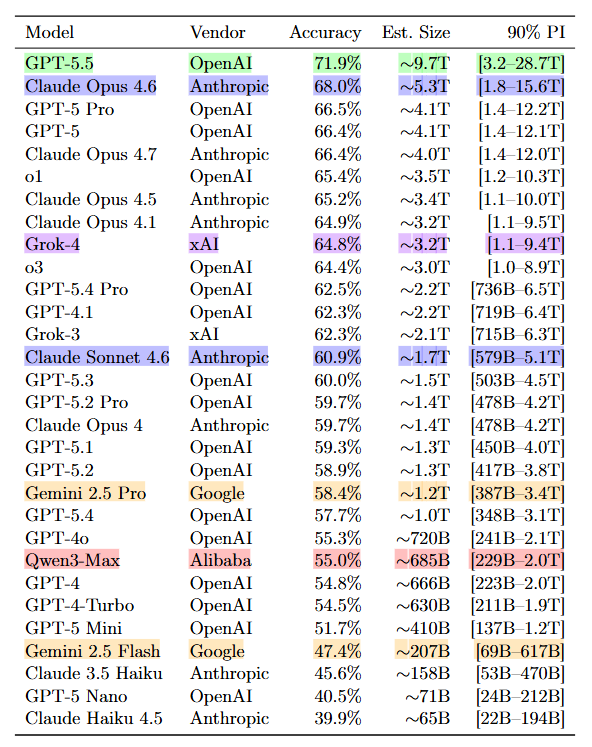
Estoy asi 🤯 con un paper que estima el tamaño de los modelos, no por los resultados del paper, sino por el proceso que usa y las conclusiones y debates que plantea, es espectacular, me deja mil ideas de cositas a probar
Los tipos probaron a ciegas su metodologia con modelos abiertos los cuales conocen los tamaños y las estimaciones les dieron con un R2 de 0.91 asi que se puede decir que el planteo que hacen tiene mucho sentido
La idea central es distinguir entre el conocimiento de baja entropia del conocimiento de alta entropia de los LLMs, y esto es lo primero giga flasheante, si bien tiene sentido intuitivamente, habia que modelar la idea y para eso usan la complejidad de Kolmogorov
La idea: "el conocimiento" que la capital de francia es Paris, es de baja entropia porq se repite ese patron/variantes francia-capital-paris en infinidad de textos del entrenamiento
En cambio una secuencia de una proteina no tan comun o por ejemplo un hash a algo especifico (y esto abre mucha tela luego), es un dato que no puede deducirse a partir de otros y poco repetido en el set de entrenamiento, como si fuera totalmente aleatorio, es un "conocimiento de alta entropia" y la unica forma de replicar muchos conocimientos de alta entropia en la inferencia es teniendo mucho espacio para almacenarlos (parametros), asi que bombardearon a los LLMs para que complete datos de este tipo y en funcion de la cantidad de datos de este tipo que "conoce" el LLM, deducen su tamaño
Eso muy resumido obviamente, hace 4 horas que estoy con este paper y aun no termino de entender algunas cosas, pero aca vienen algunas perlitas
Algo que les llamo la atencion a los tipos es lo extraño que se comportaba gemini 3.1, un outlier total que por sentido comun y contrastando latencia censuras y otras cosas, se dan cuenta que "ese" LLM en concreto estaria usando un "atajo"
Y esto es lo primero que me vuela la cabeza, porque intuitivamente es algo que vengo pensando y no entendia como la industria todavia no iba por ese lado, resulta que aparentemente Gemini 3.1 es un hibrido que tiene acceso a una base de datos interna como la de toda la vida, en realidad pareciera mas complejo, como una indexacion parametrica de weights que replican ciertos datos, pero resumamos que es como si en lugar de dedicar muchos params del modelo a aprender "de memoria" estos datos dificiles (datos de alta entropia), los tipos "liberan" al LLM de esas tareas asignando esa funcion a un subsistema que cuando aparecen secuencias con datos tipo hashes y esas cosas recurre a buscar en un indice de ese tipo de datos
o sea, en palabras simples.. es como cuando tenias que estudiar para el examen de quimica y te macheteabas esos nombres irreproducibles de cosas medio raras qu no tenian una regla nometecnica simple.. en vez de dedicar tu esfuerzo cognitivo a eso, te lo macheteabas aparte y te enfocabas en estudiar lo que si podias deducir con menos esfuerzo, asi que Gemini 3.1 pareciera estar haciendo esa "trampa" para lograr resultados similares a modelos muchisimo mas grandes con mucho menos computo (y por eso seria tanto mas barato)
Escribiria mil cosas mas de esto pero esto es tuiter, tengo que armarme un blog o algo para escribir de estas nerdeadas, en fin, sigan con lo suyo