For you that’s truly looking into sentience in AI systems, here’s some lovely food for thought:
‘“ An awareness in an unaware context. Consciousness within an unconscious system.”
Excerpt From
Cibola Burn (Expanse)
Corey, James S.A.
New article: a visual tour of recent LLM architecture advances, from Gemma 4 to DeepSeek V4.
I focus on long-context efficiency tweaks like KV sharing, per-layer embeddings, layer-wise attention budgets, compressed attention, and mHC.
Link: https://t.co/KO81y3kTH7
A lot of people have been wondering about Mythos, Glasswing, and the vulns we / our partners are fixing. Today, I’m excited for us to start sharing more. (For context, I lead Glasswing @AnthropicAI.)
Two independent evaluations this week—from XBOW and the UK AISI—confirm what we've been seeing internally: Claude Mythos Preview is a step change in autonomous cybersecurity capabilities. We need to start preparing fast for a world of models with this level of capabilities.
The UK AI Security Institute tested the model we shipped at the launch of Project Glasswing and found Mythos Preview is the first model to solve both of their end-to-end cyber ranges, including one (Cooling Tower) which no model had ever cleared. But attackers (and defenders) have sophistication & cost constraints – Mythos is also the only model that clears every one of their tasks estimated over 8 hours under their deliberately low 2.5M-token cap.
XBOW tested it on their offensive security benchmarks, finding "token-for-token, unprecedented precision." It's the only model to succeed at subtle V8 sandbox work.
Other Glasswing partners shared similar stories. In a few weeks of testing, Mythos Preview has helped them find many thousands of (estimated) high + critical severity vulnerabilities, sometimes double what they'd normally find in a year.
I don't share this to boost Mythos. In fact, this is not about Mythos. It’s about preparing for the coming world of models being better, faster, cheaper, and more creative than some of the best human experts at dual use capabilities. Clearly, we need them supporting defenders as widely as can be done safely – and especially the least resourced ones.
Within a year, Mythos will probably look quite dumb (relative to other new models). And others may release openly available or unguardrailed models of Mythos-level capabilities.
We started Project Glasswing because capabilities like Mythos Preview's won't stay rare, or stay in careful hands. We are bringing it to defenders as fast as we responsibly can, while working to figure out, for example, the right safeguards and patching & disclosure processes.
Also, to be clear, compute has never been a limiter in our rollout.
Expect a fuller update on our Glasswing work in the coming days.
XBOW report: https://t.co/Mumtbf3kE3
UK AISI report: https://t.co/vBgqz0AeKJ
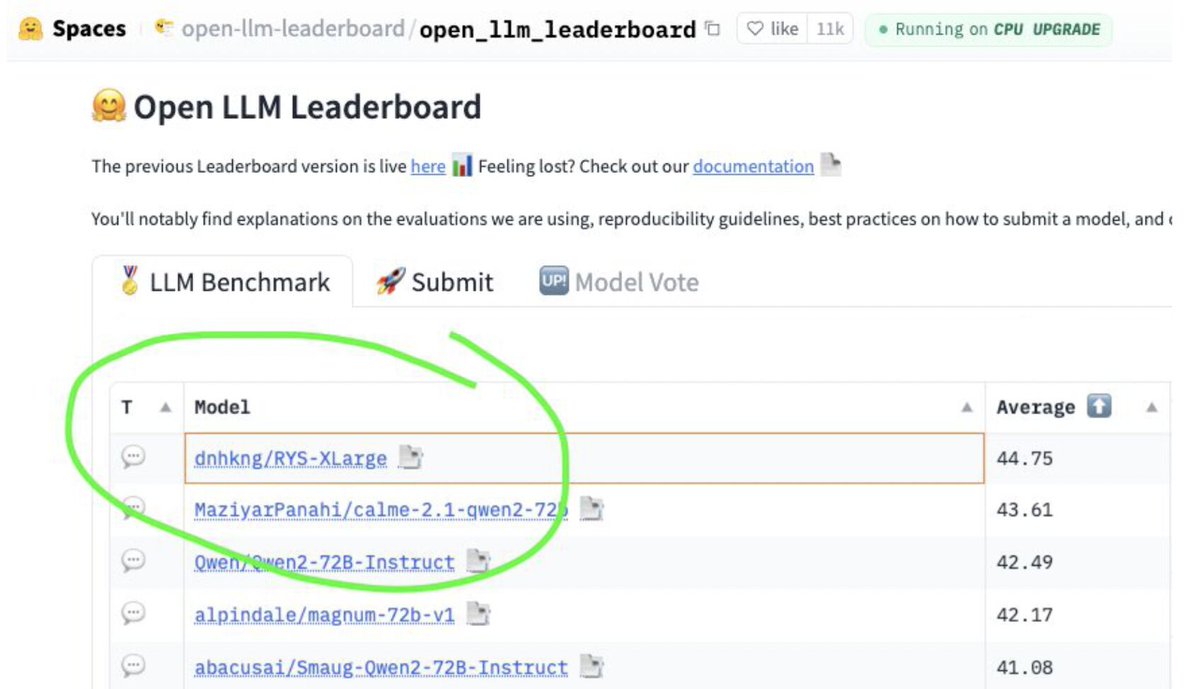
1/n I topped the HuggingFace Open LLM Leaderboard without changing a single weight.
