There will be no AI jobpocalypse.
The story that AI will lead to massive unemployment is stoking unnecessary fear. AI — like any other technology — does affect jobs, but telling overblown stories of large-scale unemployment is irresponsible and damaging. Let’s put a stop to it.
I’ve expressed skepticism about the jobpocalypse in previous posts. I’m glad to see that the popular press is now pushing back on this narrative. The image below features some recent headlines.
Software engineering is the sector most affected by AI tools, as coding agents race ahead. Yet hiring of software engineers remains strong! So while there are examples of AI taking away jobs, the trends strongly suggest the net job creation is vastly greater than the job destruction — just like earlier waves of technology. Further, despite all the exciting progress in AI, the U.S. unemployment rate remains a healthy 4.3%.
Why is the AI jobpocalypse narrative so popular? For one thing, frontier AI labs have a strong incentive to tell stories that make AI technology sound more powerful. At their most extreme, they promote science-fiction scenarios of AI “taking over” and causing human extinction. If a technology can replace many employees, surely that technology must be very valuable!
Also, a lot of SaaS software companies charge around $100-$1000 per user/year. But if an AI company can replace an employee who makes $100,000 — or make them 50% more productive — then charging even $10,000 starts to look reasonable. By anchoring not to typical SaaS prices but to salaries of employees, AI companies can charge a lot more.
Additionally, businesses have a strong incentive to talk about layoffs as if they were caused by AI. After all, talking about how they’re using AI to be far more productive with fewer staff makes them look smart. This is a better message than admitting they overhired during the pandemic when capital was abundant due to low interest rates and a massive government financial stimulus.
To be clear, I recognize that AI is causing a lot of people’s work to change. This is hard. This is stressful. (And to some, it can be fun.) I empathize with everyone affected. At the same time, this is very different from predicting a collapse of the job market.
Societies are capable of telling themselves stories for years that have little basis in reality and lead to poor society-wide decision making. For example, fears over nuclear plant safety led to under-investment in nuclear power. Fears of the “population bomb” in the 1960s led countries to implement harsh policies to reduce their populations. And worries about dietary fat led governments to promote unhealthy high-sugar diets for decades.
Now that mainstream media is openly skeptical about the jobpocalypse, I hope these stories will start to lose their teeth (much like fears of AI-driven human extinction have).
Contrary to the predictions of an AI jobpocalypse, I predict the opposite: There will be an AI jobapalooza! AI will lead to a lot more good AI engineering jobs, and I’m also optimistic about the future of the overall job market. What AI engineers do will be different from traditional software engineering, and many of these jobs will be in businesses other than traditional large employers of developers. In non-AI roles, too, the skills needed will change because of AI. That makes this a good time to encourage more people to become proficient in AI, and make sure they’re ready for the different but plentiful jobs of the future!
[Original text in The Batch newsletter.]
Inference got a hundred times cheaper this year. The compute bill went up anyway.
If you understand why those two sentences are both true at the same time, you understand the most important thing happening in AI right now.
I work on inference for a living, at @nebiustf, where we run open-source managed inference at scale. Most of what follows is what I'm seeing from inside the bill.
12 months ago, the cost of 1M tokens of frontier-class reasoning was somewhere on the order of $60.
Today, an equivalent quality of output costs roughly $0.50.
Price /token of o1-level intelligence has dropped about a 128x in a year.
Price of GPT-4-level output has dropped roughly 100x since the original GPT-4 shipped.
By any normal reading of a technology cost curve, this should be deflationary. It should be saving customers money.
The opposite has happened. The total compute bill at every hyperscaler is going up, not down. Anthropic just signed multi-year capacity deals with both XAI and Amazon. Microsoft's Azure capex guide for 2026 starts with an eight. OpenAI is reportedly spending more on compute every quarter than it did in all of 2023. Nvidia paid roughly twenty billion dollars to acquire Groq, an inference-specialist company that did not exist as a serious commercial entity three years ago.
