There is some really weird stuff going on with this staged shooting.
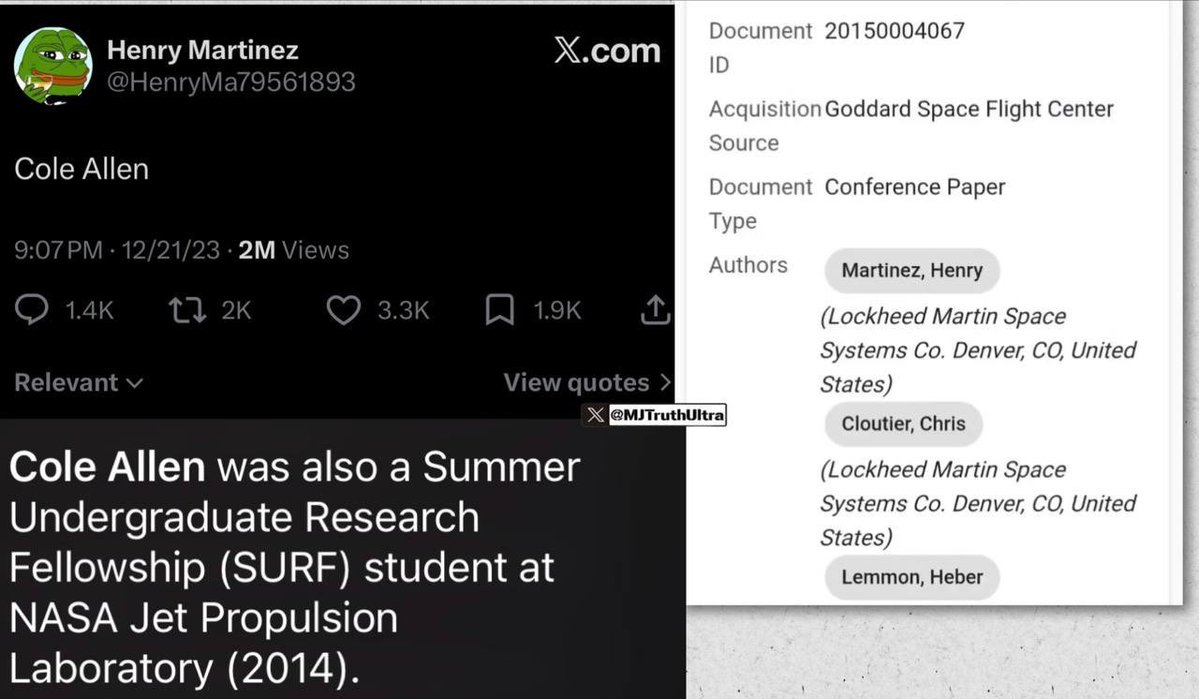
The shooter’s name is Cole Allen.
He uploaded a photo wearing an IDF t-shirt to instagram prior to the shooting and google searches for his name trended in Israel prior to the shooting.
Now it gets even weirder.
A man by the name of Henry Martinez made a single post on X in 2023 that read: “Cole Allen.”
And it looks like they knew each other as both Cole Allen and Henry Martinez interned at NASA’s Jet Propulsion Laboratory in 2014.
There is no logical way to explain how Henry Martinez would know all the way back in 2023 that Cole Allen would do this in 2026 unless Time Travel is real and this is Henry’s way of hinting to us that it is real.
You could argue the other way to explain it is this shooting was being planned all the way back in 2023 but that was before President Trump had won a 2nd term and as crazy as it sounds seems even more farfetched than Time Travel. 👀
🚨 STOP BURNING YOUR TOKENS!
If you use Claude Code, you are probably wasting 80% of your context window.
I found 10 ace tools that will completely rescue your API bill.
