First large-scale study of AI agents actually running in production.
The hype says agents are transforming everything. The data tells a different story.
Researchers surveyed 306 practitioners and conducted 20 in-depth case studies across 26 domains. What they found challenges common assumptions about how production agents are built.
The reality: production agents are deliberately simple and tightly constrained.
1) Patterns & Reliability
- 68% execute at most 10 steps before requiring human intervention.
- 47% complete fewer than 5 steps.
- 70% rely on prompting off-the-shelf models without any fine-tuning.
- 74% depend primarily on human evaluation.
Teams intentionally trade autonomy for reliability.
Why the constraints? Reliability remains the top unsolved challenge. Practitioners can't verify agent correctness at scale. Public benchmarks rarely apply to domain-specific production tasks. 75% of interviewed teams evaluate without formal benchmarks, relying on A/B testing and direct user feedback instead.
2) Model Selection
The model selection pattern surprised researchers. 17 of 20 case studies use closed-source frontier models like Claude Sonnet 4, Claude Opus 4.1, and GPT o3. Open-source adoption is rare and driven by specific constraints: high-volume workloads where inference costs become prohibitive, or regulatory requirements preventing data sharing with external providers. For most teams, runtime costs are negligible compared to the human experts the agent augments.
3) Agent Frameworks
Framework adoption shows a striking divergence. 61% of survey respondents use third-party frameworks like LangChain/LangGraph. But 85% of interviewed teams with production deployments build custom implementations from scratch. The reason: core agent loops are straightforward to implement with direct API calls. Teams prefer minimal, purpose-built scaffolds over dependency bloat and abstraction layers.
4) Agent Control Flow
Production architectures favor predefined static workflows over open-ended autonomy. 80% of case studies use structured control flow. Agents operate within well-scoped action spaces rather than freely exploring environments. Only one case allowed unconstrained exploration, and that system runs exclusively in sandboxed environments with rigorous CI/CD verification.
5) Agent Adoption
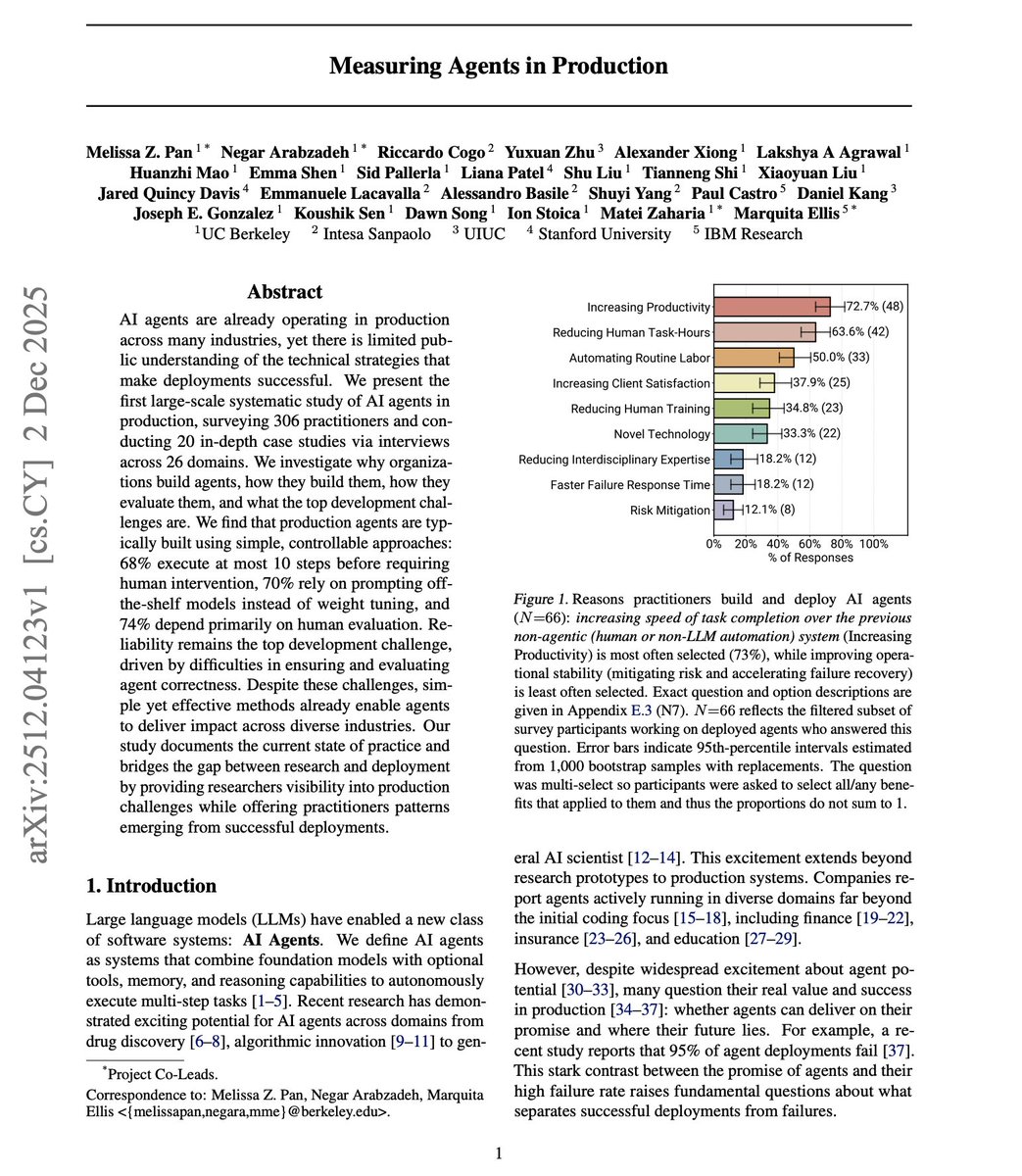
What drives agent adoption? It's simply the productivity gains. 73% deploy agents primarily to increase efficiency and reduce time on manual tasks. Organizations tolerate agents taking minutes to respond because that still outperforms human baselines by 10x or more. 66% allow response times of minutes or longer.