The cost curve and the demand curve crossed, and then the demand curve lapped the cost curve.
Here is what happened underneath.
A reasoning model burns roughly 10x the output tokens of a non-reasoning model on the same task, because it spends most of its tokens thinking out loud before answering. An agentic workflow chains roughly twenty times the requests of a single-shot completion, because it loops, calls tools, plans, retries, and synthesizes. A modern deep-research query (the kind a research analyst can fire off in fifteen seconds and then walk away from for ten minutes) costs more compute than 10 original GPT-4 queries combined. We made every individual token a hundred times cheaper, and then we built a generation of products that consume ten thousand times more tokens.
This is the Jevons paradox playing out at trillion-dollar scale, in compressed time, in front of everyone. Jevons noticed in 1865 that making coal-burning more efficient did not reduce coal consumption. It increased it, because efficiency unlocked uses that were previously uneconomic. Steam engines became more practical at smaller scales. Whole industries that could not afford coal at the old price suddenly could. Britain's coal consumption rose sharply, not despite the efficiency gains, but because of them.
The same thing is happening to AI compute right now and it is happening faster than any analogous historical cycle. Falling token prices did not contract demand. They unlocked agents, deep research, code-writing systems, multi-step reasoning, persistent memory, the entire next layer of AI products. Every product in that next layer consumes orders of magnitude more compute than the chat interfaces it is replacing.
The math at the aggregate level is brutal: 100x cheaper tokens times 10 000 more tokens equals a 100x larger total bill.
The implications stack quickly.
If you are running a hyperscaler, your 2026 capex guide is not a peak. It is a step on a curve. Inference is structurally always-on, twenty-four hours a day, in a way that training never was. Training is bursty. You spin up a cluster, run for weeks or months, and stop. Inference runs continuously, scales with usage, and the usage curve is exponential. Your power bill, your cooling bill, your transceiver count, your storage footprint, all of these were sized for a workload mix that no longer exists.
If you are running an AI software company built on top of someone else's closed API, you have a problem that did not exist a year ago. Your gross margins get worse as your customers get more value out of your product, because the more they use it, the more compute you pay for. The companies that win this are the ones that figured out vertical integration before the math caught them.
If you are watching this from a distance and trying to understand where the next bottlenecks form, the answer is everywhere downstream of "more inference compute, always-on, with massive memory state per session." The KV cache, the running memory state of a long conversation or an agent loop, is the silent monster of the inference era. It does not scale linearly with parameters. It scales linearly with context length and number of agent steps. A long agent session can hold tens of gigabytes of state per user, per session.
Multiply that by every concurrent user of every product, and you understand why $MU, $SNDK, $TOWCF, and the entire memory and packaging layer have re-rated the way they have.
The CPU-to-GPU ratio is evolving. Training is 1:8. Basic chat inference is 1:4. Agentic inference is 1:1, sometimes CPU-heavy. Google has split its TPU line in two, with a dedicated inference chip carrying tripled SRAM for KV cache. $INTC and $AMD just spent two earnings calls explaining that this shift is structural, not cyclical. The hardware map is redrawing in real time and the financial press is mostly still writing about training clusters.
The right framing of where we are right now is not that AI is hitting a wall. The framing a year ago that scaling was hitting a wall was the most expensive bad take of the cycle. The right framing is that AI got dramatically cheaper, dramatically more capable, and dramatically more useful, and the cost of running it at the new equilibrium of demand is much higher than the cost at the old equilibrium of demand, because the new equilibrium is enormous.
A meaningful share of what we actually do at Token Factory, day to day, is help customers stop their bills from running away from them. KV-cache management. Speculative decoding. Quantization. Routing. The kind of vertical integration that, eighteen months ago, every product team was happy to leave abstracted away behind a closed API. The reason this stack matters now is the same reason this whole essay matters: at the new equilibrium of inference demand, the cost of treating compute as a commodity is no longer survivable. The companies that figure out the layer beneath the API are the ones who keep their margins.
