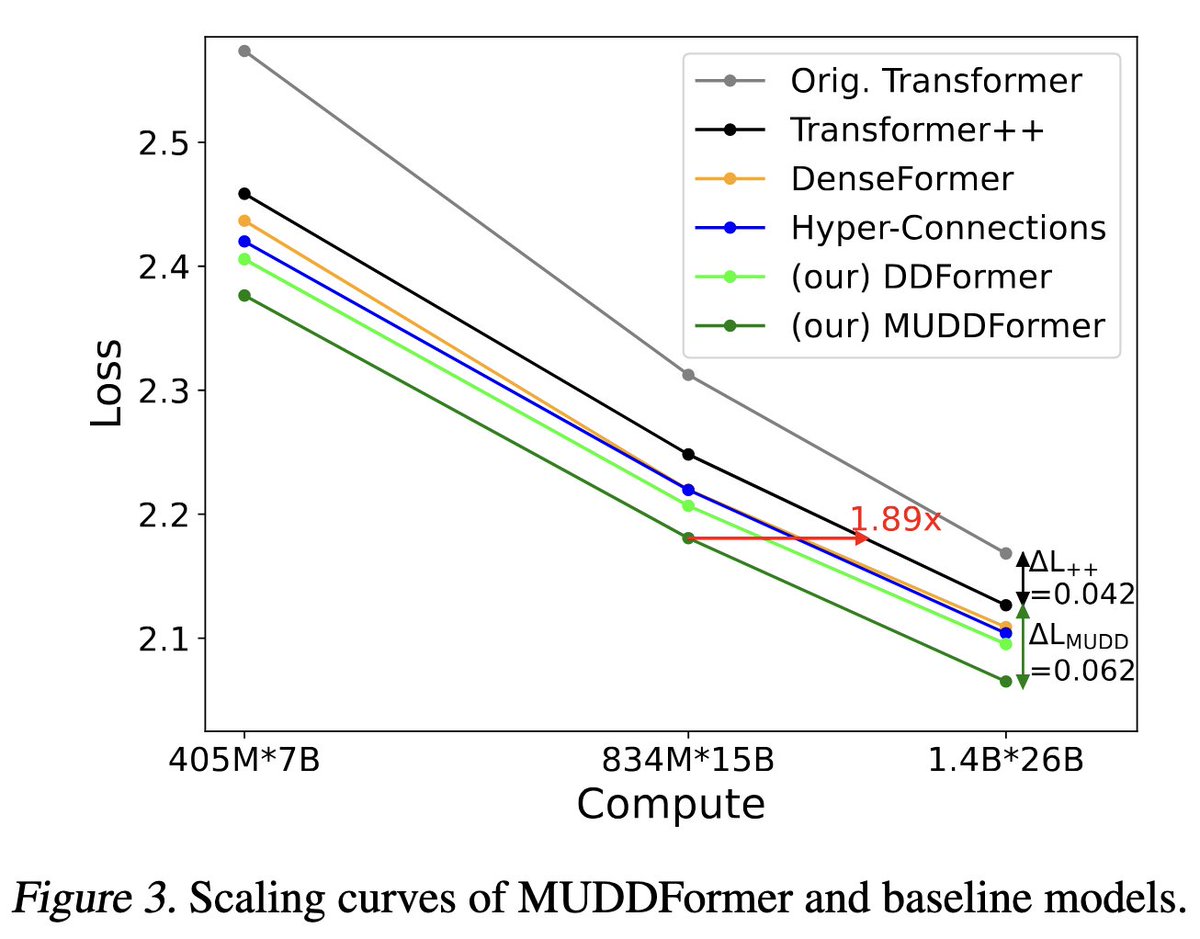
1/n [ICML 2025 paper] Glad to share our latest work, MUDDFormer, a simple yet effective method to address the limitations of residual connections and enhance cross-layer information flow in Transformers, matching ~2x Transformer++.
paper: https://t.co/rTFP4oE9d7
@aHpaBean Great work! NITP enables predicting next state, instead of next token. However, it plays a similar role of MTP. Due to wide adoption of MTP, the gain over MTP is more critical. Will the gain of NITP decrease under the MTP setting?
