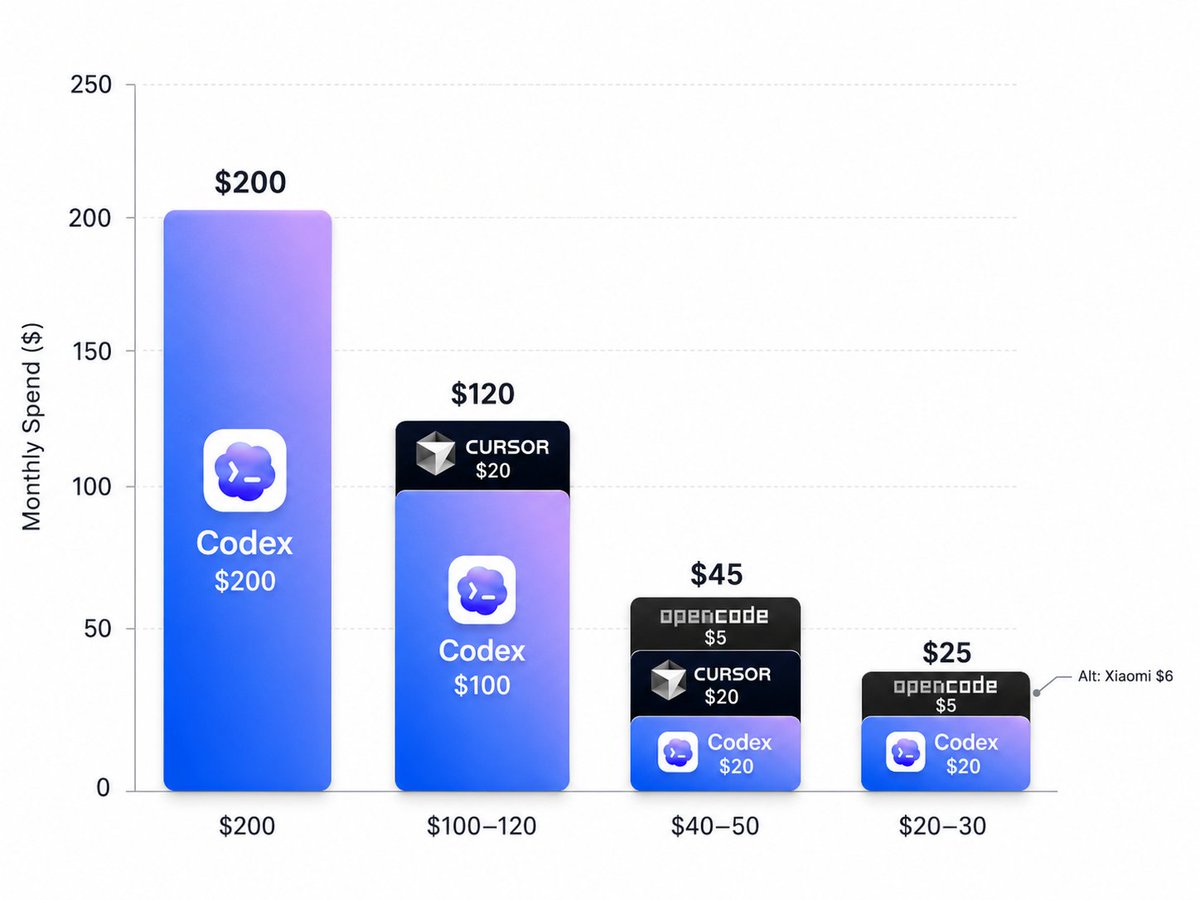
Here's the best coding plan for your specific budget
200$
Codex 200$
100-120$
Codex 100$ + Cursor 20$
40-50$
Codex 20$ + Cursor 20$ + Opencode 5$
20-30$
Codex 20$ + Opencode 5$ /Xiaomi 6$
Codex is a must've for any serious coding
while all other are swappable and cursor has become very valuable recently due to composer 2.5
Graph queries in Postgres 19 are the start of a journey, not a destination.