Cheaper tokens. More tokens.
Same coal as 1865.
Hungary has chosen Europe.
Europe has always chosen Hungary.
A country reclaims its European path.
The Union grows stronger.
Magyarország Európát választotta.
Európa mindig Magyarországot választotta.
Egy ország visszatér az európai útjára.
Az Unió erősebbé válik.
“Lisbon's a fantastic city, absolutely stunning city, one of the top. So there are 4 great cities, as you know, in Europe…Lisbon, Vienna, Stockholm and Wolverhampton.”
–@dcsandbrook
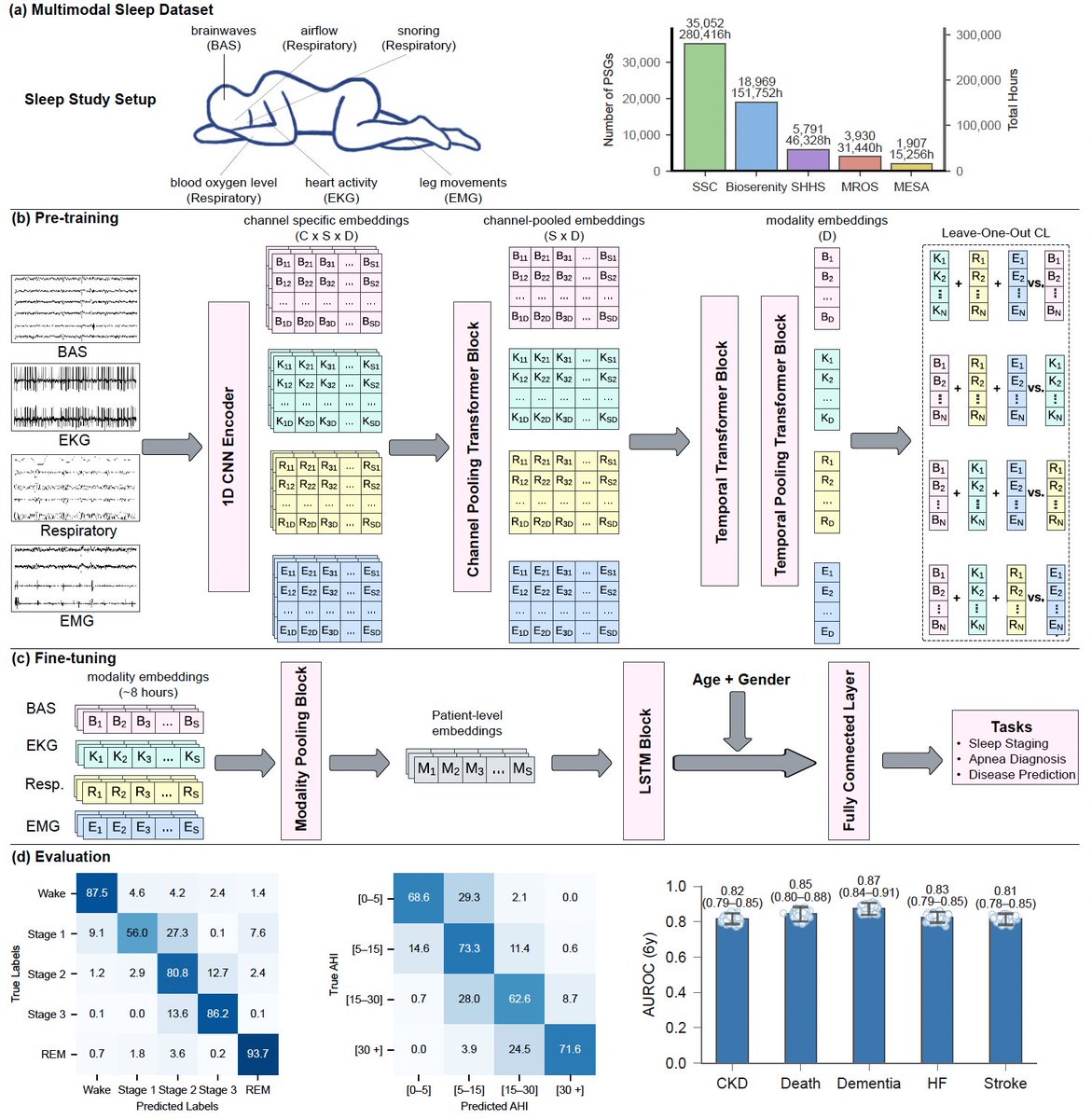
Today in @NatureMedicine we report that AI can predict 130 diseases from 1 night of sleep🛌
We trained a foundation model (#SleepFM) on 585K hours of sleep recordings from 65K people—brain, heart, muscle & breathing signals combined.