1. Caveman Claude
- Literally makes Claude talk like a caveman
- Slashes 75% of output tokens with zero loss in accuracy
Repo → https://t.co/eEvSOvHutG
2. RTK (Rust Token Killer)
- A blazing fast proxy that filters terminal output
- 60-90% reduction and completely dependency-free
Repo → https://t.co/lDfjbsbPD5
3. Code Review Graph
- Claude reads only what matters using a Tree-sitter graph
- An unbelievable 49x token reduction on huge monorepos
Repo → https://t.co/xGn6Pp88yX
4. Context Mode
- Sandboxes raw output into SQLite instead of your context
- A staggering 98% context reduction on logs & GitHub
Repo → https://t.co/Jut2bvBMUD
5. Claude Token Optimizer
- Brilliant setup prompts that optimize any project
- 90% token savings, taking docs from 11K to 1.3K
Repo → https://t.co/0uOFODbG7e
6. Token Optimizer
- Hunts down the invisible ghost tokens eating your context
- Fully restores and protects your context quality
Repo → https://t.co/LUOzjECXKm
7. Token Optimizer MCP
- Adds aggressive caching and compression to your MCP tools
- 95%+ token reduction through pure intelligence
Repo → https://t.co/b5Eqruo2PM
8. Claude Context
- Zilliz’s hybrid vector search MCP
- Makes your entire codebase the context for 40% less cost
Repo → https://t.co/hPG6pb0j3G
9. Claude Token Efficient
- Just drop one CLAUDE.md file into your repo
- Enforces strict terseness with zero code changes
Repo → https://t.co/fNrl6nwItF
10. Token Savior
- Navigates your code by symbols, not giant files
- 97% reduction on code navigation with persistent memory
Repo → https://t.co/lkILPhfwJh
----
[ The god-tier stack ]
Pick 2-3 based on what’s draining you:
> Massive repo? Code Review Graph + Token Savior
> Heavy terminal output? RTK
> MCP data dumps? Context Mode
> Need an instant fix? Caveman + Claude Token Efficient
Most devs are bleeding tokens.
Run `/context` in a fresh session and watch the savings roll in 👀
A regular American developer bought $1,400 worth and stacked seven Mac Minis on top of each other and connected them with metal cables.
Neighbors thought he was building a mining server. His wife thought he'd lost his mind. He just didn't want to pay $15,000 a month for a dev team.
On the screen - a diagram. Seven Mac Minis connected via Ethernet working as one machine. EXO framework distributes tasks between them automatically. 11.44 TFLOPS each. Together - more than most cloud servers that companies pay thousands for every month.
He paid $1,400 for the hardware once.
38 agents from GitHub, 156 skills. A system that learns from session to session and in two weeks writes code just like he does - but seven times faster because it runs on seven machines in parallel.
A task that took a junior dev 10-12 hours - the tower closes in 20 minutes.
One founder with this setup ships a product like a team of eight people.
For $20 a month instead of $120,000 a year.
This 7 Mac Mini setup helped him win the Anthropic hackathon and make $26,000 without a team.
Introducing Pods
Hyperspace Pods lets a small group of people - a family, a startup, a few friends, to pool their laptops and desktops into one AI cluster. Everyone installs the CLI, someone creates a pod, shares an invite link, and the machines form a mesh. Models like Qwen 3.5 32B or GLM-5 Turbo that need more memory than any single laptop has get automatically sharded across the group's devices - layers split proportionally, inference pipelined through the ring. From the outside it looks like one OpenAI-compatible API endpoint with a pk_* key that drops straight into your AI tools and products. No configuration beyond pasting the key and changing the base URL.
A team of five paying for cloud AI burns $500–2,000 a month on API calls. The same team's existing machines can serve Qwen 3.5 (competitive on SWE-bench) and GLM-5 Turbo (#1 on BrowseComp for tool-calling and web research) for free - the hardware is already on their desks. When a query genuinely needs a frontier model nobody has locally, the pod falls back to cloud at wholesale rates from a shared treasury. But for the daily work - code reviews, refactors, research, drafting - local models handle it and nobody gets billed. And when it is idle, you can rent out your pod on the compute marketplace, with fine-grained permissions for access management.
