⚡️ Step 3.7 Flash is here: The new frontier is agent efficiency.
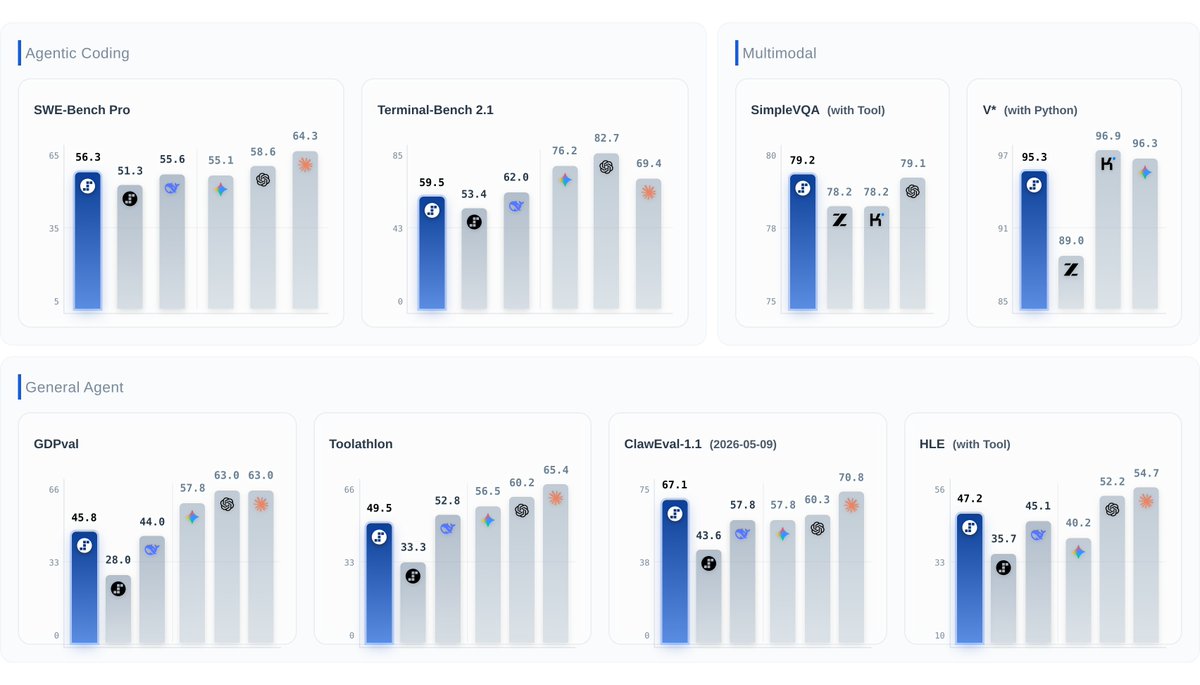
#1 ClawEval-1.1 (67.1), #1 SimpleVQA Search (79.2), #2 SWE-PRO (56.3), 95.3 on V* Python. Open weights under Apache 2.0.
Built for agentic, coding, search, and multimodal workflows — balancing speed, cost, and reliable execution.
- 400 TPS. 198B sparse MoE, ~11B active. 256K context, 3 reasoning levels.
- Understands UIs, charts, docs, images — then writes code or calls tools to act on what it sees.
- Web + visual search reaches further: more sources, deeper follow-up.
- Reliable tool use — less drift, fewer broken toolcalls. 98%+ on τ²-bench across all difficulty levels.
- Works with Claude Code, KiloCode, Hermes Agent, OpenClaw, and protocols like MCP.
- Runs locally on Mac Studio M4 Max, DGX Spark, AMD AI Max+ 395.
GitHub: https://t.co/kqlZkVIRHv
HuggingFace: https://t.co/qqceCrgPiw
GGUF: https://t.co/rR6XrnymWG
ModelScope: https://t.co/wney6Tzvqy
API: https://t.co/RvHWzRG7Fu
Blog: https://t.co/BxDiajiQ5G
StepAudio 2.5 TTS is live now!
Control emotion, pacing, pauses, and delivery with plain natural language. No tags, no preset combos. Just describe what you want the voice to do. Zero-shot voice cloning with full timbre + emotion control.
