Come talk to us about pretraining data curation at #NAACL2024 at 2pm at poster session 2! We're presenting A Pretrainer's Guide to Training Data
Paper: https://t.co/YyMpMXuLIm
Come talk to us about pretraining data curation at #NAACL2024 at 2pm at poster session 2! We're presenting A Pretrainer's Guide to Training Data
Paper: https://t.co/YyMpMXuLIm
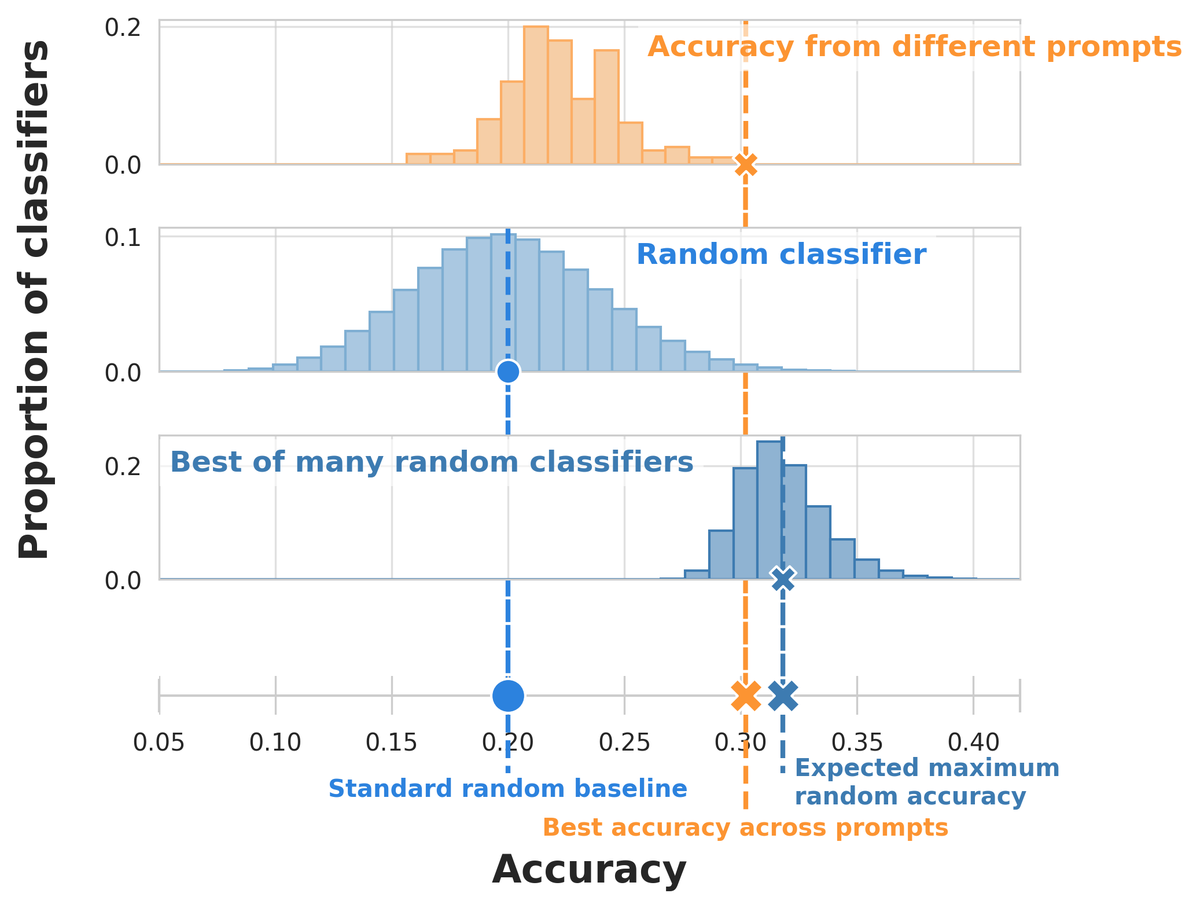
In the paper, we show that this max random baseline can be a better predictor of whether the best prompt will outperform random guessing on an unseen set. You can use this baseline right away on your own classification tasks! Code: https://t.co/WNLZhTkNA7
Evaluating many prompts on small few-shot datasets can make you think you’ve beaten random guessing when you haven’t! @dmimno and I study a simple drop-in replacement random baseline that protects against validation set reuse and small datasets: https://t.co/yHYYwWtOaJ
This problem goes away if you have a large validation set, but for the kind of fast-moving settings where in-context learning shines, that’s not always feasible. And there’s nothing wrong with trying lots of prompts! You just have to make sure you factor that into your baseline.
I'm postering this afternoon at #EMNLP2023! Stop by if you want to talk about how Data Similarity is Not Enough to Explain Language Model Performance: https://t.co/RIQnDRwCwM. Joint work with wonderful collaborators @emilyrreif and @dmimno
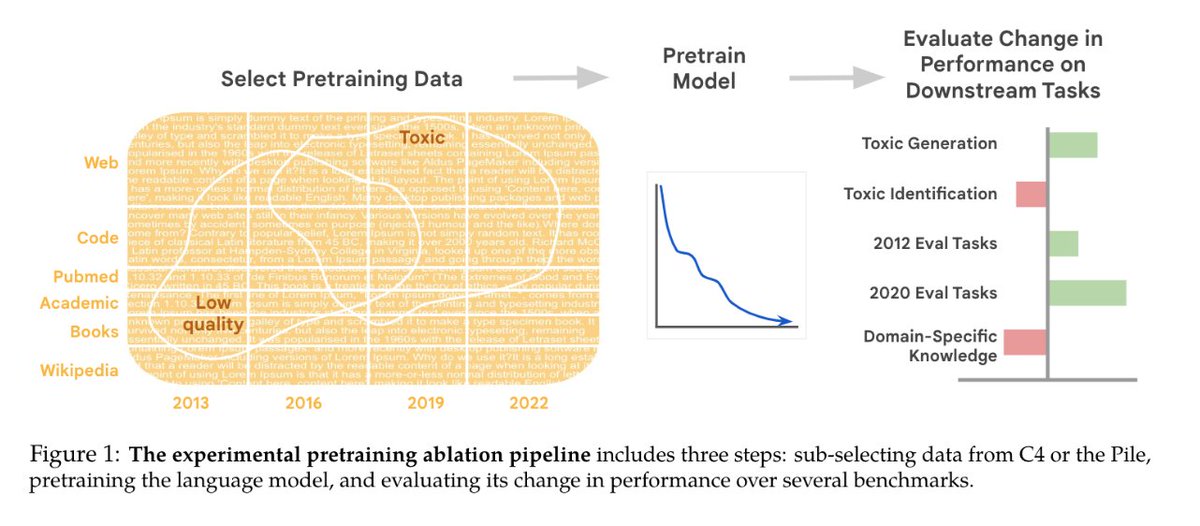
#NewPaperAlert When and where does pretraining (PT) data matter?
We conduct the largest published PT data study, varying:
1⃣ Corpus age
2⃣ Quality/toxicity filters
3⃣ Domain composition
We have several recs for model creators…
📜: https://t.co/SH50o0ktHO
1/ 🧵
When and where does pretraining data matter? New paper on how varying the pretraining data of LLMs affects downstream performance: https://t.co/MQc0fuHEws
But first, what do we know about the data itself?
1/ 🧵