I just found a tool that makes your Claude Code sessions basically unlimited. It's called 9Router and it's trending on GitHub right now.
It sits between Claude Code and 60+ AI providers. One local endpoint. That's it.
When your Claude Code quota runs out, it switches to a cheaper model.
When that runs out, it drops to a completely free one. You don't notice the switch. Your session never stops.
→ Works with Claude Code, Cursor, Codex, Cline, Copilot, and more. One setup covers your entire stack.
→ Built-in token compression saves 20 to 40% on every request. Same answers, fewer tokens to get there.
→ Tracks your quota per provider in a live dashboard so you always know where you stand.
→ Translates between OpenAI, Claude, and Gemini formats automatically. Any tool talks to any provider.
The free tier alone is wild. Kiro gives you unlimited Claude Sonnet 4.5. iFlow gives you unlimited Kimi, GLM, and MiniMax. Qwen gives you unlimited Qwen 3 Coder.
Setup is two steps. Install it, point your tool at localhost:20128. Done.
For anyone burning through Claude credits mid-session or tired of hitting rate limits at 2am, this changes what's possible on a near-zero budget.
since the heatwave is gone so my GPU and ROG can reach better inference speeds.
ROG ally does more throughput than free Gemini and my GPU almost 5x free gemini.
Still 370h to go.
Using my Asus ROG ally x to run Gemma 4 12b qat. 24gb unified memory, 16g allocated for gpu, 30 token / second (no thinking). Not too bad.
I even hooked OpenClaw up with local llm backend through lmstudio with tool calls and telegram handling including transcription of my telegram voice messages.
Intelligence is getting more expensive.
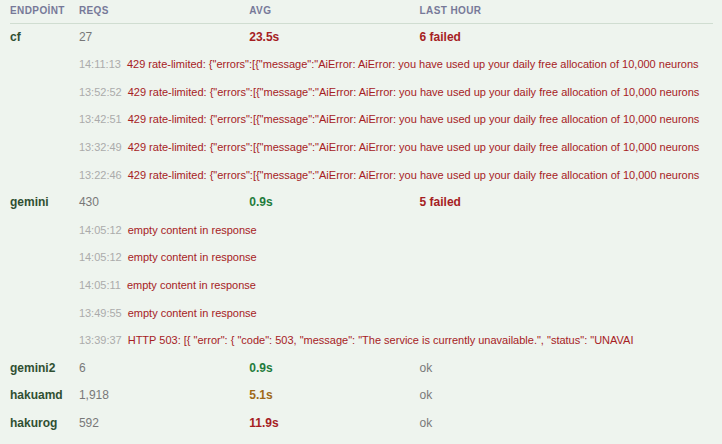
So I have been doing a study for the last 10d on how the free endpoints work out. Is self hosting LLMs worth it?
Asked Claude to build a pool of endpoints: self hosted lmstudio based 4060 TI 16G (w/ google/gemma-4-12b-qat), self hosted lms based ROG Ally X (see below), gemini flash lite free endpoint, cerebras, groq, openrouter free quota.
Task: Classify guldumnet posts if there is a need for moderation (offensive content) and do image description to explain the joke hence multi modality is essential. And i have around 500k posts so going over sequentiallybecause my self hosted vram depletes quickly if I go too parallel). With this setup it will still take 38d to finish one pass over all the posts 🤷♂️
My non-scientific ranking:
1. Gemini: Responds within a second, no sass, generous free quota, top tier OCR and Turkish understanding.
2. Groq: very fast inference, not so bad free quota (using llama-4-scout-17b-16e-instruct)
3. Cerebras: huge model (gpt-oss-120b) and very fast inference, yet doesn't support images in free mode and free quota is not so generous.
4. 4060: not bad but inference times go up to 11s. gemma-4-12b-qat is a great model for world knowledge.
5. Asus ROG (Steamdeck equivalent): Same gemma4 model, 30s mean response time but very reliable, has been running for 10 days with 0 errors, slow but sure.
6. Openrouter: worst, i even topped up 10 usd to make it pseudo free, still there is no clear guidelines about the rate limits unlike others.
I will try more free tiers soon.
Using my Asus ROG ally x to run Gemma 4 12b qat. 24gb unified memory, 16g allocated for gpu, 30 token / second (no thinking). Not too bad.
I even hooked OpenClaw up with local llm backend through lmstudio with tool calls and telegram handling including transcription of my telegram voice messages.
Ethernet port was loose and it was not reaching 1000mb/s and it was stuck at 100mb/s, needed some extraordinary measures.
(Yes old laptop as Media server, because non-arm processors are good with x265)
What Fable (almost) one-shot today: get all my emails in gmail and download their attachments and make everything searchable including pdf to markdown conversion and build a ui on top so that i can search and view things.
4h later:
Obviously @opencode zen has free models and OC is a great harness with very fast loading times, with deepseek-v4-flash you can one shot a lot of features for free.
1. Claude code (cc) for _serious_ projects like https://t.co/Ajtv25wgjU (pun)
2. Cursor CLI (agent) for everything else, Composer 2.5 is extremely powerful and fast. Generous limits for pro and you will have access to Opus models.
3. Antigravity CLI (agy) still requires some ironing for being a daily driver, nice free alternative.
4. Gemini CLI (gcli) for troubleshooting prod, being my SRE to keep things running.
For factual up-to-date text generation tasks: good budget king has just been released: google/gemma-4-12b.
Disable thinking and reach incredible token / sec speeds.
Not for coding though, qwen is still beating there.
Ai edge gallery running gemma4-e2b on pixel 10: getting close to 5-6 token / second.
Works fully offline. It also has image understanding capability.
Probably going to move guldumnet's image understanding pipeline to a local model instead gcloud vision api.