AI learns the language of sleep🧵
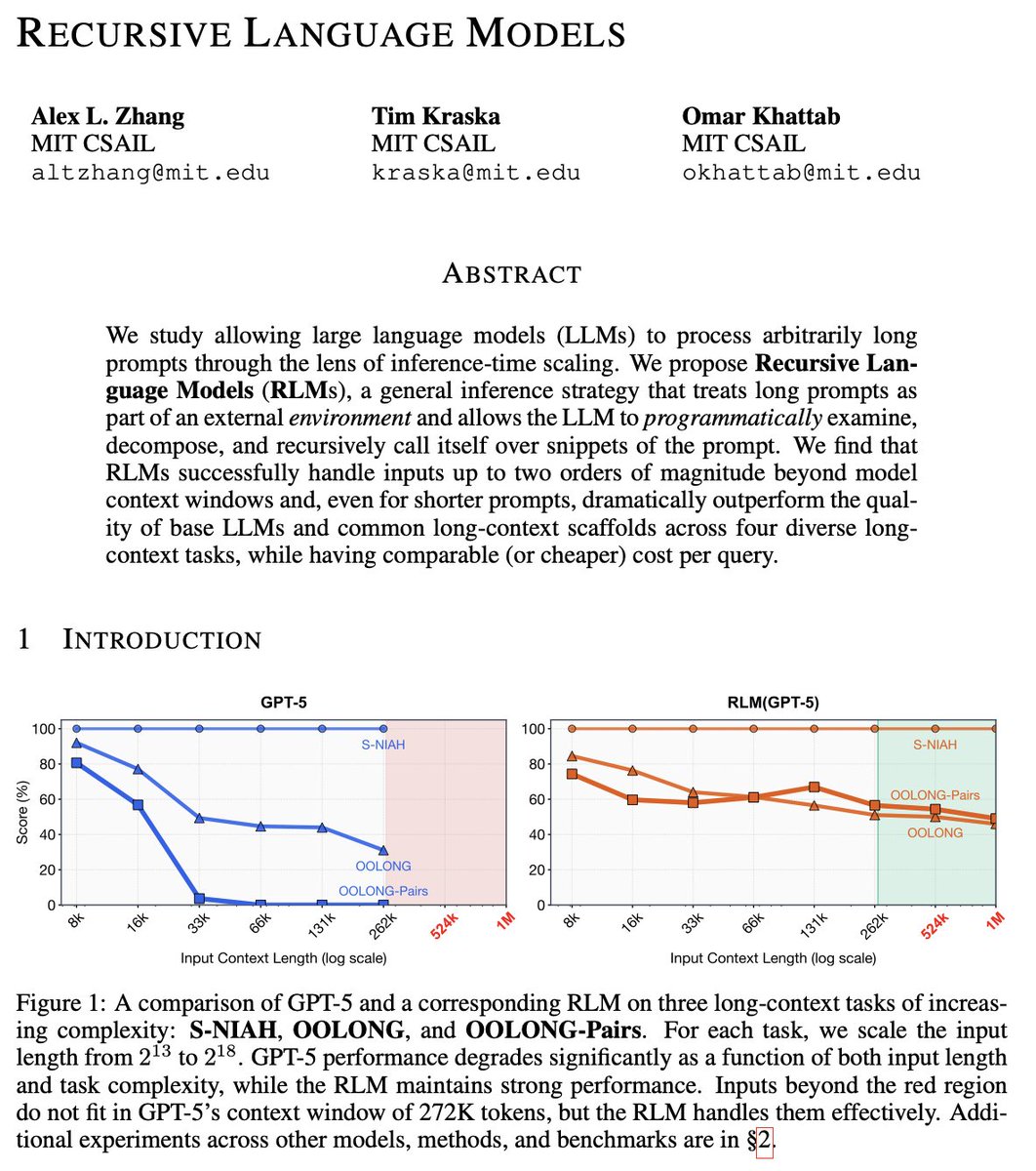
Much like the switch in 2025 from language models to reasoning models, we think 2026 will be all about the switch to Recursive Language Models (RLMs).