New NanoGPT Speedrun WR at 81.8 (-2.6s) from @.Lisennlp on Github with MUDD skip connections, an expressive and efficient mechanism for data dependent skips! Instead of a learned scalar or sigmoid(linear) gate, MUDD uses a 64 neuron 'MLP' to generate the coefficients. The key efficiency is in reusing the same input projection for up to 14 coefficients at once. https://t.co/LMPGKRPsk0
This is my best effort to add MUDD Connections to the sota baseline 20260409 by bigbigbag. It's really hard to add new components to transformer architecture in the Parameter Golf due to extra overhead introduced against the highly-optimized baseline. Although this competition is designed to surface most parameter-efficient techniques, the 10-minute track is still very sensitive to training speed, and non-record solutions struggle to stand out. So I have to carefully tune to pick out those most important cross-layer connections, a better tradeoff between performance and overhead for the 10-min track. Despite mudd connections is not adopted in the top solution, it provides a more comprehensive perspective to cover as special cases a) U-Net connections, b) mixing x0, c) two residual lanes. Moreover, it's promising and competitive in the non-record track (truly parameter-efficient region). https://t.co/kYh9H2ZmUu
parameter golf was a blast.
2,000+ submissions. 1,000+ verified github accounts. ideas ranging from quantization and depth recurrence to TTT LoRA, SSMs, H-nets, JEPA, and more.
autoresearch made iteration dramatically faster — and led to emergent bulletin boards, issue threads, unofficial leaderboards, and agent-built writeups that helped everyone learn from everyone else.
it felt like a glimpse of where interaction with AI is headed: humans setting taste and direction, agents helping explore, coordinate, and share what works.
our goal was simple: make ml research accessible to anyone, anywhere.
it was amazing to see that happen.
full recap: https://t.co/FxvcbImWzL
future events: https://t.co/qanojnkjmJ
In MUDDFormer, we split residual stream to Q/K/V/R streams, and ablation studies show V-stream is more important than Q/K-stream, despite QK-stream is effective. Value Residual or V-stream creates a clean pathway transmitting low-level information to upper layers, without polluting residual stream at upper layers, which is consistent with increased head utilization at upper layers. In Transformer, residual streams at upper layers have to erase or dilute low-level embedding information to highlight key information predicting the next token, so attention heads tend to not be activated. https://t.co/247wiVLEHl
[CL] Weight Tying Biases Token Embeddings Towards the Output Space
A Lopardo, A Harish, C Arnett, A Gupta [EleutherAI & UC Berkeley] (2026)
https://t.co/dvkwkGyPJq
Depthwise attention/recurrence is becoming a trend!
After ByteDance's HC (ICLR'24), our MUDDFormer (ICML'25) & Google's DSA (ICML'25), more labs are joining: ByteDance's VWN, DeepSeek's mHC, MoonshotAI's AttnRes, etc.
MUDDFormer's key design: input-dependent weights with multiway decoupling across Q/K/V/residual streams. Only +0.23% params, 1.8×–2.4× compute advantage.
This is just the beginning. More fundamental architecture innovations to come.
https://t.co/QLkh9nPn9S
https://t.co/2JZgW975Fh
@osieberling Decoupling residual stream into 4 streams QKVR can further improve the performance as done in MUDDFormer (or DeepCrossAttention). Full AttnRes is roughly equivalent to DynamicDenseFormer(DDFormer).
https://t.co/rTFP4oE9d7
Great to see depth-wise attention mechanisms like mHC and Attention Residuals (AttnRes) proving their scalability in large-scale models, and attract more attention to this line of work, including DenseFormer, HC, DeepCrossAttention (DCA) and our MUDDFormer (ICML25). We proposed multi-way dynamic dense connections along transformer layers to address the limitation of residual connections, where DynamicDenseFormer is similar to Kimi's Full AttnRes. I'd like to compare decoupling of residual streams, PP, training stability and details on depth attention weights.
1. Decoupled residual streams
In MUDDFormer, we decouple the residual stream into 4-way/stream QKVR—a strategy also explored in the concurrent DCA, which is effective but absent in recent practices. We are motivated by different attribution circuits, like Q-attribution, V-attribution in mechanistic interpretability studies. Decoupled residual streams can better handle cross-layer information flow. In mHC and AttnRes, depth-wise attention is applied before each Attention and FFN block, so they can be seen as a 2-stream residual.
2. Pipeline Parallelism (PP)
Efficiency is the primary bottleneck for dense cross-layer connections. Kimi addresses this via Block AttnRes, which reduces communication by attending to block-level summaries, while HC compresses the residual stream into hyper hidden states (typically 4 times wide) to reduce communication. In DenseFormer/MUDDFormer, key-wise dilation on dense connections is also a simple approach to reduce PP overhead. If PP is not a strict requirement (e.g., in TPU-based pretraining), MUDDFormer already demonstrates strong performance, and query-wise dilation can further provide an excellent balance between performance and efficiency.
3. Training stability & Depth attention weights
To stabilize the residual mapping, mHC proposed the Sinkhorn-Knopp algorithm, while MUDDFormer tackles training stability by PrePostNorm in deep models. In HC and AttnRes, depth attention weights are dependent on key-wise layer outputs, while MUDDFormer utilizes a small MLP to generate weights from the query-wise hidden states.
