Only 1 week left for TDWG 2026 Call for Abstracts: https://t.co/DKMY25qkRh
Calling on the @imageomics, #biodiversity, @GBIF, @eol communities to consider contribution to session SYM25 "From Mobilizing Data to AI-Ready Knowledge: Infrastructure for Multimodal Biodiversity Data"
Only 1 week left for TDWG 2026 Call for Abstracts: https://t.co/DKMY25qkRh
Calling on the @imageomics, #biodiversity, @GBIF, @eol communities to consider contribution to session SYM25 "From Mobilizing Data to AI-Ready Knowledge: Infrastructure for Multimodal Biodiversity Data"
Join us today (4/20) at 4 PM EST on Zoom with Dr. Beth Cimini to explore how image analysis unlocks hidden insights in biology.
Register: https://t.co/uJ3K4zQ5fp
Increasing participation at events promoting #OpenScience and #OpenSource in #bioinformatics:
Call for the first 2026 round of the OBF Event Fellowship & overview of the overall round of 2025:
https://t.co/MTYQgDIcDW
Don't miss the Imageomics Seminar “Rethinking the Semantics of Biological Trait Recognition” with Sabina Leonelli on interoperable data, bio-ontologies, and ethics in AI science on February 23rd at 4-5PM EST!
Register: https://t.co/a5LKe2Uo9E
Our catalog is feature-rich but also a single-page app easy to deploy and host sustainably. It's the benefit from making datasets, models, and codebases FAIR through utilizing public repository infrastructure (GH, HF) and, importantly, their respective metadata support mechanisms
📢The Imageomics Catalog is now available! Explore and discover public code, datasets, models, and spaces; all in one location! BioClip 2, TreeOfLife-toolbox, and so much more! 🖥️🔬https://t.co/ngo48QSqQH #AIforNature#Imageomics#OpenScience#FAIROS#AIforScience
We’re recruiting! Dryad is looking for a full-time #datacurator to join our team. Fully remote, but fully supported. If you have a passion for research data quality and open data publication, then take a look: https://t.co/iPak3sXpKR.
Here's the thing. We have **NO IDEA** how to pick good graduate students. I served on admission committees for 10+ years, and chaired a few, and what I learned is that all the spreadsheets of grades and test scores and recommendations and essays and publications and interview rubrics are just an elaborate ruse to pretend we know what we're doing when we simply don't. Many of the most highly ranked applicants to our "top" program flamed out quickly, and tons of the students we summarily rejected have turned into amazing scientists. But in the name of creating meritocratic seeming rankings that are more about creating a workforce than great scientists (a system that anyone paying attention knows is bullshit), we've created a homogenous process adopted by nearly all institutions that has stamped out the one thing we should be striving for - given our lack of any clear understanding of what leads to success - a wide range of difference talents and experiences.
We’re excited to announce the #BeetlePalooza2024 workshop coming up in August. Apply to attend before June 10!
Help shape the future of biodiversity data collection with #ai and #computervision
A very useful paper by @MegBalk with @hlapp and colleagues we start to work up the image infrastructure needs for https://t.co/HU9NCSOydo - see https://t.co/b6jNOn4WRT
Wow, @ProjectJupyter is the winner of the White House OSTP "Technical Advancement to Enable Open Science" category.
Amazing to see recognition of the project at a national level! Makes me proud of the ecosystem of interconnected tools we've built.