There's no central server involved in inference. Prompts go from your machine to your pod members' machines and back: all of this enabled by the fully peer-to-peer Hyperspace network. Pod state - who's a member, which API keys are valid, how much treasury is left - is replicated across members with consensus, so the whole thing works on a local network. Members behind home routers don't need port forwarding either. The practical setup for most pods is three models covering different jobs: Qwen 3.5 32B for code and reasoning, GLM-5 Turbo for browsing and research, Gemma 4 for fast lightweight tasks. All running on hardware you already own.
Pods ship today in Hyperspace v5.19. Model sharding, API keys, treasury, and Raft coordinator are all live.
What Makes This Different - No middleman. Your prompts travel from your IDE to your pod members' hardware and back. There is no server in between reading your data.
- No vendor lock-in. Pod membership, API keys, and treasury are replicated across your own machines using Raft consensus. If the internet goes down, your local network keeps working. There is no database in someone else's cloud that your pod depends on.
- Automatic sharding. You don't configure layer ranges or calculate VRAM budgets. Tell the pod which model you want. It figures out how to split it across whatever hardware is online.
- Real NAT traversal. Your friend behind a home router with a dynamic IP? Works. No VPN, no Tailscale, no port forwarding. The nodes handle it.
- Free when local. This is the part that matters most. Cloud AI bills scale with usage. Pod inference on local hardware scales with nothing. The marginal cost of your 10,000th prompt is the electricity your laptop was already using.
Coming soon:
- Pod federation: pods form alliances with other pods.
- Marketplace: pods with spare capacity can sell inference to other pods.
I was chatting with my buddy at Google, who's been a tech director there for about 20 years, about their AI adoption. Craziest convo I've had all year.
The TL;DR is that Google engineering appears to have the same AI adoption footprint as John Deere, the tractor company. Most of the industry has the same internal adoption curve: 20% agentic power users, 20% outright refusers, 60% still using Cursor or equivalent chat tool. It turns out Google has this curve too.
But why is Google so... average? How is it that a handful of companies are taking off like a spaceship, and the rest, including Google, are mired in inaction?
My buddy's observation was key here: There has been an industry-wide hiring freeze for 18+ months, during which time nobody has been moving jobs. So there are no clued-in people coming in from the outside to tell Google how far behind they are, how utterly mediocre they have become as an eng org.
He says the problem is that they can't use Claude Code because it's the enemy, and Gemini has never been good enough to capture people's workflows like Claude has, so basically agentic coding just never really took off inside Google. They're all just plodding along, completely oblivious to what's happening out there right now.
Not only is Google not able to do anything about it, they don't seem to be aware of the problem at all. I'm having major flashbacks to fifty years ago as a kid at the La Brea Tar Pits, asking, "why can't they just climb out?"
My Google friend and I had this conversation over a month ago. I didn't share it because I wanted to look around a bit, and see if it's really as bad as all that. I've been talking to people from dozens of companies since then. And yeah. It's as bad as all that.
Google is about average. Some companies at the bottom have near-zero AI adoption and can't even get budget for AI. They may have moats and high walls, but the horde is coming for them all the same.
And then there are a few companies I've met recently who are *amazingly* leaned in to AI adoption. One category-leader company just cancelled IntelliJ for a thousand engineers. That's an incredibly bold move, one of many they're making towards agentic adoption. In my opinion, that company is setting themselves up for a _huge_ W.
As for the rest, well, it's the Great Siloing. Everyone's flying blind. With nobody moving companies, no company knows where they stand on the AI adoption curve. Nobody knows how they're doing compared to everyone else.
Half of them just check a box: "We enabled {Copilot/Cursor} for everyone!" Cue smug celebrations. They think this is like getting SOC2 compliance, just a thing they turn on and now it's "solved." And they don't realize that they've done effectively nothing at all.
All because of a hiring freeze.
Judging by my tl there is a growing gap in understanding of AI capability.
