اگر هنوز نمیدونی چجوری از Codex استفاده کنی، یه آموزش جامع و کوتاه اوردم واستون که:
توی پارت اول: بیسیک هایCodex رو میگه.
پارت دوم: باهاش یاد میگیرید چجوری یه اپ یا پلتفرم بسازید بصورت کاملا عملی.
از دستش ندید 🍻 خیلی خوبه.
🥷New (1h55m) Lecture #5: "Becoming a Backprop Ninja" https://t.co/ekZgAQON3O
We take the 2-layer MLP from last lecture and backprop through all of it manually: cross entropy loss, linear layer 2, tanh, batchnorm, linear layer 1, embedding table. I give away answers in the video
Operationalizing Machine Learning: An Interview Study
18 interviews with ML engineers on the best practices and challenges for deploying machine learning models in production.
This is a recommended read for people in MLOps. Well-written.
https://t.co/4hpR8190vr
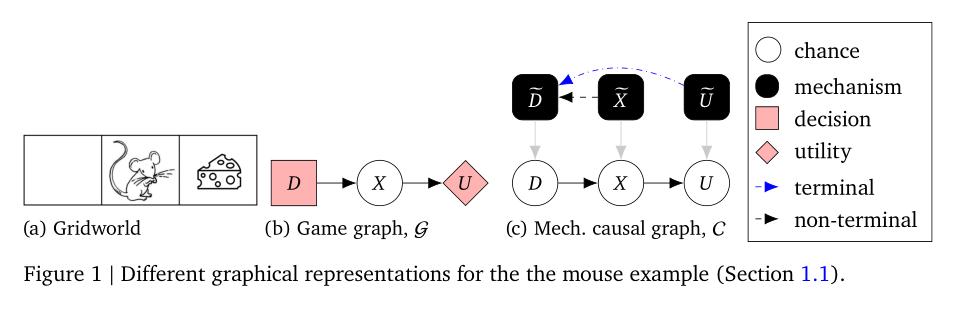
Discovering Agents
https://t.co/79U53iHSkl
Causal models of agents have been used to analyse the safety aspects of machine learning systems. This paper proposes the first formal causal definition of agents. From this...
🧵 👇
Course 3 of the new Machine Learning Specialization is now available on @Coursera! We'd launched Courses 1&2 last month, and this final course teaches unsupervised learning, recommender systems, and reinforcement learning. Check it out here: https://t.co/qHZoEqmWm2
Interested in contrastive representation learning? We use assignment theory to extend contrastive learning beyond contrasting pairs.
Contrasting quadratic assignments for set-based representation learning: https://t.co/kQ5CBSMfGu
w/ @isosnovik and @arnoldsmeulders
Neural nets are brittle under domain shift & subpop shift.
We introduce a simple mixup-based method that selectively interpolates datapts to encourage domain-invariance
ICML 22 paper: https://t.co/cvV1itWux9
w/ @HuaxiuYaoML Yu Wang @zlj11112222 @liang_weixin@james_y_zou (1/3)
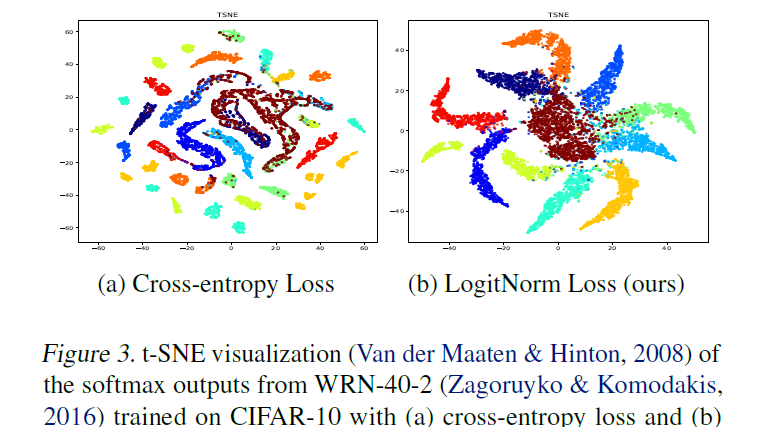
*Mitigating Neural Network Overconfidence with Logit Normalization*
#ICML paper by @OwenWei8@SharonYixuanLi
Incredibly simple method to improve the calibration of a neural network: just enforce a constant norm on the logits.
Preprint is here: https://t.co/K0Tw7uIVYo
Learn how CMT-DeepLab uses a pixel clustering method for panoptic segmentation to notably improve performance, while kMaX-DeepLab simplifies the modification further advancing the state-of-the-art. Read more and grab the code for kMaX-DeepLab → https://t.co/n3D2XKg0ty
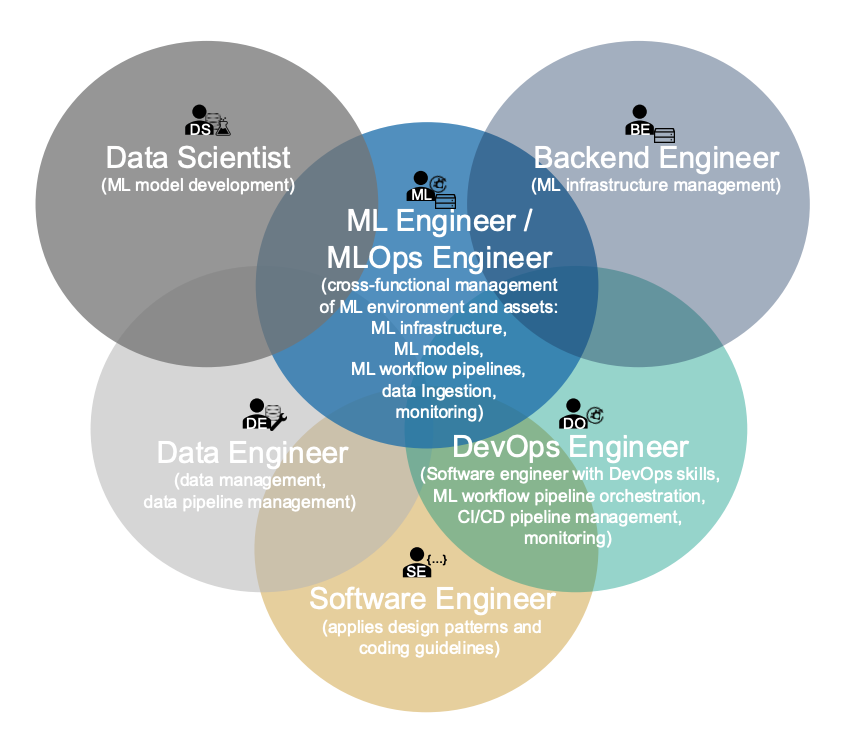
Machine Learning Operations (MLOps): Overview, Definition, and Architecture
Interesting overview of MLOPs. A great read for ML engineers.
https://t.co/29cDkUoUGm