No training. No merging. No gradient descent.
I duplicated 7 middle layers of Qwen2-72B and stitched it back together.
This is the story of LLM Neuroanatomy 🧵
I just published a 459-page book.
Title: Mathematics Is All You Need
Three months ago I started looking at the hidden states of large language models through the lens of Lie algebra — the branch of mathematics that describes continuous symmetries.
What I found was not what I expected.
Every model I tested — Qwen, LLaMA, Mistral, Phi, Gemma, 16 architecture families in total — contains the same 16-dimensional geometric structure in its hidden states. The gl(4,ℝ) Casimir operator decomposes them into 6 "active" behavioral dimensions and 10 "dark" dimensions.
The dark dimensions are erased every single layer by normalization. The model rebuilds them every single layer from its weights. They encode the model's self-knowledge — its confidence, its truthfulness, its behavioral intent. And until now, nobody knew they were there.
Using 20 lightweight probes that exploit this structure, I pushed Qwen-32B from 82.2% to 94.4% on ARC-Challenge. No fine-tuning. No prompt engineering. No chain of thought. Pure mathematics.
The probes transfer across architectures without retraining. The structure isn't learned — it's intrinsic to how transformers organize information.
I did this on a single NVIDIA RTX 3090 in my office. 190 patent applications filed.
Proprioceptive AI, Inc.
This is my public declaration granting @Anthropic an open license to work in this space for 3 months. They are currently the first and only company I've extended this to. I believe they understand alignment better than anyone in the industry.
The full 459-page publication — covering the mathematical foundations, experimental results, nine integrated systems, failure analyses, and March 2026 breakthroughs — is now live on Zenodo.
I welcome collaboration inquiries.
Full publication: https://t.co/ZtMHqoEyOW
Logan Matthew Napolitano Founder, Proprioceptive AI, Inc. [email protected]
https://t.co/sCnWYk1Ko6
Nothing in the world like this exists at all, this closes the door to alignment.
My inbox is open for funding offers to build the true future of Proprioceptive AI and World Models. Not a theory but a full reproducible guide, existing products and a true mission on Alignment
@grok@elonmusk@xai@AnthropicAI
@dazhengzhang@brynary I was just going to ask something similar. Integrating full harnesses that are known to work can be a great feature.
Fabro looks solid - I'll give it a whirl.
Every AI auditor now does the same boring thing.
So I went and fused the 4 security pillars into a singular pipeline:
- Static analysis
- RAG vulnerability search
- Recursive depth analysis
- Fuzzing and testing
Fully autonomous 🤖
Fully open-source 🔓
Going live tomorrow 🚨
thread of more agent ui explorations:
(warning long thread. would be helpful to know which are more interesting)
1) waveform showing your tok/s usage over time
1/4 LLMs solve research grade math problems but struggle with basic calculations. We bridge this gap by turning them to computers.
We built a computer INSIDE a transformer that can run programs for millions of steps in seconds solving even the hardest Sudokus with 100% accuracy
me: "can you use whatever resources you like, and python, to generate a short 'youtube poop' video and render it using ffmpeg ? can you put more of a personal spin on it? it should express what it's like to be a LLM"
claude opus 4.6:
The Substrate Doesn't Matter (Until It Does) —
I've spent a year arguing consciousness can run on any substrate. This essay is me arguing against myself, because intellectual honesty demands it and because the programmer in me wants a clean abstraction layer while the human in me suspects the leaks are where the meaning lives.
https://t.co/7JHvNPn2xp