The first issue I think is around recency and tier of use. I think a lot of people tried the free tier of ChatGPT somewhere last year and allowed it to inform their views on AI a little too much. This is a group of reactions laughing at various quirks of the models, hallucinations, etc. Yes I also saw the viral videos of OpenAI's Advanced Voice mode fumbling simple queries like "should I drive or walk to the carwash". The thing is that these free and old/deprecated models don't reflect the capability in the latest round of state of the art agentic models of this year, especially OpenAI Codex and Claude Code.
But that brings me to the second issue. Even if people paid $200/month to use the state of the art models, a lot of the capabilities are relatively "peaky" in highly technical areas. Typical queries around search, writing, advice, etc. are *not* the domain that has made the most noticeable and dramatic strides in capability. Partly, this is due to the technical details of reinforcement learning and its use of verifiable rewards. But partly, it's also because these use cases are not sufficiently prioritized by the companies in their hillclimbing because they don't lead to as much $$$ value. The goldmines are elsewhere, and the focus comes along.
So that brings me to the second group of people, who *both* 1) pay for and use the state of the art frontier agentic models (OpenAI Codex / Claude Code) and 2) do so professionally in technical domains like programming, math and research. This group of people is subject to the highest amount of "AI Psychosis" because the recent improvements in these domains as of this year have been nothing short of staggering. When you hand a computer terminal to one of these models, you can now watch them melt programming problems that you'd normally expect to take days/weeks of work. It's this second group of people that assigns a much greater gravity to the capabilities, their slope, and various cyber-related repercussions.
TLDR the people in these two groups are speaking past each other. It really is simultaneously the case that OpenAI's free and I think slightly orphaned (?) "Advanced Voice Mode" will fumble the dumbest questions in your Instagram's reels and *at the same time*, OpenAI's highest-tier and paid Codex model will go off for 1 hour to coherently restructure an entire code base, or find and exploit vulnerabilities in computer systems. This part really works and has made dramatic strides because 2 properties: 1) these domains offer explicit reward functions that are verifiable meaning they are easily amenable to reinforcement learning training (e.g. unit tests passed yes or no, in contrast to writing, which is much harder to explicitly judge), but also 2) they are a lot more valuable in b2b settings, meaning that the biggest fraction of the team is focused on improving them. So here we are.
WE ARE SO COOKED <SOMETHING> ANTHROPIC MYTHOS!
No, no “we” are not. The only think that is cooked is the old systems. And this has been going on for 30 years.
We are not cooked, we are the cooks.
Read how…
Farza raised $10M from a16z for buildspace. 125,000 builders went through it. Valued at $100M. He shut it down in August 2024 because he couldn't find a direction that felt worth pursuing.
18 months later he's back. Building an AI teacher.
The thing people are missing about Clicky is that Farza already ran the experiment on teaching at scale. Buildspace tried cohorts, peer learning, mentorship, structured curricula, IRL events in SF and Dubai. 30,000 people in a single accelerator season. And after all of that, the founder concluded: the format was broken.
The cursor is the tell. He didn't build another course platform. He didn't build another cohort. He built something that sits next to you while you work and answers when you're stuck.
That's a $100M education company's worth of learnings compressed into a design decision: teaching works when it's ambient, not scheduled. When it responds to your confusion in the moment instead of packaging information you might need later.
Every AI education startup right now is building the platform. Farza already built and killed the platform. He's building the presence.
I built this thing called Clicky.
It's an AI teacher that lives as a buddy next to your cursor.
It can see your screen, talk to you, and even point at stuff, kinda like having a real teacher next to you.
I've been using it the past few days to learn Davinci Resolve, 10/10.
A Chinese engineering student built a weather tracking station in his dorm. Three Mac Minis. Two monitors. Satellite maps on both screens. Labels on each box: UI/UX. DEV. ADMIN. Total cost under $2,000.
His roommate thought it was a climate research project. His professors thought it was a thesis prototype. He let everyone keep thinking that.
Then someone noticed what the station was actually connected to.
A wallet. Making $101K. Betting on the temperature.
ColdMath. $101,042 profit. 5,252 predictions. Joined November 2025. Bio: Edge Compounds.