6) Agent Evaluation
The evaluation challenge runs deeper than expected. Agent behavior breaks traditional software testing. Three case study teams report attempting but struggling to integrate agents into existing CI/CD pipelines.
The challenge: nondeterminism and the difficulty of judging outputs programmatically. Creating benchmarks from scratch took one team six months to reach roughly 100 examples.
7) Human-in-the-loop
Human-in-the-loop evaluation dominates at 74%. LLM-as-a-judge follows at 52%, but every interviewed team using LLM judges also employs human verification. The pattern: LLM judges assess confidence on every response, automatically accepting high-confidence outputs while routing uncertain cases to human experts. Teams also sample 5% of production runs even when the judge expresses high confidence.
In summary, production agents succeed through deliberate simplicity, not sophisticated autonomy. Teams constrain agent behavior, rely on human oversight, and prioritize controllability over capability. The gap between research prototypes and production deployments reveals where the field actually stands.
Paper: https://t.co/AaNbPYDFt5
Learn design patterns and how to build real-world AI agents in our academy: https://t.co/zQXQt0PMbG
@MarioNawfal Computers today aren’t slow due to a lack of hardware capabilities but due to the simple fact that nobody pays for faster software. It’s easy to speed up software by a huge factor if you pay for it.
this is a great read by jack morris. gives such a fresh perspective on what really matters.
TLDR: with every "new" architecture, we unlocked a new source of data to use at scale. it was the large amount of data we unlocked that boosted performance not the architecture itself, and videos are the next big thing to harness.
2012: alexnet unlocked the entire imagenet dataset
2017: transformers unlocked the entire internet (as text)
2022: RLHF unlocked learning from humans
2024: reasoning unlocked learning from verifiers
2026: ???
when you look at progress this way, it becomes very very clear what the next pillar to unlock is: videos. or more specifically, youtube.
youtube stores an insane amount of video data. people upload 720.000 hours of videos to the platform every single day. thats 4.3 Petabytes of new data every day that need to be stored. for comparison, currently models are trained on a few terabytes of text.
this means that the data uploaded to youtube daily is 1000x the data used to train a typical LLM.
once we come up with an architecture that can harness videos at scale, we will see the next big jump in our quest to AGI
@backupyour8715@SCP_Hughes Have you ever tried to get from JFK to Newark in New York? I was once rebooked onto a flight at Newark, and it took hours to get there. I’ll never try that again.
It’s completely unusable now. It behaves like an insecure actor with no grasp of the subject — spouting platitudes and filler just to say something, without conveying any substance. Even the manner of speaking has become grating. I’m genuinely relieved each time I hit the daily limit and the standard mode kicks back in.
@MKBHD I don’t understand how Apple can still claim they are great at design. Actually it does not matter how the new iPhone looks because you have to put it in an ugly plastic case anyway. Same with the Mac Book Pro. It’s simply fat. I’d wish Ive was still with Apple.
@dustinmoris Just judge by the video conferencing tool they use for your first interview. If it is MS Teams you know that technology decisions are made by the finance department. Oh and if it is WebEx, the company is already dead. They never change the way they work.
@daveg I don’t know what this graph shows, but it is certainly either completely wrong or at least gravely misleading. As a German and an employer, I know a thing or two about our tax and social security system.
@Rebecca21951651@skdh Biggest difference is that the highways in Germany are in good shape while in the US many highways have potholes you can hide in. Infrastructure in the US is just broken while Europe cares much more.
@mjovanovictech The actual issue is bad database software that is not optimized for a common key type. ULIDs might only help for some databases. The cost is to break guarantees UUIDs have been invented for and leaking the creation time of all records which is a security vulnerability.
@GregoryRoccoD@hot_labor@elonmusk Well, public transport in the US is pitiful. It’s no wonder nobody uses it. In many regions, it’s absolutely useless.
This is one of the examples I teach in my ML Engineering program. The class is packed with practical tricks like this one.
The next iteration of the program starts next Monday. It's the best Machine Learning Engineering class you'll find anywhere.
https://t.co/3k4V5bemQp
@lemire I was responsible for the development of an investment banking platform. Turned out that with the right architecture we could outcompete competitors by 150x (really, 150 times faster) using Java. We compared to C, but it gave only an additional factor of 2. Not worth the trouble.
@lemire You are right. Writing fast and reliable software has little to do with the language, but with architecture and algorithm design. Eventually you reach a limit that you cannot cross without switching to a faster language. But most companies don’t care about performance anyway.
@davepl1968 That were the good old times. I used to do similar optimizations to keep applications small. A few years later I realized that the command line which invoked gcc to build our application was 300 kB in size. That made me really really sad. Efficiency is a thing of the past.
The OpenAI story keeps getting crazier.
This is the most significant 72 hours for AI that will change everything.
Here's everything you need to know & what's coming next: 🧵👇
Lucky to attend #QCon again. First time to be in #NewYork, though. I really look forward to meet and talk to new people. QCon is very special because it fosters collaboration and discussion among attendees. Thanks to the organizers for taking this approach. @qconnewyork