Postgres takes a pragmatic, incremental approach to adding functionality. For instance, way back in 2012, Postgres added its first JSON support. @craigkerstiens declared "we cheated" because it was just a text field with JSON validation layered on top of it. Two years later, JSONB was launched. New releases continue to add additional indexing capabilities and operators. Now, both JSON and JSONB have their place.
We expect Postgres 19's SQL/PGQ implementation to be similar. The initial release probably won't replace much workflow. It is limited to fixed-depth queries, which is already quite easy with current SQL implementations.
But, you have to start somewhere!
What is implemented?
DDL definition: a graph is declared and named. `CREATE PROPERTY GRAPH org_graph` declares which tables are vertices and edges, once. Queries can reference the graph by name. Schema changes propagate automatically, clear errors if a query references a vertex/edge that no longer exists, and no dropping tables with associated graphs.
Ever written a large CTE query that no fails due to a schema change? Yeah, me, either.
Query syntax: query syntax that follows SQL:2023 standards. For instance, `(a)<-[IS reports_to]-(b)` means b reports to a.
You get the standard composability of SQL because GRAPH_TABLE behaves as a table. So, join it, filter it, aggregate it, put it in a CTE, and think of GRAPH_TABLE as a new FROM clause source.
The question answered with this implementation is: "What is the least we can build that gets us started?" The answer appears to be DDL support and supported query syntax.
What SQL/PGQ can't do yet that recursive CTEs still do better:
Variable depth: if you need all descendants at any depth, SQL/PGQ in Postgres 19 is fixed-depth only. You must spell out each hop explicitly, which means you need to know the max depth at the time you write the query, which means the query can get lengthy.
Aggregation along the path: CTEs can build up arrays, concatenate paths, compute running totals as they recurse.
The future:
As with JSON support, just wait, and you'll look up after a few releases and say "oh, now it can do that too."
@sseraphini There’s a multi-model database that could genuinely be the future, but it still needs to mature, improve its OLAP capabilities, and rethink its licensing model: @SurrealDB
@sseraphini Column: cassandra
Column OLAP: clickhouse
Vector: turbopuffer, pinecone, pg_vector
Timeseries: clickhouse, timescale
Event: kafka, redis
But in 99% of cases, pg and redis is all you need, at most ETL to clickhouse









![crunchydata's tweet photo. Graph queries in Postgres 19 are the start of a journey, not a destination.
Postgres takes a pragmatic, incremental approach to adding functionality. For instance, way back in 2012, Postgres added its first JSON support. @craigkerstiens declared "we cheated" because it was just a text field with JSON validation layered on top of it. Two years later, JSONB was launched. New releases continue to add additional indexing capabilities and operators. Now, both JSON and JSONB have their place.
We expect Postgres 19's SQL/PGQ implementation to be similar. The initial release probably won't replace much workflow. It is limited to fixed-depth queries, which is already quite easy with current SQL implementations.
But, you have to start somewhere!
What is implemented?
DDL definition: a graph is declared and named. `CREATE PROPERTY GRAPH org_graph` declares which tables are vertices and edges, once. Queries can reference the graph by name. Schema changes propagate automatically, clear errors if a query references a vertex/edge that no longer exists, and no dropping tables with associated graphs.
Ever written a large CTE query that no fails due to a schema change? Yeah, me, either.
Query syntax: query syntax that follows SQL:2023 standards. For instance, `(a)<-[IS reports_to]-(b)` means b reports to a.
You get the standard composability of SQL because GRAPH_TABLE behaves as a table. So, join it, filter it, aggregate it, put it in a CTE, and think of GRAPH_TABLE as a new FROM clause source.
The question answered with this implementation is: "What is the least we can build that gets us started?" The answer appears to be DDL support and supported query syntax.
What SQL/PGQ can't do yet that recursive CTEs still do better:
Variable depth: if you need all descendants at any depth, SQL/PGQ in Postgres 19 is fixed-depth only. You must spell out each hop explicitly, which means you need to know the max depth at the time you write the query, which means the query can get lengthy.
Aggregation along the path: CTEs can build up arrays, concatenate paths, compute running totals as they recurse.
The future:
As with JSON support, just wait, and you'll look up after a few releases and say "oh, now it can do that too."](https://pbs.twimg.com/media/HImu_eSXgAE-Lvo.jpg)
![crunchydata's tweet photo. Graph queries in Postgres 19 are the start of a journey, not a destination.