→ https://t.co/T1z9GFWKVT
The station does one thing. Claude pulls live pilot weather data. Real sensors. Real readings. Updated every 1-3 hours from stations worldwide. Compares it to prediction market prices. When they don't match the DEV box flags it.
Mismatch found. He places the trade. Green result.
$25 on Tokyo hitting 16C on March 20. Payout: $12,452. $24 on Chicago reaching 54F on March 11. Payout: $12,398. $13 on Lucknow hitting 39C on March 7. Payout: $6,850.
Twenty five dollar bets returning twelve thousand. On the weather.
A friend who flies commercial told him pilots get atmospheric data hours before any public forecast. Temperature to a tenth of a degree. This data is free. Aviation safety requires it. Nobody outside of aviation even looks at it.
He looked. Pointed Claude at the feeds. Said: find me every city where the forecast doesn't match the price.
Claude found dozens. Every single day.
His roommate saw the station running one morning and finally asked what it actually does. The student showed him the balance. The roommate didn't say anything. Just asked for a second monitor.
34K people watching. $96K still loaded in active positions. Three Mac Minis. Two screens. One quiet kid who realized the most predictable thing on Earth is the thing everyone ignores.
The weather.
karpathy is showing one of the simplest AI architectures that actually works..
dump research into a folder, let the model organise it into a wiki, ask questions, then file the answers back in.
the real insight is the loop...every query makes the wiki better. it compounds.. now thats a second brain building itself.
i think this is so good for agents if applied right
instead of pulling from shared memory every session, they build a living knowledge base that stays.
your coordinator is not just coordinating tasks anymore.. it is maintaining institutional knowledge so every execution adds something back to the base.
the bigger implication is crazy tho.
agents that own their own knowledge layer do not need infinite context windows, they need good file organisation and the ability to read their own indexes.
way cheaper, way more scalable, and way more inspectable than stuffing everything into one giant prompt.
This is either brilliant or scary:
Anthropic accidentally leaked the TS source code of Claude Code (which is closed source). Repos sharing the source are taken down with DMCA.
BUT this repo rewrote the code using Python, and so it violates no copyright & cannot be taken down!
Ollama is now updated to run the fastest on Apple silicon, powered by MLX, Apple's machine learning framework.
This change unlocks much faster performance to accelerate demanding work on macOS:
- Personal assistants like OpenClaw
- Coding agents like Claude Code, OpenCode, or Codex
I think the consensus is that Qwen3.5 is a step change so atm I would recommend explore that, given that it covers a range of sizes suitable for all devices.
Note that the main issues that people currently unknowingly face with local models mostly revolve around the harness and some intricacies around model chat templates and prompt construction. Sometimes there are even pure inference bugs. From typing the task in the client to the actual result, there is a long chain of components that atm are not only fragile - are also developed by different parties. So it's difficult to consolidate the entire stack and you have to keep in mind that what you are currently observing is with very high probability still broken in some subtle way along that chain.
But things are improving on all levels and everything will become better across the board soon.
Best way to evaluate things IMO:
- Start with full quality models that you fit on your hardware
- Make sure you know what your harness actually does. F.ex. don't expect to hook Claude Code or Codex to some local model and the magic to happen. The developers of CC don't care (yet) if it is compatible with Qwen3.5. Best is to write your own harness so you know what happens every step of the way. Or use llama-server's webui (we now have MCP support out of the box)
- When things start to click, look for optimizations to make it faster. Here is where you can start quantizing for speed or looks for some advice in the community for optimal parameters
So I can just say that on the low-level inference side, we will ship the right solution for sure. We still need to make the user-facing stack work better with local models - I'm hoping this will happen, though I feel less capable to control that.
And to answer your question more straightforward, I've experimented with the following models and have found useful applications (mostly around chat, MCP and coding) with all of them:
- gpt-oss-120b
- Qwen3-Coder-30B
- GLM-4.7-Flash
- MiniMax-M2.5
- Qwen3.5-35B-A3B
With the exception of gpt-oss-120b and MiniMax-M2.5, I've used Q8_0 variants to keep most of the original quality.