1/n [ICML 2025 paper] Glad to share our latest work, MUDDFormer, a simple yet effective method to address the limitations of residual connections and enhance cross-layer information flow in Transformers, matching ~2x Transformer++.
paper: https://t.co/rTFP4oE9d7
@orvieto_antonio I use gemini to generate a loss landscape image reflecting the sharpness of the river and valley. Is this more aligned with your mind?
Another ByteDance Seed banger?
They introduce the looped language models (LoopLMs) Ouro 1.4B and 2.6B trained on 7.7T tokens, that match evaluation results of larger 4B and 8B models respectively.
"Ouro" 1.4B is a standard decoder-only Transformer with 24 layers (upcycled Ouro 2.6B = 48 layers), MHA, RoPE, SwiGLU and sandwich norm. This stack is repeatedly applied for T recurrent steps, avoiding the usual collapse of latent state to token space, therefore enabling deeper latent multi-hop reasoning.
Like test-time-compute this approach trades more forward passes for additional performance, but with the additional benefit that models are smaller and have more effective depth.
Additionally, they add a learned exit gate to allow early exit on simpler inputs improving the performance-cost trade-off.
Training Pipeline:
The pipeline is staged: warmup → big pretrain → CT-annealing → LongCT (push context, 64k) → mid-training and then a small reasoning SFT pass to make the "Ouro-Thinking" variants. The 2.6B model is an upcycled continuation of the 1.4B run (stack doubled to 48 layers).
Benchmark results:
- in synthetic 3-hop QA tasks they found that looped models learn the task with fewer examples compared to non looped, iso-parameter model
- the looped architecture seems to help with safety as models are better able to distinguish benign prompts from harmful prompts as the number of recurrent steps increases
- furthermore they demonstrated improved faithfulness of the reasoning using linear probes to predict responses in the next recurrent step and observe low predictability - they claim: "this systematic disagreement across steps when i <= 4 is precisely what a faithful latent process should exhibit: the model is updating its decision as recurrence deepens, and intermediate predictions are not frozen rationalizations of the final output"
Some issues:
- They state: "A defining advantage of the LoopLM architecture lies in its capacity for adaptive computation allocation", but find that performance does not increase by scaling recurrence beyond the trained T=4 depth (Table 10) - no extrapolation, which means more training is necessary
- 4 recurrent steps mean 4x the FLOPs during inference. So ultimately Ouro-1.4B model with 4 recurrent steps would use more FLOPs than a Qwen3-4B, but less memory
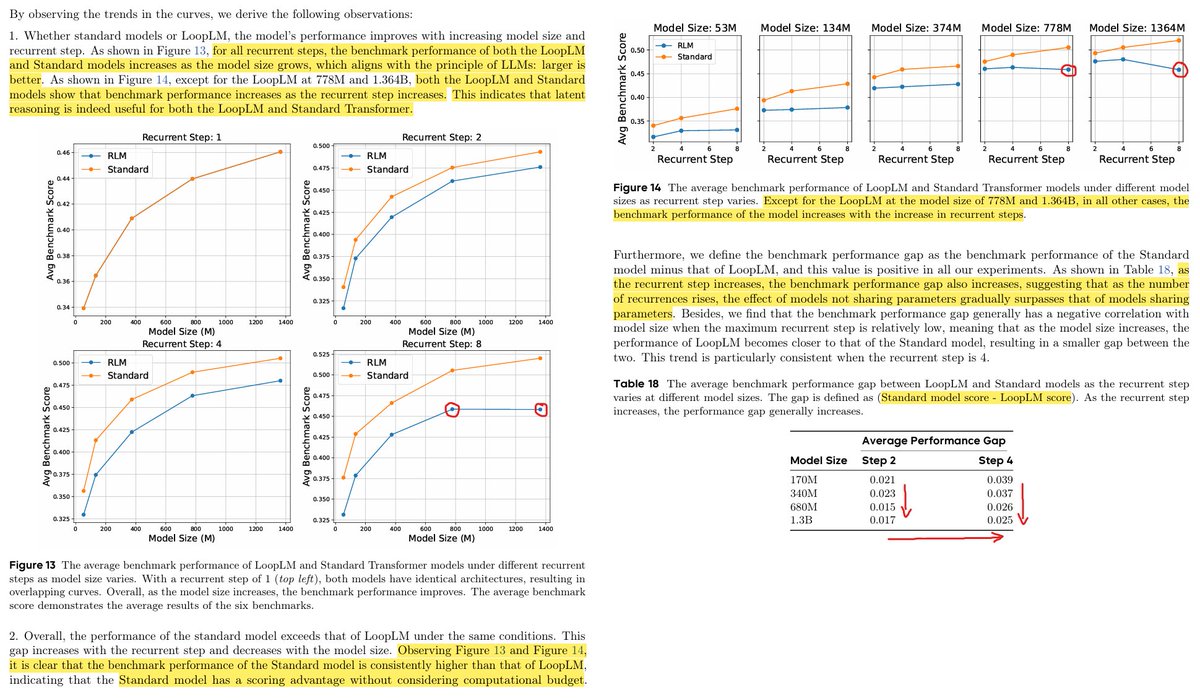
- in the appendix they under D.1 they pose the question: "What is the performance gap between standard models and LoopLM?". For this they compare 5 different model sizes: 53M, 134M, 374M, 778M, and 1.36B with recurrent depths: 1, 2, 4, and 8, trained on 20B tokens. The Standard Transformer in this case at depth 2, 4 and 8 has effectively 2, 4 and 8 times more layers and ~params(untied).
