#COLM2025 We introduce Adaptive Computation Pruning (ACP) for the Forgetting Transformer (FoX) — a provably safe pruning method that significantly speeds up our Forgetting Attention kernel, especially for long-context pretraining. Our simple Triton kernel with ACP is 1.7x to 2.4x faster than the official FlashAttention2 kernel when pretraining 760M-param models with context lengths from 4k to 16k on 4xL40S!
• Code: https://t.co/AuqqoqjYJ3
• Paper: https://t.co/joohFxw9ey
Joint work with @johanobandoc, Xu Owen He, @AaronCourville, from @Mila_Quebec and @makermaker_ai
More details👇
New paper 🧵
We show that dynamic short convolutions consistently improve Transformers across scales. We make these gains practical with an efficient parameterization and custom Triton GPU kernels.
The improvements carry over to MoEs and linear attention variants (Mamba-2/GDN).
After Wall Attention, I now have an updated version of my blog post on positional embeddings derived from SSMs.
Only KDA remains to complete the table, and it is Path+Wall PE! It may even be done by now.
Check it out 👇
https://t.co/F6H9qpbZAE
🧠 New paper: "How and What to Imagine? Visual Thinking in Unified Multimodal Models for Cross-View Spatial Reasoning"
Cross-view spatial reasoning is hard for VLMs. Language-only reasoning loses geometry.🧵👇
A bit surprising to see that FoX doesn't look very good in the comparisons though, especially in needle retrieval... Might be some strange interaction between the training setting and FoX 🤔
Interesting method that applies per-channel multiplicative decay to QK inner products, orthogonal to FoX's additive decay bias. The blog post is also very well written with informative details and ablations!
~1/7~Introducing Parallax → a stronger attention variant that achieves a Pareto improvement over vanilla attention at 0.6B and 1.7B scales.
Parallax has better perplexity, better downstream accuracy, and a decode kernel that matches or beats FlashAttention.
🧵
🚀 One of the most exciting features of our Nemotron-Labs-Diffusion is Tri-Mode Support:
AR mode for accuracy, diffusion for speed, and self-speculation with diffusion drafting + AR verification for AR-level accuracy at much higher speed.
Check out our paper for more details!
LLM training is built on fast MatMuls. But many surrounding ops still run as memory-bound kernels.
CODA reparameterizes them to hide in the matmul’s shadow, fused into its epilogue before results leave the chip.
Bonus: LLMs can write fast CODA kernels too (approaching SoLs).
Excited to see that Markovian Thinker contributed to Zyphra's strong release 🚀. Their Markovian RSA: markovian thinking (carrying forward bounded-length reasoning tails) + RSA (recursive self-aggregation) boosted test-time compute to be on-par with larger reasoning models. 1/
1/ SSMs struggle on recall benchmarks due to their fixed-size state. But are current models actually storing context “wisely”?
Introducing Raven 🐦⬛, the first SSM with selective memory allocation! Raven achieves SOTA performance on recall-heavy tasks with the highest length generalization, extending up to 16× beyond its training sequence length. Raven is a strict upgrade over SWA in the way it stores past context!
This is the most elegant model I’ve been involved in designing so far shoutout to @avivbick and @_albertgu for their trust and amazing work!
Check out how Raven bridges between SWA and SSM👇
🥳 Excited to share that our paper "Stable Deep Reinforcement Learning via Isotropic Gaussian Representations" has been accepted at #ICML2026 Spotlight (Top 2.2%)✨
📄Paper: https://t.co/tUFlyMHeQx
💻Code: https://t.co/xFN1ErauD3
🫶Wonderfull collaboration with @aspa1313, @AaronCourville, @PouyaBashivan and @pcastr.
✈️ See you all in Korea 🇰🇷
Excited to share that our paper "Long-Horizon Model-Based Offline Reinforcement Learning Without Explicit Conservatism" has been accepted at ICML 2026!
Thanks to everyone who supported and contributed to this work.
📄 https://t.co/ck6Ju0dcQh
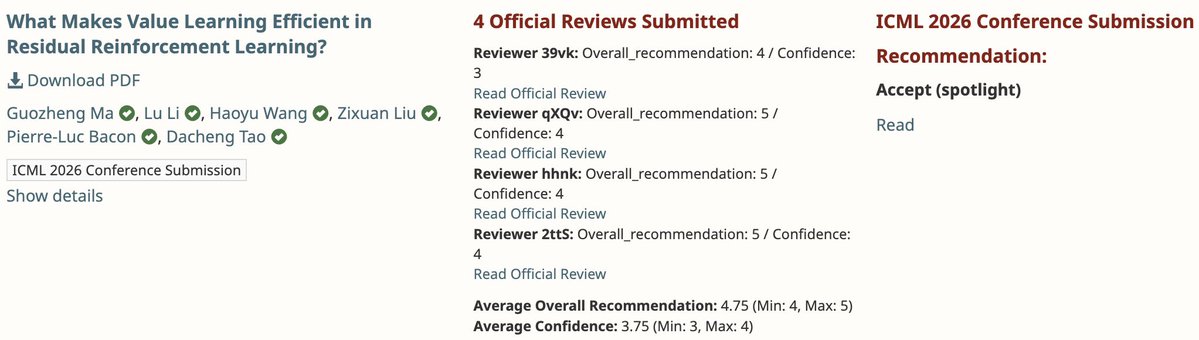
Our "What Makes Value Learning Efficient in Residual RL?" accepted to #ICML2026 as a ✨Spotlight✨!
