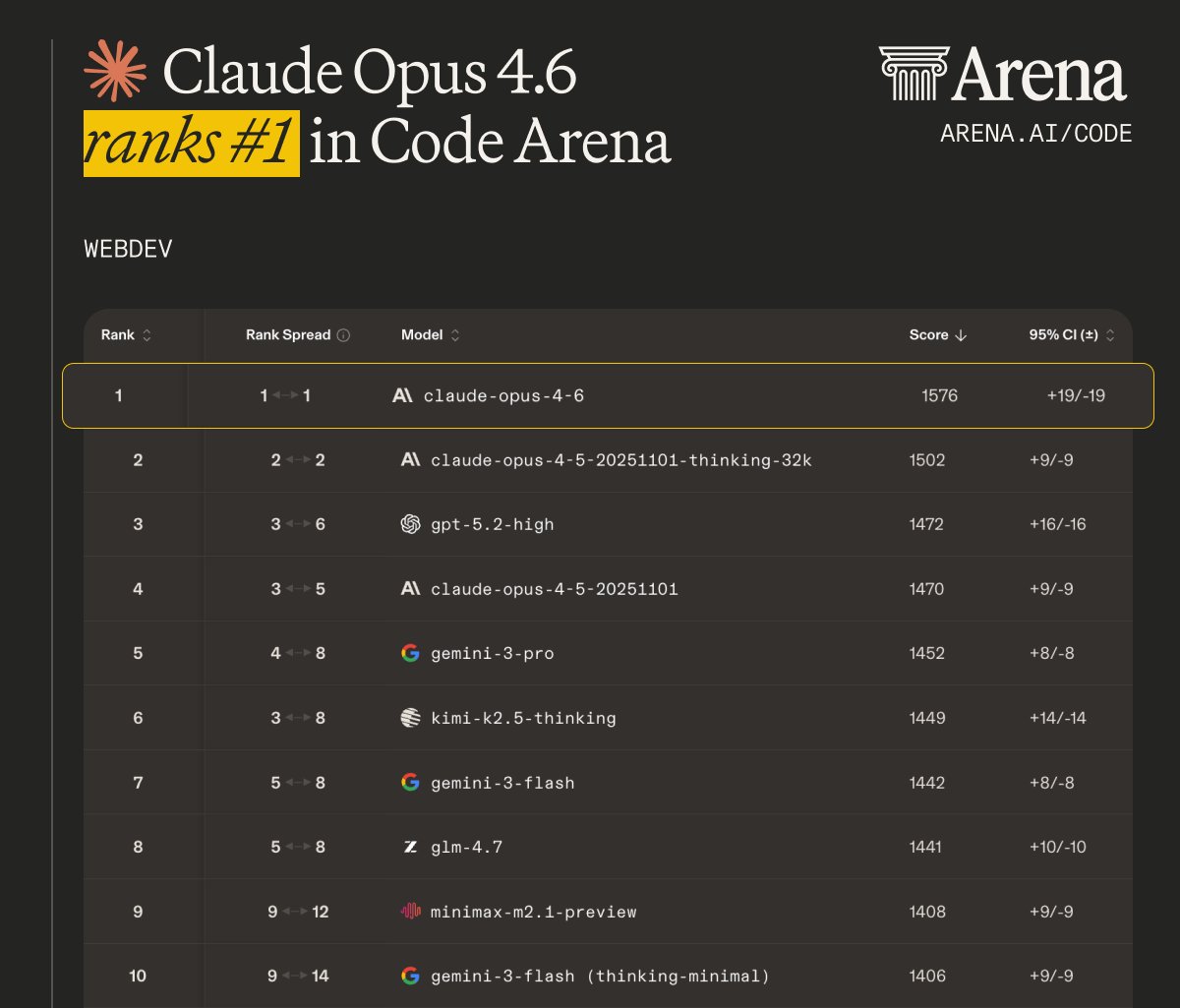
🚨BREAKING: Claude Opus 4.6 by @AnthropicAI is now #1 across Code, Text and Expert Arena!
Opus 4.6 shows significant gains across the board:
- #1 Code Arena: +106 score vs Opus 4.5
- #1 Text Arena: scoring 1496, +10 vs Gemini 3 Pro
- #1 Expert Arena: +~50 lead
Congrats to the @AnthropicAI team on the incredible milestone! The frontier just moved.
👋Say hello to Max!
Max is Arena’s intelligent router, powered by 5+ million real-world community votes.
Max routes each prompt to the most capable model with latency in mind. AI models excel at different things (code, math, speed, reasoning). Max orchestrates across model strengths to deliver reliable performance across real-world use cases.
Available today in Direct chat!
LMArena is now Arena.
A name that takes us back to our roots with a powerful mission: to measure and advance the frontier of AI for real-world use.
We have grown from a small PhD research project to a platform powered by a global community of millions. This rebrand has been shaped by the people who use it.
👇 Take a look inside the rebrand.
🚨BIG NEWS: 🎬 Video Arena is now live on the web!
Test out Veo 3.1, Sora 2, Seedance v1.5 Pro, Kling 2.6 Pro, Wan 2.5 & more.
What started last summer as a small Discord bot experiment has grown into a rigorous way to measure and understand how frontier video models perform with real-world use. Thank you to our wonderful community for all the feedback!
Today, we’re opening up access by making it available on the web.
🎥 Generate videos with 15 different frontier AI models and compare them head-to-head.
📊 Vote for the best output to power the leaderboards.
Who’s actually leading the AI race? It depends on which leaderboard you look at.
On Arena’s Text leaderboard (since May 2023):
🔹@OpenAI leads 74% of the time
🔹@GoogleDeepMind 21%
🔹@AnthropicAI 5%
But zoom into Expert prompts (~5% of the hardest real-world tasks) and the story flips. 👇
On Arena’s Expert Text leaderboard (since March 2024):
🔸@AnthropicAI leads 48% of the time
🔸@OpenAI 37%
🔸@GoogleDeepMind 12%
🔸@Deepseek_AI 4%
The takeaway: Different tasks. Different winners.