It turns out that models can be far more powerful if you allow them to treat *their own prompts* as an object in an external environment, which they understand and manipulate by writing code that invokes LLMs!
Our full paper on RLMs is now available—with much more expansive experiments compared to our initial blogpost from October 2025!
https://t.co/x47pIfIkTb
🇫🇷 Another tragic evening in Lyon, France - holding on by a thread:
A society buckling under the unbearable weight of free healthcare, paid parental leave, nine weeks of vacation, reliable public transport, and the extremist idea that citizens shouldn’t live in constant fear of the state.
Meanwhile elsewhere, real strength prevails. People enjoy the comforting simplicity of knowing exactly what they’re allowed to say, think, and post. Journalists experience the adrenaline rush of legal ambiguity. Critics win surprise travel packages to distant regions. Elections are streamlined, decisive, and emotionally undemanding.
Back in Lyon, residents continue to suffer through tedious stability, supermarkets fully stocked, and the psychological toll of choosing between twenty kinds of bread, hundreds of different cheese and an unreasonable number of wines. No loyalty oaths. No compulsory patriotism. No nightly reminder that civilization is about to collapse any minute now.
Experts warn that if this recklessness continues, Europeans may begin to believe that life can be predictable, safe, and quietly pleasant - without fear.
A deeply dangerous precedent for strongman economies everywhere.
To perfectly understand a phenomenon is to perfectly compress it, to have a model of it that cannot be made any simpler.
If a DL model requires millions parameters to model something that can be described by a differential equation of three terms, it has not really understood it, it has merely cached the data.
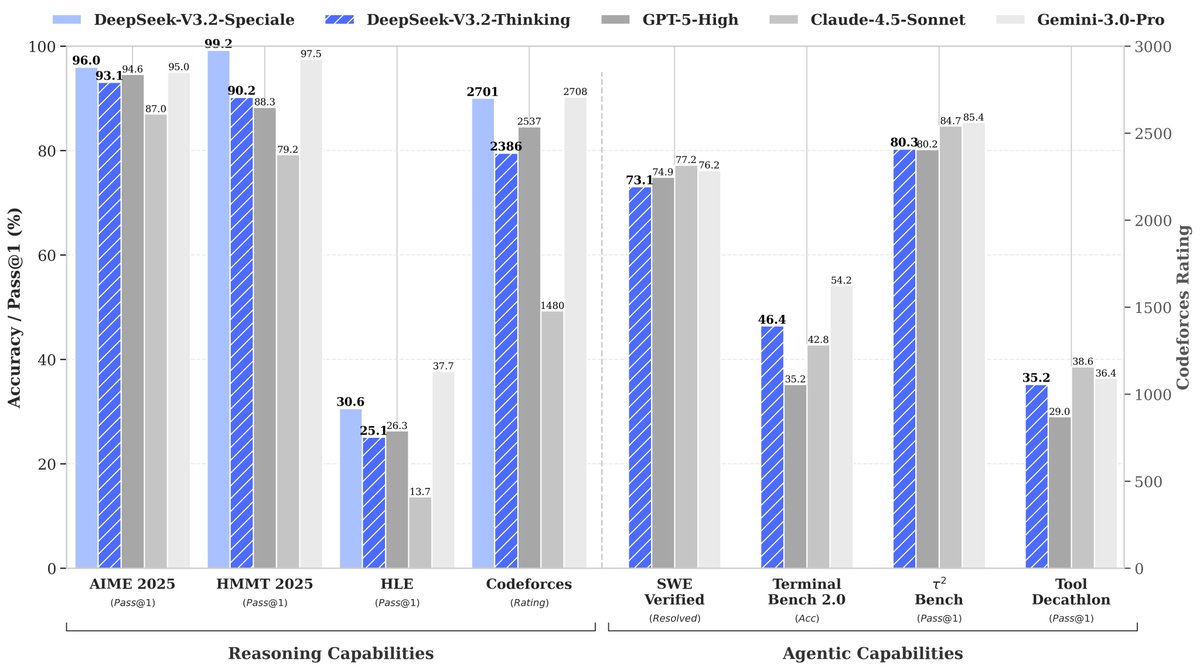
If Gemini-3 proved continual scaling pretraining, DeepSeek-V3.2-Speciale proves scaling RL with large context.
We spent a year pushing DeepSeek-V3 to its limits. The lesson is post-training bottlenecks are solved by refining methods and data, not just waiting for a better base.
🚀 Launching DeepSeek-V3.2 & DeepSeek-V3.2-Speciale — Reasoning-first models built for agents!
🔹 DeepSeek-V3.2: Official successor to V3.2-Exp. Now live on App, Web & API.
🔹 DeepSeek-V3.2-Speciale: Pushing the boundaries of reasoning capabilities. API-only for now.
📄 Tech report: https://t.co/7EyydyNuG0
1/n
I cannot help but feel happy to see how we at @feedzai#Research are innovating on some of these explanations for our use of fraud detection. But that's a story for another day!
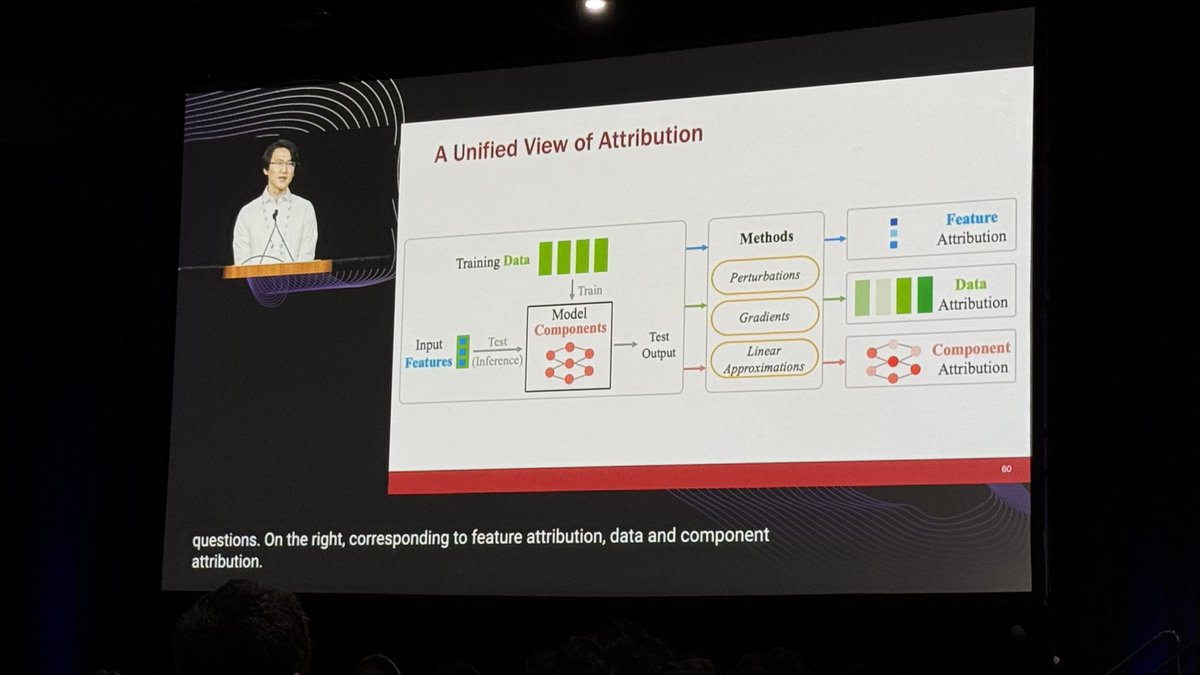
A unified view of different post-hoc explanations is presented, covering: feature ("how do these input features influence the outputs?"), data ("how does the training data influence the outputs?") and component attributions ("how do the model components influence the outputs?").































