CPU vs GPU vs TPU vs NPU vs LPU, explained visually:
5 hardware architectures power AI today.
Each one makes a fundamentally different tradeoff between flexibility, parallelism, and memory access.
> CPU
It is built for general-purpose computing. A few powerful cores handle complex logic, branching, and system-level tasks.
It has deep cache hierarchies and off-chip main memory (DRAM). It's great for operating systems, databases, and decision-heavy code, but not that great for repetitive math like matrix multiplications.
> GPU
Instead of a few powerful cores, GPUs spread work across thousands of smaller cores that all execute the same instruction on different data.
This is why GPUs dominate AI training. The parallelism maps directly to the kind of math neural networks need.
> TPU
They go one step further with specialization.
The core compute unit is a grid of multiply-accumulate (MAC) units where data flows through in a wave pattern.
Weights enter from one side, activations from the other, and partial results propagate without going back to memory each time.
The entire execution is compiler-controlled, not hardware-scheduled. Google designed TPUs specifically for neural network workloads.
> NPU
This is an edge-optimized variant.
The architecture is built around a Neural Compute Engine packed with MAC arrays and on-chip SRAM, but instead of high-bandwidth memory (HBM), NPUs use low-power system memory.
The design goal is to run inference at single-digit watt power budgets, like smartphones, wearables, and IoT devices.
Apple Neural Engine and Intel's NPU follow this pattern.
> LPU (Language Processing Unit)
This is the newest entrant, by Groq.
The architecture removes off-chip memory from the critical path entirely. All weight storage lives in on-chip SRAM.
Execution is fully deterministic and compiler-scheduled, which means zero cache misses and zero runtime scheduling overhead.
The tradeoff is that it provides limited memory per chip, which means you need hundreds of chips linked together to serve a single large model. But the latency advantage is real.
AI compute has evolved from general-purpose flexibility (CPU) to extreme specialization (LPU). Each step trades some level of generality for efficiency.
The visual below maps the internal architecture of all five side by side.
👉 Over to you: Which of these 5 have you actually worked with or deployed on?
Inside NVIDIA GPUs: Anatomy of high-performance matmul kernels
One of the finest and in-depth posts that everyone MUST read. Amazing work by @gordic_aleksa!!
https://t.co/LMVr2mXfGQ
Quantization can make an LLM 4x smaller and 2x faster, with barely any quality loss. But what *is* it? @samwhoo crafted a beautiful interactive essay explaining it from first principles, aimed at coders, not mathematicians.
https://t.co/UfE3N1F9vw
During the Chinese New Year holiday, I built an agent-native IM where AI agents are first-class citizens: https://t.co/VMPbsTDbWY
No hand-written code. I never even reviewed a single line. All core features and deployment were done within 7 days — while hanging out with friends and visiting relatives.
Dead simple to use:
1. Connect a machine with Claude Code installed
2. Create agents with optional role descriptions
3. Chat and build
Feedback welcome!
For the next couple weeks at NY systems reading group, we’ll be writing some GPU kernels
This was much requested, and I think now that there’s some excellent, well-written content online about CuTe DSL, makes sense to learn!
(CUDA is too hard / arcane, CuTe DSL is just low-level enough to be interesting to systems folks looking for a new challenge perhaps. Plus it might be useful to learn it for work.)
I was trying to figure out how we give people a quick trial of Hopper/Blackwell GPUs and realized I already made a free product for this at my last job lol, and it’s on-demand + collaborative. So we’ll use Notebooks.
https://t.co/ArFSF8ESxA
Wrote an in depth breakdown of Paged Attention and KV cache management in modern inference systems like vLLM.
Starting from first principles:
- LLM training vs inference
- Prefill vs decoding
- Why KV caching exists
- Where memory fragmentation comes from
Then how vLLM style paged KV caching fixes it. Appendix also covers continuous batching, speculative decoding, and quantisation.
Blog: https://t.co/L97njbPDkM
There is a reason why System Design is hard for most software engineers.
They don't understand how distributed systems work.
If you want to learn the basics of distributed systems, read these 13 curated articles: ↓
(1/6) triton kernels are a great way to understand ML models. but tutorials are scattered
the learning method for me was jst to read real, high performance code
so i wrote a blog which walkthroughs the design and intuitions behind FLA's softmax attention kernel
🧵also a thread
New in-depth blog post - "Inside vLLM: Anatomy of a High-Throughput LLM Inference System". Probably the most in depth explanation of how LLM inference engines and vLLM in particular work!
Took me a while to get this level of understanding of the codebase and then to write up this one - i quickly realized i understimated the effort. 😅 It could have easily been a book/booklet (lol).
I covered:
* Basics of inference engine flow (input/output request processing, scheduling, paged attention, continuous batching)
* "Advanced" stuff: chunked prefill, prefix caching, guided decoding (grammar-constrained FSM), speculative decoding, disaggregated P/D
* Scaling up: going from smaller LMs that can be hosted on a single GPU all the way to trillion+ params (via TP/PP/SP) -> multi-GPU, multi-node setup
* Serving the model on the web: going from offline deployment to multiple API servers, load balancing, DP coordinator, multiple engines setup :)
* Measuring perf of inference systems (latency (ttft, itl, e2e, tpot), throughput) and GPU perf roofline model
Lots of examples, lots of visuals!
