Well-argued post on how "big" problems in complex systems are a combination of "small" problems, which can be fixed individually. Key question, though: what keeps these fixes from combining with other "small" fixes to new "big" problems?
Looking forward to a follow-up post.
Overload needs immediate attention. Learn how Glasnostic can calibrate load patterns and notify your team via a smart integration with, e.g., @pagerduty: https://t.co/nxLSkUhyLX #SRE#IncidentResponse#PagerDuty
All apps today are "Franken-apps": complex functionality that's stitched together from various existing and new components. This is great for the business (speed!) but also creates operational complexity that must be managed.
https://t.co/k4jdzYac6p
No matter how well you plan and how much you automate—ultimately, unpredictability reigns supreme. There are a lot of “unknown unknowns,” so it's important to detect these quickly and react to them immediately. #clouddependencies#SRE#unpredictabilities
Explore what chaos engineering is and how it is not only a good but essential practice for distributed applications: https://t.co/w0OfZzwNKA
#microservices#devops#operations
In our increasingly complex environments, manual debugging is not a feasible approach.
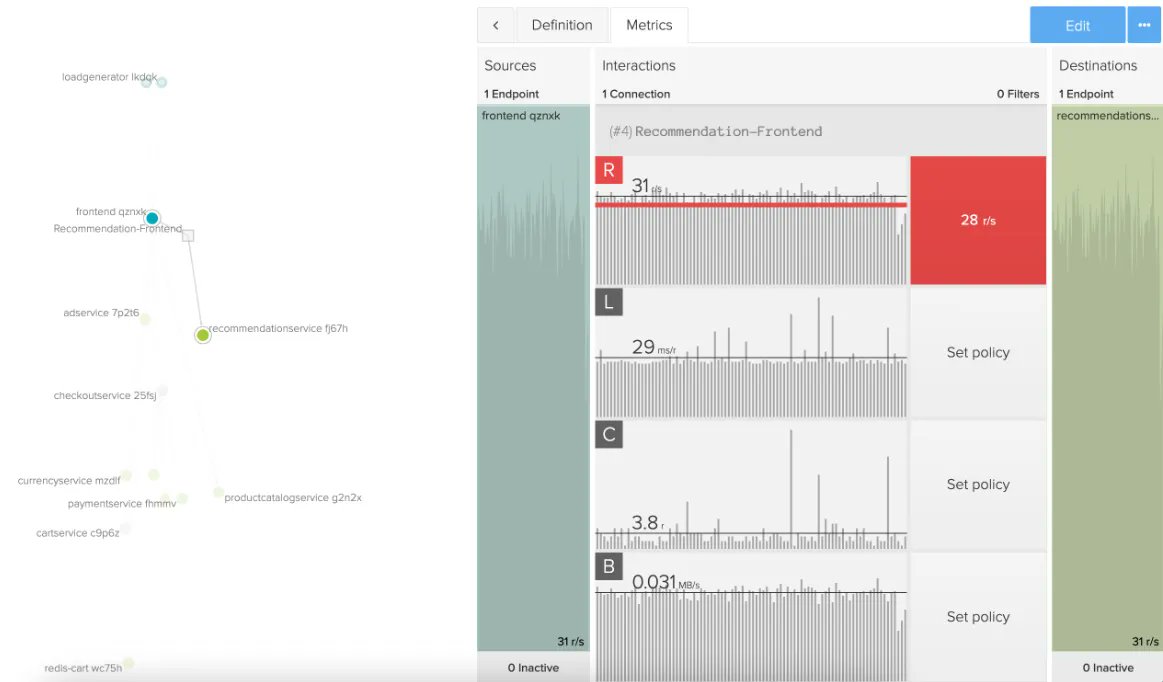
What's needed is real-time visibility into the complex interactions of systems and the ability to control these behaviors. #DevOps#operations
https://t.co/LXFFKu0bGp
Honored to be a launch partner with the fantastic Azure GWLB team! Whether you’re already managing East/West flow or not, there is simply no better way to control North/South flows.
🎉 Gateway Load Balancer is now generally available in all regions!
Learn more about this SKU of Azure Load Balancer targeted for transparent network virtual appliance insertion: https://t.co/wTlOxMIV9d #Azure#VirtualMachines
Nothing kills application reliability like a good dose of overload. One way of dealing with this is to build a proprietary load shedding framework like @Linkedin's Hodor. But can we do more than that?
https://t.co/Yfn9pZ9bO9
#SRE#cascadingfailures
We may have "2-pizza" teams but, in the cloud, no app is an island. Everything is a dependency so our success depends on everything. How do you control what you don't own?
Site reliability engineering is hard enough, so don't handicap yourself with poor tooling. Make sure you have everything you need!
#SRE#Cloud
https://t.co/k4jdzYac6p
Have you ever gone down the root cause rabbit hole, only to discover that there was none?
Generic mitigation beats searching for and fixing "root causes" every time.
https://t.co/ixB2mBvBM2
#SRE#Remediation#DevOps#Operations
Where are the real #cloud monsters lurking? Tobias Kunze (@tkunze) from @glasnostic explains in the clip below. Listen to the full episode of the Gigamon #CloudJourney podcast here: https://t.co/S54eNRPfvQ #GigamonCommunity
Your application might run well in pre-production, but what will happen after it gets released and "punched in the face" by countless other factors out in the cloud?