They find that the Standard Transformer consistently outperforms LoopLM. Furthermore, LoopLM shows no performance increases with 8 recurrent steps. The 8 recurrent step 1.36B model is actually worse than the 778M model with 4 steps.
Furthermore as seen in Table 18, the performance difference decreases the larger the models get, but increases with the number of steps/recurrence
-> LoopLM is generally worse per-FLOP in compute-matched tests (untied depth wins), but it’s strong per-parameter and under memory/KV constraints.
- their RL stage did not yield significant performance gains over the final SFT checkpoint: they blame model saturation and infrastructure challenges
- they had to lower the number of recurring steps during training from 8 to 4 due to stability issues
other notes:
- looping does not increas eknowledge capacity nor improve capacity scaling
- KV-cache can't be reused during pre-fill, but can be reused for decoding
- recurrent architectures require smaller learning rates compared to standard transformers of equivalent parameter count
@XiaohuaZhai As the second plot shown, we can keep ~baseline quality with p_s=0.5. In contrast, with p=0.8, RINS shows too much improvement over baseline, which counter-intuitively even matches performance of the best AAAB model (p_s=0, 2x inference cost). Could you give some explanation?
@ibomohsin@XiaohuaZhai Excellent work! To reproduce RINS, I trained two 150M llama models(AB, AAAB) on the Pile dataset over 105B tokens, with a loss gap of 0.012, smaller than ~0.04 in the paper. I also failed to reproduce the adapter with unstable training. Can I DM you for further help?
Excited to present this work in Vancouver at #ICML2025 today 😀 Come by to hear about why in-context learning emerges and disappears:
Talk: 10:30-10:45am, West Ballroom C
Poster: 11am-1:30pm, East Exhibition Hall A-B # E-3409
Want to learn about the research behind Gemma 3n?
Altup - https://t.co/ngwMI7UfIw
LAuReL - https://t.co/2KE997GDWV
MatFormer - https://t.co/AnHhQktcZu
Activation sparsity - https://t.co/CxoPEOMdkU
Universal Speech Model - https://t.co/TuP8XMeYKS
Blog - https://t.co/TKIO4yJVhk
@GauravML Congratulations! We also concurrently propose MUDDFormer, with dynamic and multi-way connections to previous layers. Hope enhanced cross-layer connections can be adopted in more architectures. https://t.co/rTFP4oE9d7







![fly51fly's tweet photo. [CL] Weight Tying Biases Token Embeddings Towards the Output Space
A Lopardo, A Harish, C Arnett, A Gupta [EleutherAI & UC Berkeley] (2026)
https://t.co/dvkwkGyPJq https://t.co/Q5YV5lyOgg](https://pbs.twimg.com/media/HEsI_aSbgAETkEv.jpg)
![fly51fly's tweet photo. [CL] Weight Tying Biases Token Embeddings Towards the Output Space
A Lopardo, A Harish, C Arnett, A Gupta [EleutherAI & UC Berkeley] (2026)
https://t.co/dvkwkGyPJq https://t.co/Q5YV5lyOgg](https://pbs.twimg.com/media/HEsI_PpbAAAR723.jpg)
![fly51fly's tweet photo. [CL] Weight Tying Biases Token Embeddings Towards the Output Space
A Lopardo, A Harish, C Arnett, A Gupta [EleutherAI & UC Berkeley] (2026)
https://t.co/dvkwkGyPJq https://t.co/Q5YV5lyOgg](https://pbs.twimg.com/media/HEsI-7JaQAA-LS-.png)








![fly51fly's tweet photo. [CL] Weight Tying Biases Token Embeddings Towards the Output Space
A Lopardo, A Harish, C Arnett, A Gupta [EleutherAI & UC Berkeley] (2026)
https://t.co/dvkwkGyPJq https://t.co/Q5YV5lyOgg](https://pbs.twimg.com/media/HEsI_mMbAAAUCf4.jpg)