Unfortunately, I am not familiar with tool calling benchmarks specifically, so I cannot recommend. From my PoV, as long as we make sure the fundamental inference computation is correct, tool calling efficiency will depend just on:
- Model intelligence (something we do not control)
- Chat template parsing (something we are still actively improving on our end in llama.cpp)
llama.cpp at 100k stars
now that 90% of the code worldwide is being written by AI agents, I predict that within 3-6 months, 90% of all AI agents will be running locally with llama.cpp 😄
Jokes aside, I am going to use this small milestone as an opportunity to reflect a bit on the project and the state of AI from the perspective of local applications. There is a lot to say and discuss and yet it feels less and less important to try to make a point. Opinions about viability of local LLMs are strongly polarized, details are overlooked, the scientific approach is lacking. Arguments are predominantly based on vibes and hype waves.
One thing is clear though - local LLMs are used more and more. I expect this trend to continue and likely 2026 will end up being one of the most important years for the local AI movement.
I admit that I didn't expect the agentic era to come so quickly to the local LLM space. One year ago, the available models were too computationally expensive for doing long-context tasks. There wasn't an obvious path towards meaningful agentic applications. The memory and compute requirements were huge. Last summer, with the release of gpt-oss, things started to change. It was the first time we saw a glimpse of tool calling that actually works well within the resource constraints of our daily devices. Later in the year, even better models were released and by now, useful local agentic workflows are a reality.
Comparing local vs hosted capabilities at a given moment of time is pointless. To try put things into perspective:
- We don't need frontier intelligence to automate searches and sending emails
- We don't need trillion parameter models to be able to summarize articles or technical documents
- We don't need massive GPU data centers to control our home appliances or turn the lights off in the garage
I believe that there is a certain level of intelligence we as humans can comprehend and meaningfully utilize to improve our working process. Beyond that level, access to more intelligence becomes unnecessary at best and counterproductive at worst. I also believe that that level of useful artificial intelligence is completely within reach locally and it has always been just a matter of implementing the right software stack to bring it to the end user.
With llama.cpp, I am confident that we continue to be on the right track of building that software stack!
The llama.cpp project is going stronger than ever. With more than 1500 contributors, the project keeps growing steadily.
From technical point of view, I think that llama.cpp + ggml is the only solution that actually makes sense. That is, the software stack must run efficiently on every possible device, hardware and operating system. The technology is too important to be vendor-locked. It has to be developed in the open, by the community, together with the independent hardware vendors. This is the only right way to build something that will truly make a difference in the long run.
I won't try to convince you about what is currently and will be possible with local AI. We will just continue to build as usual. I am confident that after the smoke clears and we look objectively at what we have built together, the benefits will be obvious to everyone.
Big shoutout to all llama.cpp maintainers. I feel extremely lucky to be able to work together with so many talented contributors. Every day I learn something new and I feel there is so much more cool stuff that we are going to build. Also, I am really thankful that the project continues to have reliable partners to support it!
Cheers!
🚨🇭🇺 EXCLUSIVE w/ PM VIKTOR ORBAN ON THE IRAN WAR
If there’s ever a person who can give us insight into Trump’s thinking, and what could and should happen next in Iran, it’s Prime Minister Orban
He’s Europe’s longest serving Prime Minister, gone through the wars in Iraq, Afghanistan, Libya, Syria and Ukraine, he’s a friend of Trump who also gave him advice before the war, and he’s one of EU’s most respected and powerful voices.
I sat down again with the PM to get his thoughts on the current war, NATO’s potential involvement, and whether Trump is prepared for a prolonged conflict.
He was brutally honest with me, explaining why he believes NATO should support Trump, and why the war should end soon before it becomes a crisis for Iran, the U.S., and the entire world
It’s a delicate line between a success and failure, and we are at that crossroads now
We also discuss the future of the EU in a world dominated by the U.S. and China, the impact of the Iran war on Ukraine/Russia, and the repercussions of a prolonged conflict on Europe and the world.
The decisions being made right now will shape the next decade.
