New NanoGPT Speedrun WR at 81.8 (-2.6s) from @.Lisennlp on Github with MUDD skip connections, an expressive and efficient mechanism for data dependent skips! Instead of a learned scalar or sigmoid(linear) gate, MUDD uses a 64 neuron 'MLP' to generate the coefficients. The key efficiency is in reusing the same input projection for up to 14 coefficients at once. https://t.co/LMPGKRPsk0
In MUDDFormer, we split residual stream to Q/K/V/R streams, and ablation studies show V-stream is more important than Q/K-stream, despite QK-stream is effective. Value Residual or V-stream creates a clean pathway transmitting low-level information to upper layers, without polluting residual stream at upper layers, which is consistent with increased head utilization at upper layers. In Transformer, residual streams at upper layers have to erase or dilute low-level embedding information to highlight key information predicting the next token, so attention heads tend to not be activated. https://t.co/247wiVLEHl
Depthwise attention/recurrence is becoming a trend!
After ByteDance's HC (ICLR'24), our MUDDFormer (ICML'25) & Google's DSA (ICML'25), more labs are joining: ByteDance's VWN, DeepSeek's mHC, MoonshotAI's AttnRes, etc.
MUDDFormer's key design: input-dependent weights with multiway decoupling across Q/K/V/residual streams. Only +0.23% params, 1.8×–2.4× compute advantage.
This is just the beginning. More fundamental architecture innovations to come.
https://t.co/QLkh9nPn9S
https://t.co/2JZgW975Fh
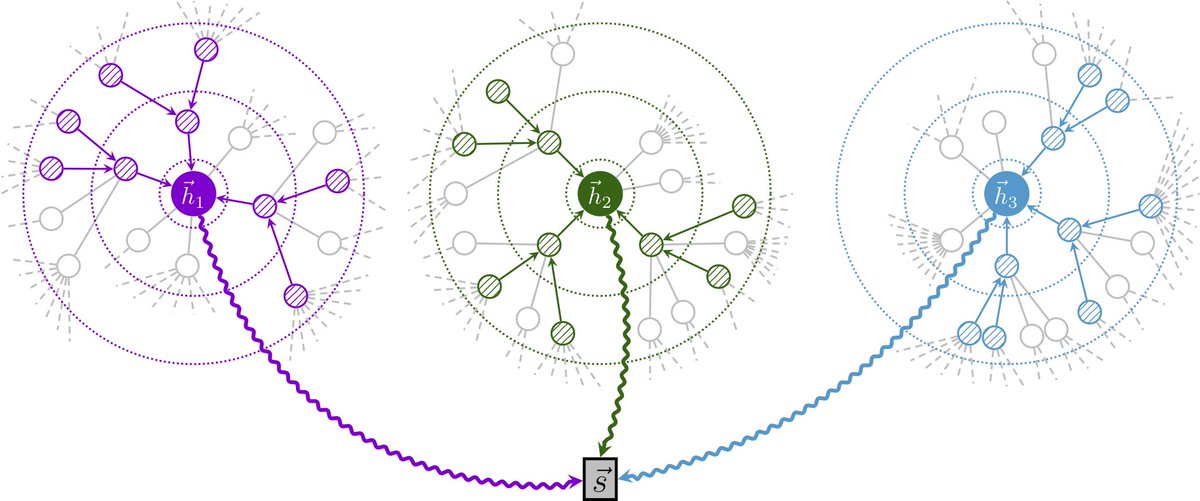
Great to see depth-wise attention mechanisms like mHC and Attention Residuals (AttnRes) proving their scalability in large-scale models, and attract more attention to this line of work, including DenseFormer, HC, DeepCrossAttention (DCA) and our MUDDFormer (ICML25). We proposed multi-way dynamic dense connections along transformer layers to address the limitation of residual connections, where DynamicDenseFormer is similar to Kimi's Full AttnRes. I'd like to compare decoupling of residual streams, PP, training stability and details on depth attention weights.
1. Decoupled residual streams
In MUDDFormer, we decouple the residual stream into 4-way/stream QKVR—a strategy also explored in the concurrent DCA, which is effective but absent in recent practices. We are motivated by different attribution circuits, like Q-attribution, V-attribution in mechanistic interpretability studies. Decoupled residual streams can better handle cross-layer information flow. In mHC and AttnRes, depth-wise attention is applied before each Attention and FFN block, so they can be seen as a 2-stream residual.