https://t.co/EQapI37In7
ICYMI, some super exciting biology & medical ML models were recently released 🤩
They span from longitudinal EHR, to antibodies, to biological (taxonomy) classification, to large-scale unsupervised medical imaging models
Check them out! 🧵⬇️
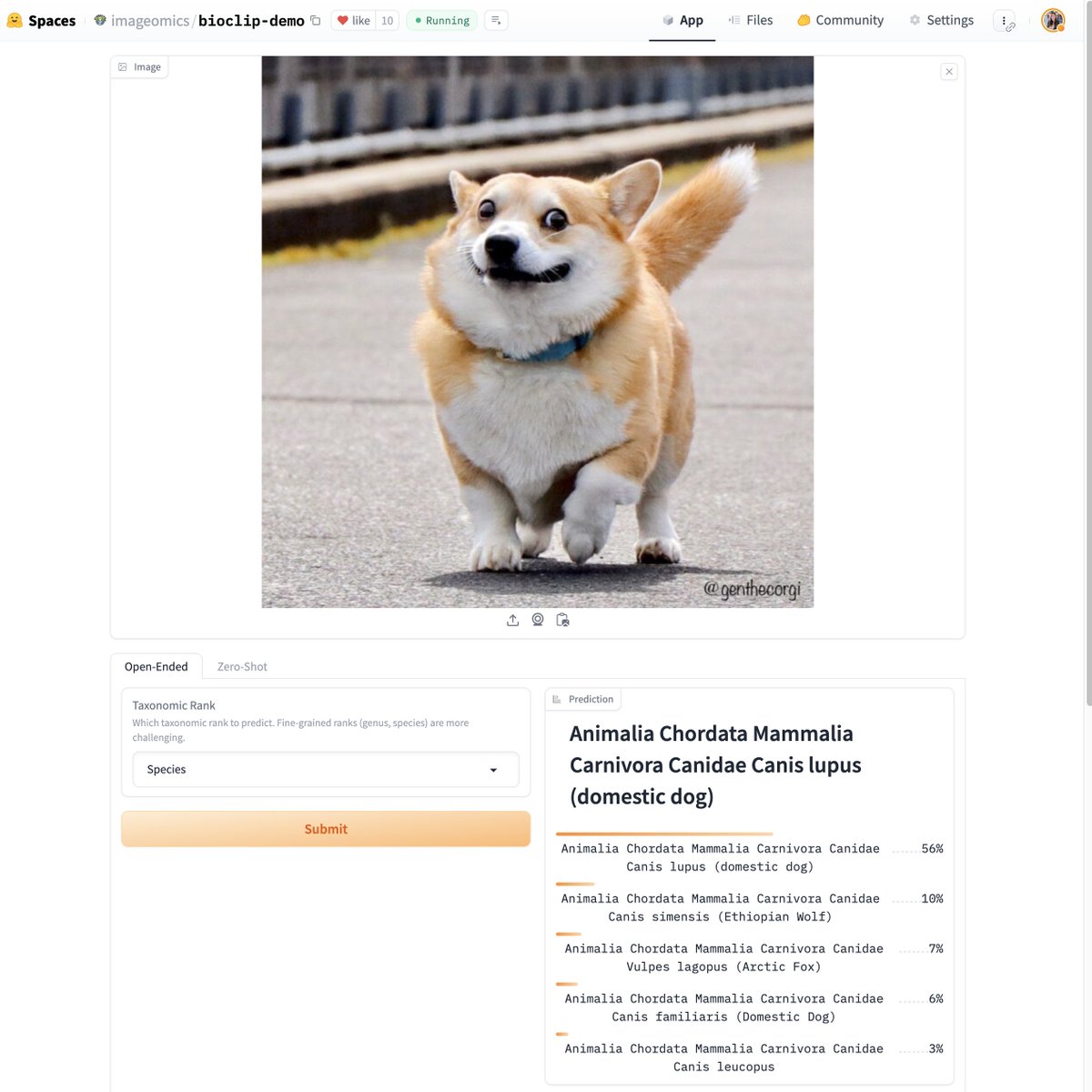
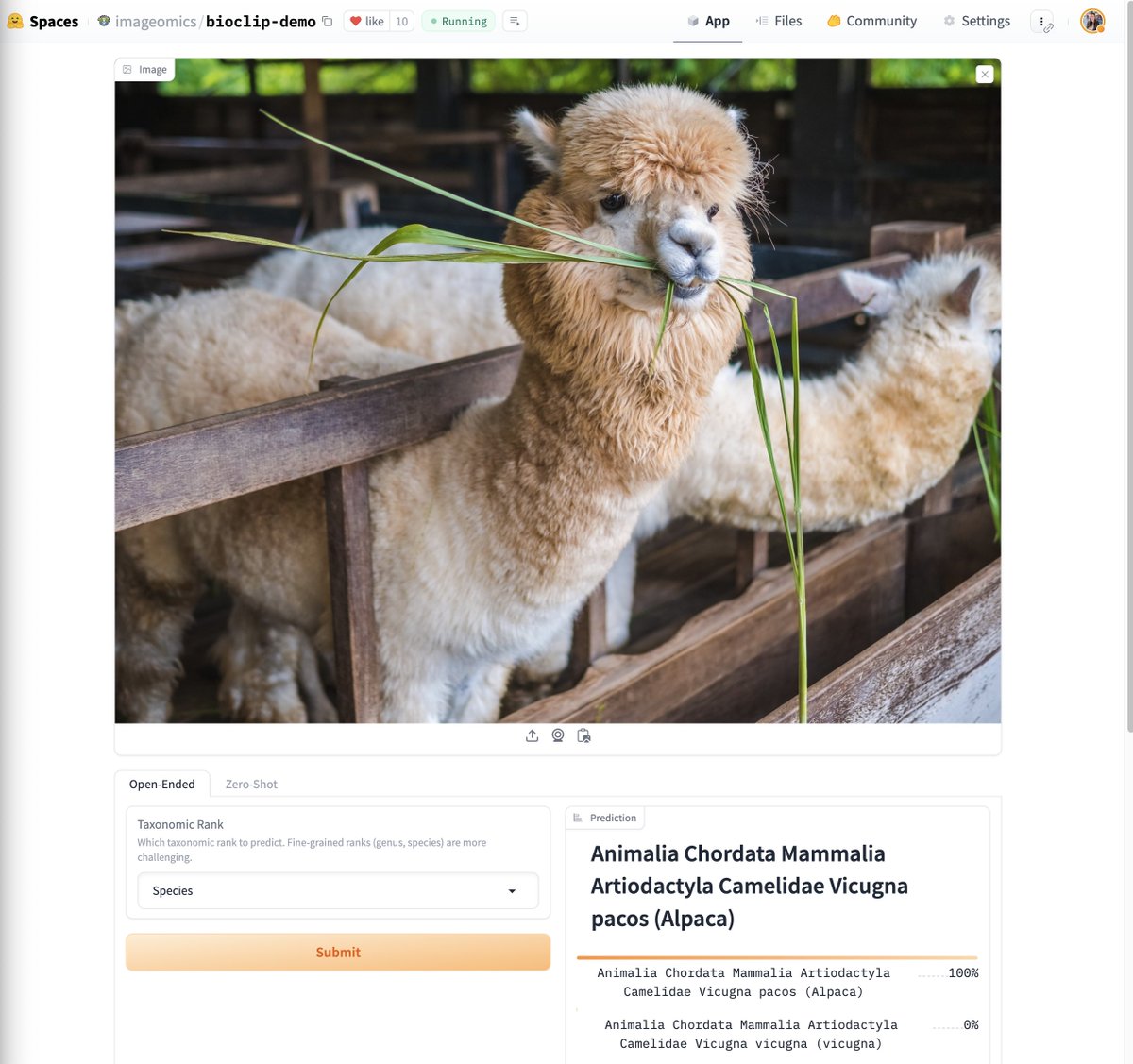
Introducing BioCLIP: A Vision Foundation Model for the Tree of Life https://t.co/39mNDUCFt2
A foundation model that strongly generalizes on the tree of life (2M+ species), outperforming OpenAI CLIP by 18% in zero-shot classification, and supports open-ended classification over almost the entire tree of life
What's the secrete ingredients?
> Data: we curate and release TreeOfLife-10M, the largest and most diverse ML-ready dataset of organism images to date. It contains 10.4M images for over 450K taxa, sourced from iNaturalist, BIOSCAN, and Encyclopedia of Life.
> Modeling: we creatively repurposes CLIP's multimodal contrastive learning objective for hierarchical image classification. The autoregressive language model naturally encodes the hierarchy of the tree of life taxonomy, which in turn bakes the hierarchical representation into the vision transformer encoder.
Key results
> Strong zero/few-shot classification for animals/plants/fungi, including rare species, outperforming CLIP by avg 16-18% absolute.
> T-sne visualization shows that BioCLIP's vision encoder has captued the fine-grained hierarchical structure of the tree of life
> BioCLIP is a kind of universal classifier for the tree of life. Just give it an organism image and it will likely find the correct species (among top 5)! But use it with caution; it's not perfect yet..
