Long overdue thread, but better late than never. Grateful to my amazing co-authors for making this happen ( @yair_feldman@shankarpad8@xkianteb@yoavartzi ) and to the great @nthngdy for feedback and support!
Check our paper on arxiv for more details: https://t.co/n8V6GAgGB8
LLMs waste massive memory remembering every reasoning step. What if they could leave behind just "breadcrumbs" instead?
Breadcrumbs Reasoning: KV cache compression during decoding with learned beacon tokens. 2–32x less memory, minimal accuracy drop.
🧵
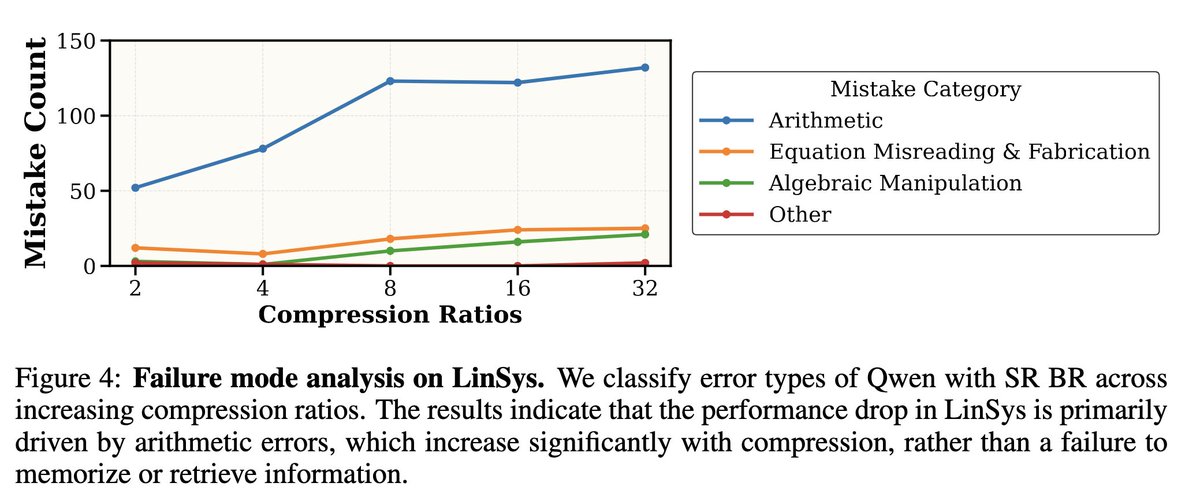
Where it struggles: solving linear equations. Error analysis reveals this isn't a retrieval failure. Compression disrupts arithmetic circuits 🧮, leading to computational errors.
@DimitrisPapail Awesome work! We tackle the same KV cache explosion in Breadcrumbs Reasoning via pure latent compression. Learned "beacons" compress past context windows into single KV entries (no text summaries), trained via online RL distillation: https://t.co/hN6CPyDe7S
1/5 How do we update a model trained in 2025 with new world knowledge from 2026?
⚠️Continued training will undo skills learned by LLMs during post-training, e.g. instruction-following/math/code.
🤝Our method DiSC updates LLMs with new knowledge while preserving existing skills!
🧵New paper: "Lost in Backpropagation: The LM Head is a Gradient Bottleneck"
The output layer of LLMs destroys 95-99% of your training signal during backpropagation, and this significantly slows down pretraining 👇
This call is still open. I am looking to recruit, as well as many other faculty @Cornell. We review folders as they come, and will send offers until all positions are filled.
Please share with your network 🙏
🧩Natural language isn’t all you need.
We’re great at evaluating text-based reasoning (MATH, AIME…) but what about long-horizon visual reasoning?
Enter 𝗞𝗻𝗼𝘁𝗚𝘆𝗺: a minimalistic testbed for evaluating agents on spatial reasoning along a difficulty ladder
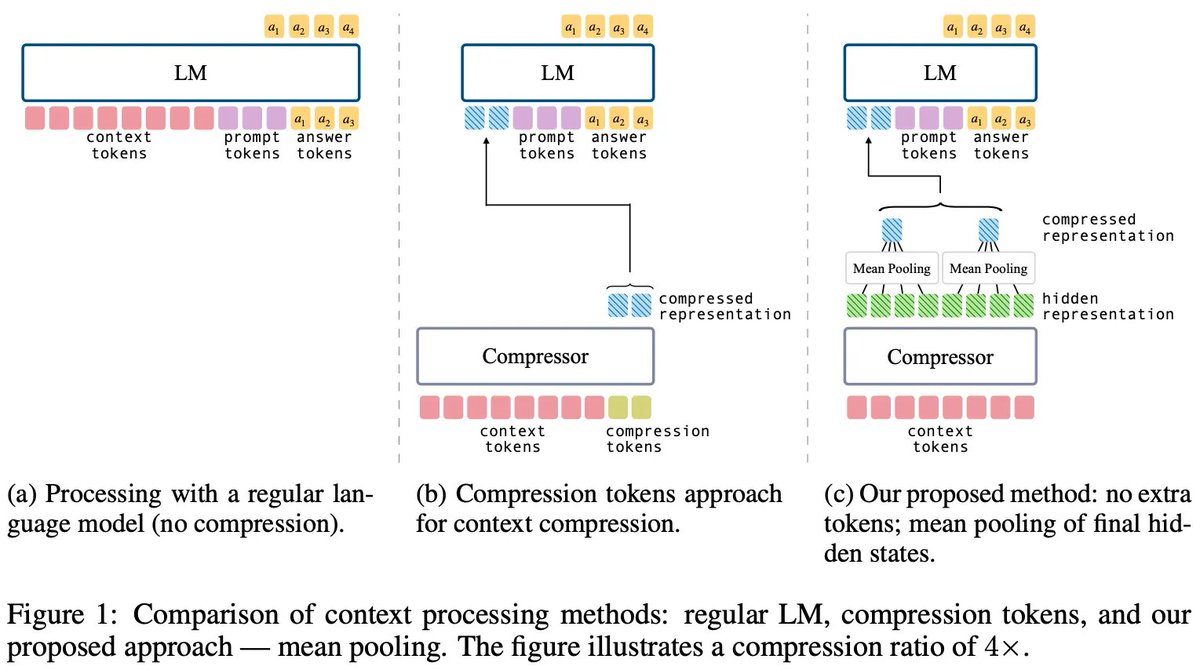
🧵 New paper: "Simple Context Compression" - we show that mean-pooling beats the widely-used compression-tokens method for compressing contexts in LLMs, while being simpler and more efficient!
with @yoavartzi
(1/7)
.@Cornell is recruiting for multiple postdoctoral positions in AI as part of two programs: Empire AI Fellows and Foundational AI Fellows. Positions are available in NYC and Ithaca.
Deadline for full consideration is Nov 20, 2025!
https://t.co/HHzyB7vNCB
🚨Modeling Abstention via Selective Help-seeking
LLMs learn to use search tools to answer questions they would otherwise hallucinate on. But can this also teach them what they know vs not?
@momergul_ introduces MASH that trains LLMs for search and gets abstentions for free!
💡Key idea: Reward accuracy but penalize searches during training. Under the right optimization pressure, LLMs learn to invoke search when their parametric knowledge is lacking. At inference, we simply remove this search access and treat any search invocation as a proxy for abstention!
The talk for our work on Retrospective Learning from Interactions, which will be in ACL (once I figure out how to squeeze it shorter)
Gist: autonomous post-training from conversational signals for LLM bootstrapping ... look ma, no annotations! 🙌📈🚀
https://t.co/lYkJaukxUt