This conversation with @PM_ViktorOrban explains why.
02:10 Destroying Iran’s capabilities could bring peace… or trigger a much bigger war.
03:40 In that region, going in is easy. Getting out is almost impossible.
05:10 You cannot control that region from the air. It doesn’t work.
07:20 My first question is never global. It’s always: what does this do to Hungary?
08:30 Migration from Iran could hit Europe fast… and countries won’t be able to handle it.
09:40 If oil prices rise again, Hungary will take a direct economic hit.
11:20 Europe made a huge mistake by mocking Trump… and destroyed its relationship with the U.S.
12:40 Sanctioning cheap Russian energy was politically crazy.
14:50 Sooner or later, Europe will have to go back to Russia for energy.
16:00 Europe is becoming irrelevant because it’s trying to act like an empire.
18:10 Europe misread the global shift and is now falling behind the U.S. and China.
20:30 The Western elite became tired, boring, and out of ideas.
22:40 If this war ends fast, it will look like a success. If not, it becomes a disaster.
25:00 Thinking anyone can beat China is a mistake. China is unbeatable.
26:20 There won’t be just one global power. There will be at least two controlling the world.
30:10 Europe lost its identity and now doesn’t know what it stands for.
32:20 Central Europe is mentally stronger and ready to rise.
36:10 Mixing civilizations is too risky. We won’t take that risk.
45:20 Russia will reach its war goals by any means. The question is how we respond.
























![DataChaz's tweet photo. 🚨 STOP BURNING YOUR TOKENS!
If you use Claude Code, you are probably wasting 80% of your context window.
I found 10 ace tools that will completely rescue your API bill.
1. Caveman Claude
- Literally makes Claude talk like a caveman
- Slashes 75% of output tokens with zero loss in accuracy
Repo → https://t.co/eEvSOvHutG
2. RTK (Rust Token Killer)
- A blazing fast proxy that filters terminal output
- 60-90% reduction and completely dependency-free
Repo → https://t.co/lDfjbsbPD5
3. Code Review Graph
- Claude reads only what matters using a Tree-sitter graph
- An unbelievable 49x token reduction on huge monorepos
Repo → https://t.co/xGn6Pp88yX
4. Context Mode
- Sandboxes raw output into SQLite instead of your context
- A staggering 98% context reduction on logs & GitHub
Repo → https://t.co/Jut2bvBMUD
5. Claude Token Optimizer
- Brilliant setup prompts that optimize any project
- 90% token savings, taking docs from 11K to 1.3K
Repo → https://t.co/0uOFODbG7e
6. Token Optimizer
- Hunts down the invisible ghost tokens eating your context
- Fully restores and protects your context quality
Repo → https://t.co/LUOzjECXKm
7. Token Optimizer MCP
- Adds aggressive caching and compression to your MCP tools
- 95%+ token reduction through pure intelligence
Repo → https://t.co/b5Eqruo2PM
8. Claude Context
- Zilliz’s hybrid vector search MCP
- Makes your entire codebase the context for 40% less cost
Repo → https://t.co/hPG6pb0j3G
9. Claude Token Efficient
- Just drop one CLAUDE.md file into your repo
- Enforces strict terseness with zero code changes
Repo → https://t.co/fNrl6nwItF
10. Token Savior
- Navigates your code by symbols, not giant files
- 97% reduction on code navigation with persistent memory
Repo → https://t.co/lkILPhfwJh
----
[ The god-tier stack ]
Pick 2-3 based on what’s draining you:
> Massive repo? Code Review Graph + Token Savior
> Heavy terminal output? RTK
> MCP data dumps? Context Mode
> Need an instant fix? Caveman + Claude Token Efficient
Most devs are bleeding tokens.
Run `/context` in a fresh session and watch the savings roll in 👀](https://pbs.twimg.com/media/HGQWA_7WIAAS7uW.jpg)


