![AndrewYNg's tweet photo. There will be no AI jobpocalypse.
The story that AI will lead to massive unemployment is stoking unnecessary fear. AI — like any other technology — does affect jobs, but telling overblown stories of large-scale unemployment is irresponsible and damaging. Let’s put a stop to it.
I’ve expressed skepticism about the jobpocalypse in previous posts. I’m glad to see that the popular press is now pushing back on this narrative. The image below features some recent headlines.
Software engineering is the sector most affected by AI tools, as coding agents race ahead. Yet hiring of software engineers remains strong! So while there are examples of AI taking away jobs, the trends strongly suggest the net job creation is vastly greater than the job destruction — just like earlier waves of technology. Further, despite all the exciting progress in AI, the U.S. unemployment rate remains a healthy 4.3%.
Why is the AI jobpocalypse narrative so popular? For one thing, frontier AI labs have a strong incentive to tell stories that make AI technology sound more powerful. At their most extreme, they promote science-fiction scenarios of AI “taking over” and causing human extinction. If a technology can replace many employees, surely that technology must be very valuable!
Also, a lot of SaaS software companies charge around $100-$1000 per user/year. But if an AI company can replace an employee who makes $100,000 — or make them 50% more productive — then charging even $10,000 starts to look reasonable. By anchoring not to typical SaaS prices but to salaries of employees, AI companies can charge a lot more.
Additionally, businesses have a strong incentive to talk about layoffs as if they were caused by AI. After all, talking about how they’re using AI to be far more productive with fewer staff makes them look smart. This is a better message than admitting they overhired during the pandemic when capital was abundant due to low interest rates and a massive government financial stimulus.
To be clear, I recognize that AI is causing a lot of people’s work to change. This is hard. This is stressful. (And to some, it can be fun.) I empathize with everyone affected. At the same time, this is very different from predicting a collapse of the job market.
Societies are capable of telling themselves stories for years that have little basis in reality and lead to poor society-wide decision making. For example, fears over nuclear plant safety led to under-investment in nuclear power. Fears of the “population bomb” in the 1960s led countries to implement harsh policies to reduce their populations. And worries about dietary fat led governments to promote unhealthy high-sugar diets for decades.
Now that mainstream media is openly skeptical about the jobpocalypse, I hope these stories will start to lose their teeth (much like fears of AI-driven human extinction have).
Contrary to the predictions of an AI jobpocalypse, I predict the opposite: There will be an AI jobapalooza! AI will lead to a lot more good AI engineering jobs, and I’m also optimistic about the future of the overall job market. What AI engineers do will be different from traditional software engineering, and many of these jobs will be in businesses other than traditional large employers of developers. In non-AI roles, too, the skills needed will change because of AI. That makes this a good time to encourage more people to become proficient in AI, and make sure they’re ready for the different but plentiful jobs of the future!
[Original text in The Batch newsletter.]](https://pbs.twimg.com/media/HIIb1VGaUAAZoAB.jpg)