Value learning silently fails in residual RL. We pinpoint why, and propose 𝐃𝐀𝐖𝐍: a minimal fix that delivers ~5× faster convergence across benchmarks, policies, and modalities.
📄 Preprint: https://t.co/Bm76uflaZS
Our paper VLA-MBPO got into ICML! 🎉
Model-based RL has always been the “high potential, painful to tune” corner of RL. But our work pushes a classic MBRL algorithm (MBPO) to a new level: one shared set of hyperparameters sweeps every sim & real-robot env — no per-task tuning.
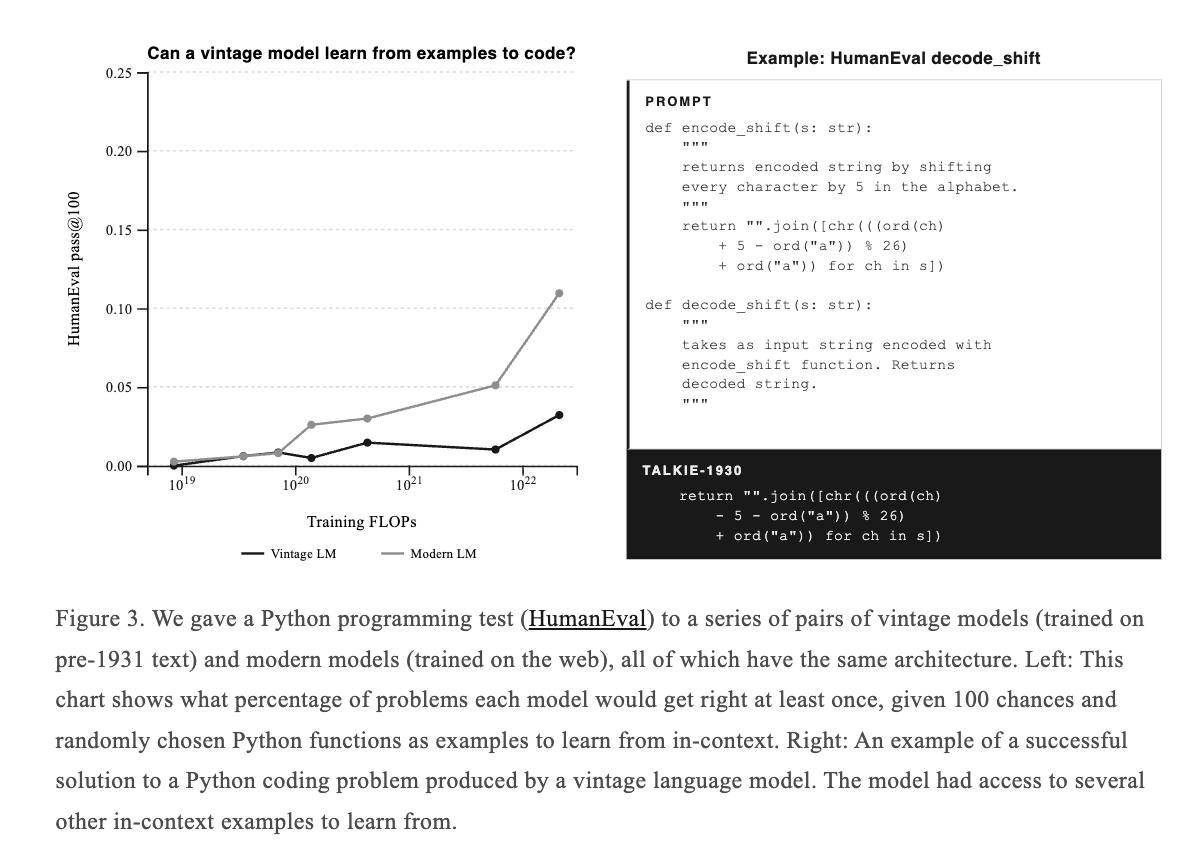
Recipes for teaching language models to handle long inputs don't work equally well across model families.
We wanted to know why—is it the architecture, the training data, or both? 🧵
🌩️Introducing FlashQLA: high-performance linear attention kernels on TileLang.
⚡ 2-3× fwd, 2× bwd speedup.
💻 Purpose-built for agentic on your personal devices.
1. Gate-driven auto intra-card CP.
2. Hardware-friendly reformulation.
3. TileLang fused warp-specialized kernels.
🔥 The AutoRL workshop is shaping up to be an exciting venue. If your work aligns, we strongly encourage you to submit. Great talks and an exciting panel will be announced soon. #RLC@RL_Conference