2. Pipeline Parallelism (PP)
Efficiency is the primary bottleneck for dense cross-layer connections. Kimi addresses this via Block AttnRes, which reduces communication by attending to block-level summaries, while HC compresses the residual stream into hyper hidden states (typically 4 times wide) to reduce communication. In DenseFormer/MUDDFormer, key-wise dilation on dense connections is also a simple approach to reduce PP overhead. If PP is not a strict requirement (e.g., in TPU-based pretraining), MUDDFormer already demonstrates strong performance, and query-wise dilation can further provide an excellent balance between performance and efficiency.
3. Training stability & Depth attention weights
To stabilize the residual mapping, mHC proposed the Sinkhorn-Knopp algorithm, while MUDDFormer tackles training stability by PrePostNorm in deep models. In HC and AttnRes, depth attention weights are dependent on key-wise layer outputs, while MUDDFormer utilizes a small MLP to generate weights from the query-wise hidden states.
@eliebakouch you can give a try to our DCMHA arXiv 2405.08553, which is a stronger version of Noam's talking-heads attn (see Table 9). Note that torch.compile is needed for efficient training.
@GauravML Congratulations! We also concurrently propose MUDDFormer, with dynamic and multi-way connections to previous layers. Hope enhanced cross-layer connections can be adopted in more architectures. https://t.co/rTFP4oE9d7
@SonglinYang4@zhxlin great work! then how does PaTH compare to DeltaNet and how does PaTH-Fox compare to Gated DeltaNet? Does softmax increase KV cache while bring any benefits over linear attention?
The JAX team just released this amazing book on how to scale LLMs.
It contains 11 chapters in total, and it goes into very low-level analysis of what LLMs are doing at the hardware level and how to reason about performance in these complex distributed systems.
I make all the graphics in my papers (e.g. the one below) using TikZ. I'm pathologically bad at drawing, so programming my own figures is basically the only way to stay sane.
I open-source all of my figures' codes here:
https://t.co/YzX0JrnVpL
Feel free to re-use (w/ credit :) )
8) For more details and results:
- Paper: https://t.co/aqrDdCpYQF
- JAX/PyTorch code, pretrained models: https://t.co/1XYlxmFJ8b
Joint work with @hilbertmeng and other guys at @CaiyunApp
Welcome to comment and discuss! @arankomatsuzaki@_akhaliq
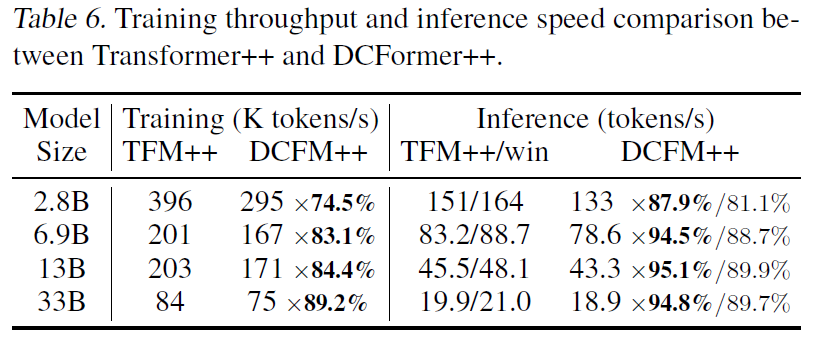
Excited to share our work on Dynamically Composable Multi-Head Attention (DCMHA), a drop-in replacement of MHA in any transformer arch. DCFormer matches the performance of ~1.7–2× compute Transformer across different architectures and model scales. Accepted as ICML 2024 (oral) 🪜
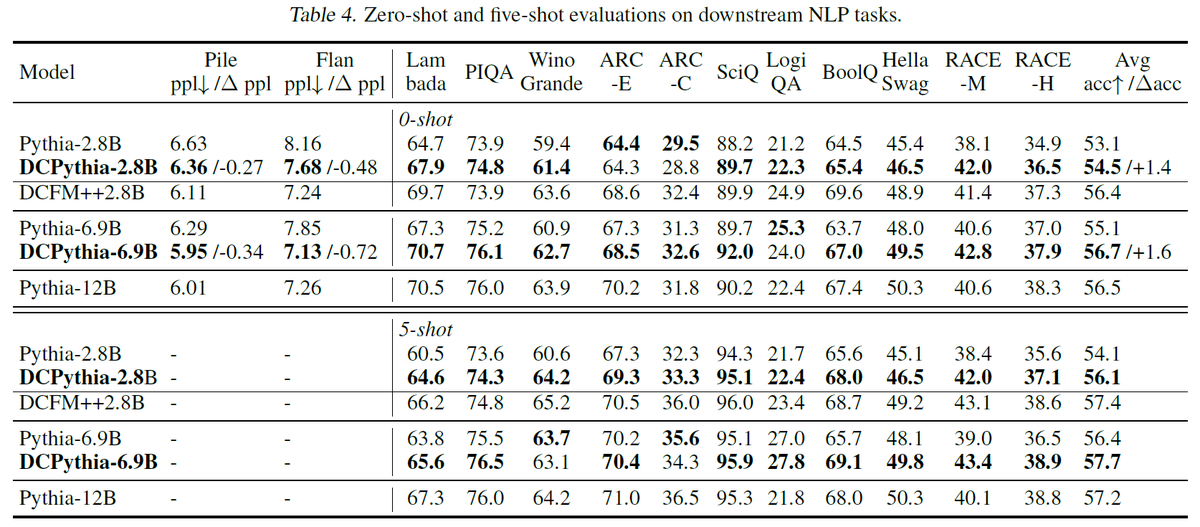
7) More results: We train DCPythia-2.8B/6.9B w/ the same HPs as the counterpart Pythia models on 300B tokens from Pile. DCPythia models significantly outperform Pythia models on downstream eval. DCPythia-6.9B is better than Pythia-12B.
Model size ↗️, improvement ↗️, overheads ↘️
Summary of expert recommendations for