Final remarks
> AI for Science is really hard but extremely rewarding! It took us a ton of time (1+ year) and frustration trying to find a plausible way to integrate the tree of life taxonomy into foundation model training. But when the "Eureka!" moment came and the idea hit us (by the great @weilunchao) that CLIP's multimodal contrastive learning objective can be repurposed for that, everything just follows naturally. It was truly a moment of joy and excitement!
> BioCLIP is our first attempt at foundation models for biology, but it certainly won't be the last! There's so much more to do at the intersection of one of the oldest scientific disciplines and the young but thriving field of AI. Biological intelligence is the foundation for artificial intelligence, and artificial intelligence will in turn become the most important tool for us to unraval the mysteries of biological intelligence.
We are hiring postdocs and PhDs in the NSF @imageomics institute to explore this exciting field! Drop us an email. also happy to chat about it at #NeurIPS2023 with any of Tanya, @weilunchao, or me.
- paper: https://t.co/24DlLzMTJb
- project: https://t.co/39mNDUCFt2
- demo: https://t.co/YzNooBEbB3
- model: https://t.co/IM8NU6A16g
- data (TreeOfLife-10M): to be released on Hugging Face soon
joint work with the amazing @imageomics team: @samstevens6860 Lisa Wu, Matt Thompson, Elizabeth Campolongo @luke_ch_song@Carlyn2015@donglixp@dahdulw Chuck Stewart, Tanya Berger-Wolf @weilunchao@ysu_nlp
1️⃣ Share it.
2️⃣ Use it.
3️⃣ Cite it
10 of our most popular datasets in this month’s Open Data Digest, and over 50,000 more at https://t.co/gDobaoKesx
https://t.co/jYinFVd0HL
#OpenScience#DataReuse#DataScience