Postgres takes a pragmatic, incremental approach to adding functionality. For instance, way back in 2012, Postgres added its first JSON support. @craigkerstiens declared "we cheated" because it was just a text field with JSON validation layered on top of it. Two years later, JSONB was launched. New releases continue to add additional indexing capabilities and operators. Now, both JSON and JSONB have their place.
We expect Postgres 19's SQL/PGQ implementation to be similar. The initial release probably won't replace much workflow. It is limited to fixed-depth queries, which is already quite easy with current SQL implementations.
But, you have to start somewhere!
What is implemented?
DDL definition: a graph is declared and named. `CREATE PROPERTY GRAPH org_graph` declares which tables are vertices and edges, once. Queries can reference the graph by name. Schema changes propagate automatically, clear errors if a query references a vertex/edge that no longer exists, and no dropping tables with associated graphs.
Ever written a large CTE query that no fails due to a schema change? Yeah, me, either.
Query syntax: query syntax that follows SQL:2023 standards. For instance, `(a)<-[IS reports_to]-(b)` means b reports to a.
You get the standard composability of SQL because GRAPH_TABLE behaves as a table. So, join it, filter it, aggregate it, put it in a CTE, and think of GRAPH_TABLE as a new FROM clause source.
The question answered with this implementation is: "What is the least we can build that gets us started?" The answer appears to be DDL support and supported query syntax.
What SQL/PGQ can't do yet that recursive CTEs still do better:
Variable depth: if you need all descendants at any depth, SQL/PGQ in Postgres 19 is fixed-depth only. You must spell out each hop explicitly, which means you need to know the max depth at the time you write the query, which means the query can get lengthy.
Aggregation along the path: CTEs can build up arrays, concatenate paths, compute running totals as they recurse.
The future:
As with JSON support, just wait, and you'll look up after a few releases and say "oh, now it can do that too."](https://pbs.twimg.com/media/HImu8aFW8AA8Bga.jpg)















![crunchydata's tweet photo. Graph queries in Postgres 19 are the start of a journey, not a destination.
Postgres takes a pragmatic, incremental approach to adding functionality. For instance, way back in 2012, Postgres added its first JSON support. @craigkerstiens declared "we cheated" because it was just a text field with JSON validation layered on top of it. Two years later, JSONB was launched. New releases continue to add additional indexing capabilities and operators. Now, both JSON and JSONB have their place.
We expect Postgres 19's SQL/PGQ implementation to be similar. The initial release probably won't replace much workflow. It is limited to fixed-depth queries, which is already quite easy with current SQL implementations.
But, you have to start somewhere!
What is implemented?
DDL definition: a graph is declared and named. `CREATE PROPERTY GRAPH org_graph` declares which tables are vertices and edges, once. Queries can reference the graph by name. Schema changes propagate automatically, clear errors if a query references a vertex/edge that no longer exists, and no dropping tables with associated graphs.
Ever written a large CTE query that no fails due to a schema change? Yeah, me, either.
Query syntax: query syntax that follows SQL:2023 standards. For instance, `(a)<-[IS reports_to]-(b)` means b reports to a.
You get the standard composability of SQL because GRAPH_TABLE behaves as a table. So, join it, filter it, aggregate it, put it in a CTE, and think of GRAPH_TABLE as a new FROM clause source.
The question answered with this implementation is: "What is the least we can build that gets us started?" The answer appears to be DDL support and supported query syntax.
What SQL/PGQ can't do yet that recursive CTEs still do better:
Variable depth: if you need all descendants at any depth, SQL/PGQ in Postgres 19 is fixed-depth only. You must spell out each hop explicitly, which means you need to know the max depth at the time you write the query, which means the query can get lengthy.
Aggregation along the path: CTEs can build up arrays, concatenate paths, compute running totals as they recurse.
The future:
As with JSON support, just wait, and you'll look up after a few releases and say "oh, now it can do that too."](https://pbs.twimg.com/media/HImvB72XIAEs2l2.jpg)




