#ICLR2024 and #ICML2024 attendees:
1. Innsbruck for the mountains, the scenery and the hikes.
2. "Königssee" and "Salzburg"
3. Walk the length of the Ringstrasse, see the Karlskirche, go to Cafe Central. Melker Stiftskeller for dinner
4. https://t.co/kDIjBt5n4d
5. Hallstatt
6. Gosausee and Grossglockner High Alpine Road
7. The Messe Wien Exhibition center
8. Natural History Museum (NHM)
9. Show at the State Opera
Thanks to all the experts who recommended 😍.
Two free medium-compute Mixture-Of-Experts research ideas:
Prerequisite: Mixtral 8x7B is 32 layers, at each layer there are 8 experts, each token is assigned to 2 experts at a given layer.
1) Dynamic Expert Assignment in MoE Models
Every token is assigned to 2*32=64 experts in total across all layers.
Can we relax how we distribute the number of experts assigned to a given token at a given layer similarly to what Mixture-of-Depths did? Can we e.g. allow for more experts per token in later layers than in early layers, while keeping the total number of experts per token (=64) fixed? Can we learn how to condition this on the token itself?
Do we need to keep the total number of experts per token fixed? - To keep the inference time constant for a given query it should be enough to keep the average number of experts per token fixed but we can relax it across the tokens. For example, given a sequence of 100 tokens, we have 100 * 64 expert assignments - what’s the optimal way to distribute this compute budget across tokens and model depth?
Ideally, to teach the model how to do it, while aiming to minimise compute needed, I would start from a pre-trained MoE LLM and do short (~% of the original pre-training) fine-tuning. Inference is what matters in the end anyways.
References: https://t.co/dAhGislMKv, https://t.co/q9QlIkRXRD
2) Retrofitting MoE LLMs to Share Experts Across Layers
There are 32 * 8 = 256 experts in Mixtral 8x7B.
Could we concatenate all experts from all layers to create one gigantic MoE layer with 256 experts and replace every MoE layer in the original model with this gigantic one (share it so that the parameter count is not affected)?
Similarly to 1), to teach the model how to make use of the extra choices at each layer, we would do short retrofitting. We don’t want to crash the model with our layer swap so at every layer we would initialise the routing function to behave similarly to how it was before conversion (bias the routing function to the experts that the layer had access to before).
Possible benefits: a) Parameter Efficiency: once we retrofit the routing functions it might happen that some of the experts would be shared across layers and some would become obsolete and could be easily pruned; b) Improved Accuracy: having access to more experts at each layer could result in a performance boost while the parameter count and the number of activated parameters during inference is kept constant.
Reference - https://t.co/3zKhKMOL5s
Reference to both ideas about how to retrofit the pre-trained model to a more efficient variant: https://t.co/uUnh4g92VX
// concept stolen from @jxmnop