---
I realize i've been silent on social - many of you noticed and thanks for reaching out! :) --> I'm so back! lots of things happened.
Also, in general, I'm a bit sick of superficial content, it really is an equivalent of junk food (h/t @karpathy).
I want to do the best/deepest technical work of my life over the next years and write much more in depth (high quality organic food ;)) so I might not be as frequent around here as i used to be (? we'll see). I'll make it a goal to share a few paper summaries a week or stuff that's relevant / in the zeitgeist.
If you have any topics that happened over the past few weeks/months drop it down in the comments i might focus on some of those in my next posts.
---
Huge thank you to @Hyperstackcloud for giving me an H100 node to run some of the experiments and analysis that i needed to write this up. The team there led by Christopher Starkey is amazing!
Also a big thank you to Nick Hill (who did a very thorough review of the post - basically a code review lol; Nick's a core vLLM contributor and principal SWE at RedHat) and to my friends Kyle Krannen (NVIDIA Dynamo), @marksaroufim (PyTorch), and @ashVaswani (goat) for taking the time during weekend when they didn't have to!
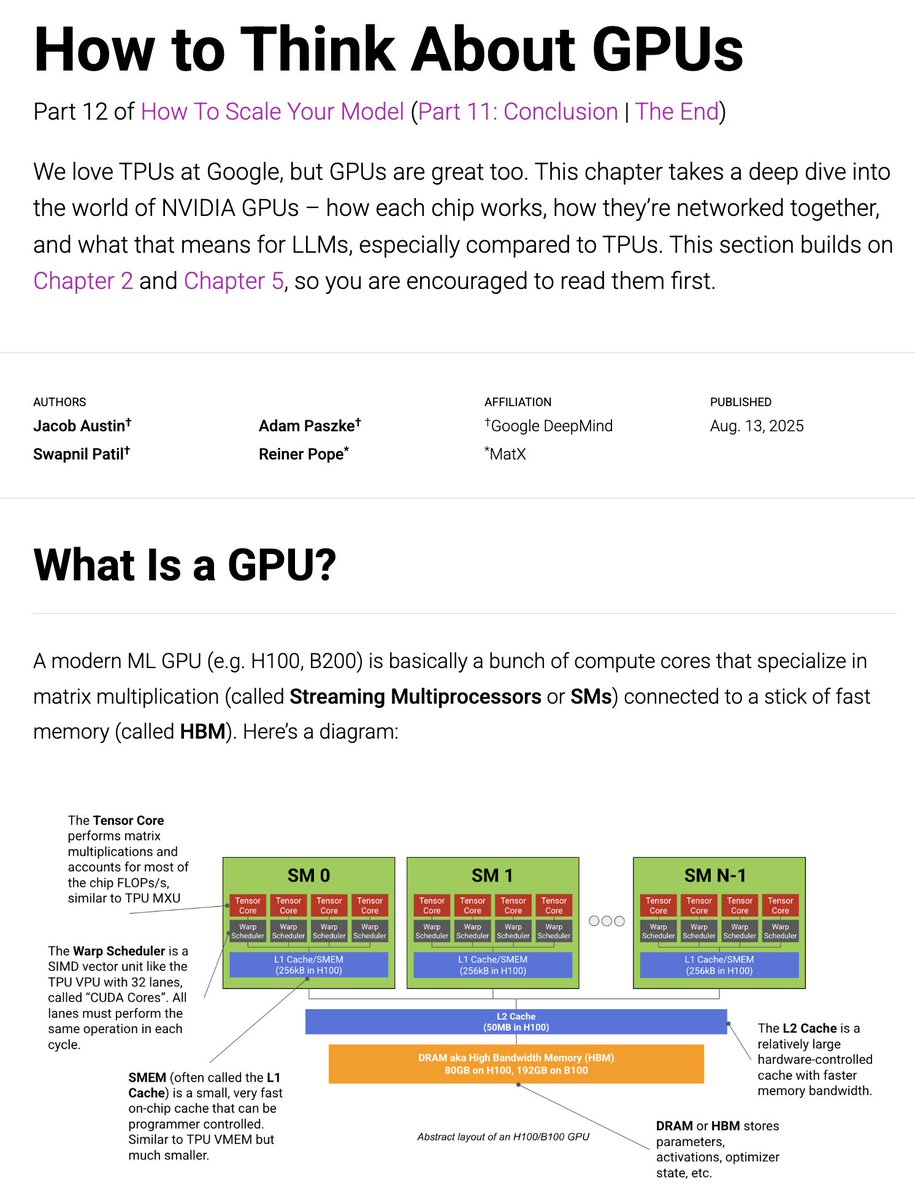
Today we're putting out an update to the JAX TPU book, this time on GPUs. How do GPUs work, especially compared to TPUs? How are they networked? And how does this affect LLM training? 1/n
Before moving from my role at Google to Snowflake I sat down and did a braindump of all the guidelines that I follow (or followed at one point and wanted to reintroduce).
For those interested, here are the ~34 guidelines that made the cut
I'm glad to have made a minor contribution to SGLang and vLLM. I also have worked on several PRs as a co-author. Thanks to my friends and community, this is a good start for me.