🚨New Preprint! Wondered how grid cells form multiple discrete modules? Interested in continuous attractors and modularity? With @FieteGroup, we discover + generalize a physical mechanism for forming modules from smoothly varying parameters in a dynamical system!👇(1/15)
couldn’t agree more
my bias since day one: deep learning is absurdly flexible to succeed, if math/physics don’t forbid it, and we get *opt & data* right.
it just works
Parallax/Muon is one example; models with dynamics such as feedback loops yet another happening rn
the broader implication is that there's abandoned architecture research from before Muon that failed because the empirical optimizers that worked in practice were, both literally and conceptually, stuck in element-wise local minima
For me, the coolest finding is that Muon optimizer is crucial for Parallax to move beyond Softmax Attention.
Lesson — don't evaluate new architectures solely under AdamW, you'll miss the good ones.
paper: https://t.co/yAqClXrJUz
code: https://t.co/D4pgIr1wM7
For the origin of Parallax, check out the LLA paper at ICLR 2026:
paper: https://t.co/85OzoOQlnF
code: https://t.co/eqMYZ0U6qO
@_arohan_@torchcompiled True (but figure 1 shows AdamW can’t be saved by good signal prop init)
Pieces of the puzzle have been there before for sure — https://t.co/YOu6CBTe6M
No Neocloud ever imagined they’d be renting out H100s today at higher prices than 3 years ago.
Even if you have money, frontier labs and Neolabs have already locked up most of the 2026 GPU supply.
There is basically infinite demand for artificial intelligence.
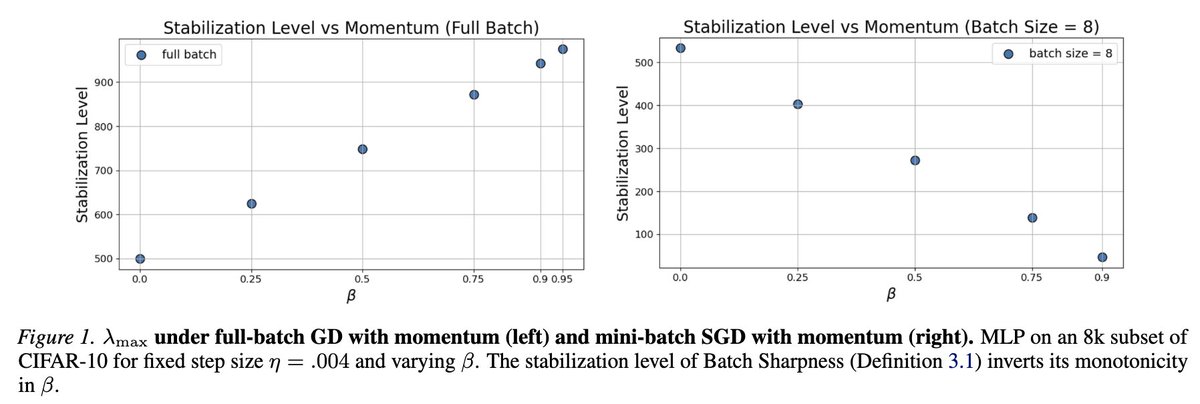
Our new paper was accepted at ICML!
1) Momentum isn’t just “SGD but faster”.
It affects sharpness (of orders of magnitude!)
2) The usual story says momentum lets you train in sharper regions.
That’s true for large batches only! The opposite is true for minibatches!