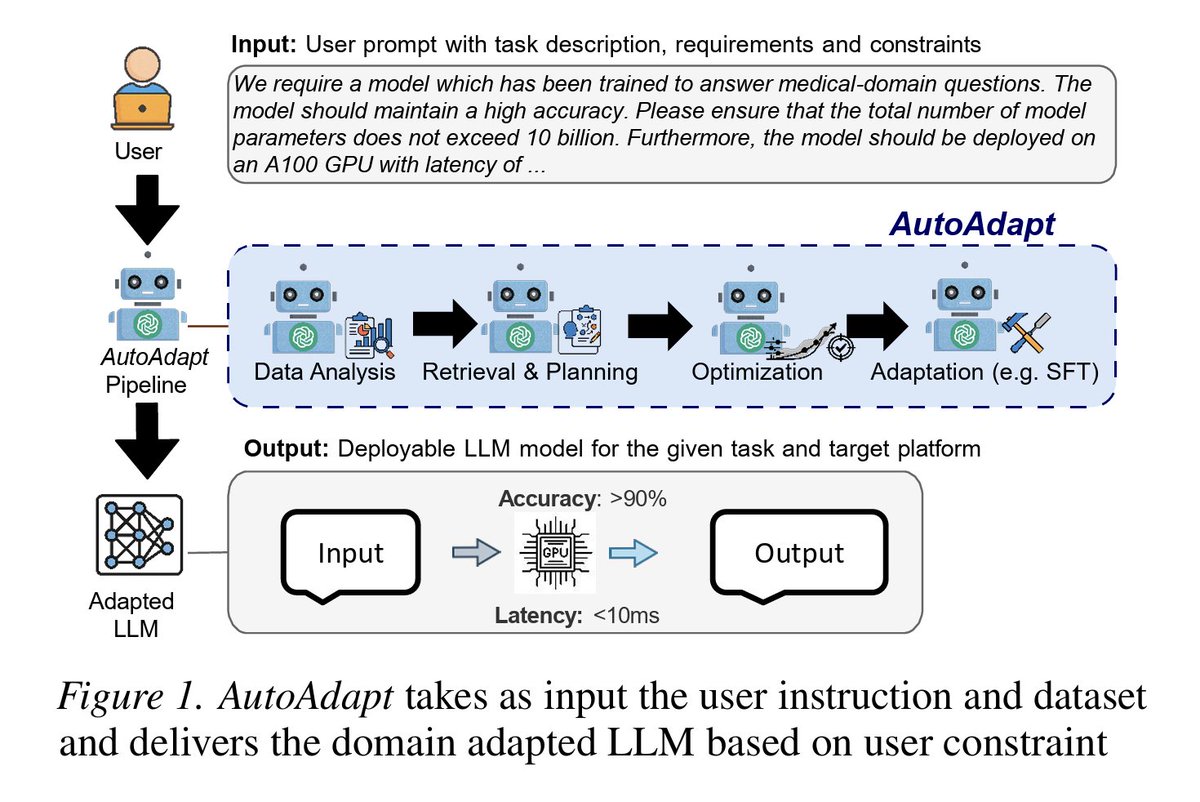
専門領域にLLMを適用する際に、RAG or SFT、LoRAを使うか、学習率やバッチサイズはどうするか、環境制約(GPU、レイテンシ、モデルサイズ上限など)を満たす構成をどうするかなどの決定を自動化するAutoAdapt提案
LLM特化でのドメインへの技術適用を自動化するイメージっぽい
https://t.co/wTXaVcFYFX
We're delighted to announce that MiniMax M2.7 is now officially open source.
With SOTA performance in SWE-Pro (56.22%) and Terminal Bench 2 (57.0%).
You can find it on Hugging Face now. Enjoy!🤗
huggingface:https://t.co/ApWrahIl3o
Blog: https://t.co/gAxeFsNdW4
MiniMax API: https://t.co/1dgbMx0Q7K
Pretrained ViTs like DINOv2 or CLIP are great, but they produce fixed, generic representations that encode the most salient visual concepts (e.g., "cat").
In human vision, prior priming with language changes how people parse an image. We believe visual encoders should do the same
🚨 Introducing Steerable Visual Representations, a new family of visual features you can steer with text towards specific visual concepts.