Available via Pay-as-you-go API or Step Plan.
"can we get the base model?"
sure. here's two.
"can we get the code?"
sure. here's SteptronOSS.
"what about the SFT data?"
coming soon.
maximum sincerity, minimum barriers.
- Step 3.5 Flash Base — pretrained foundation
- Step 3.5 Flash Base-Midtrain — code, agents & long-context
- SteptronOSS — open-sourced, ready for your custom workflows
- SFT Data — coming soon for reference
not just the final checkpoint — a customizable pipeline.
🤗 https://t.co/pVaFiJ87UT
🤗 https://t.co/YDOZUcqgXh
💻 https://t.co/G42LCHmQMr
7. ViStoryBench: Comprehensive Benchmark Suite for Story Visualization
🔑 Keywords: story visualization, generative models, evaluation benchmark, ViStoryBench, character consistency
💡 Category: Generative Models
🌟 Research Objective: The paper aims to improve the performance of story visualization frameworks by proposing a novel evaluation benchmark that assesses models across diverse story types and artistic styles.
🛠️ Research Methods: The study introduces ViStoryBench, which features a carefully curated dataset that evaluates models on various narrative structures, visual aesthetics, and different plot types, ensuring comprehensive comparisons through a wide range of evaluation metrics.
💬 Research Conclusions: The framework allows researchers to identify the strengths and weaknesses of different models, particularly in maintaining character consistency, handling complex plots, and generating accurate visuals, thus fostering targeted improvements in the field of story visualization.
👉 Paper link: https://t.co/Zwh4edvsh7
We now added GLM-5 to our leaderboard! It's the second-best open model on MathArena, but it does significantly underperform compared to other models on ArXivMath, especially given its great competition-problem performance.
🚀What Benchmark Design Tells Us About the Result of Step 3.5 Flash?
Here's a detailed breakdown from model infra engineer & Zhihu contributor P2oileen, who worked directly on the benchmarking infrastructure.
💬"If high scores can't be reproduced, a tech report is just paper."
Since June last year, he's been working on model evaluation at @StepFun_ai, focusing on one core goal:
making training metrics reliable, reproducible, and trustworthy.
And Step 3.5 Flash(196B MoE, A11B) did deliver with good results on different benchmarks.
🧱 Benchmarking at Scale: Lessons from the Infrastructure
Our evaluation platform now integrates 300+ internal and external benchmarks. Making these scores "real" required fixing a lot of invisible problems:
1️⃣ Failure-aware evaluation
API timeouts, service instability, sandbox crashes—these happen constantly at scale.
Instead of silently assigning low scores, we now:
• Capture failures across model calls, judgers, tokenizers, and sandboxes
• Explicitly report failure rates and causes in the UI
2️⃣ Train–Inference consistency
We moved from "convert weights → deploy → test" to in-training evaluation with guarded inference services, eliminating misalignment between training and evaluation.
3️⃣ Managing 300+ benchmarks without chaos
Early on, one maintainer + manual reviews = daily firefighting. Now we have:
• Standardized onboarding & release processes
• Clear ownership for every benchmark
• AI-powered reviewers
• Experiment with Agents auto-integrating benchmarks
🔍 Making Scores Credible
To ensure metrics actually mean something:
• Reproduce competitor results internally to verify alignment
• Check for data contamination by deduplicating evaluation sets
• Reduce false negatives via:
- Prompt engineering (e.g. \boxed{} answer formats)
- Upgraded LLM-based judgers
- Fixing brittle answer extractors
• Statistical testing for small datasets (mean + variance)
• Pretrain-specific strategies: output truncation, stop tokens, few-shot pattern stabilization
• Prompt alignment is critical. They open-source all System + Question Prompts in the appendix — reproducibility matters more than prompt tricks.
🧠 Reasoning-Heavy & Long-Context Tasks
Step 3.5 Flash produces long, reasoning-dense outputs. We added:
• Token-level reasoning length monitoring
• Streamed inference optimizations (socket buffers, keep-alive strategies)
These infra-level details are unglamorous—but they're what make high scores on AIME, IMO, FRAMES actually possible.
📌 Final Takeaway
After 8 months of large-model evaluation, one lesson stands out:
✨Evaluation shouldn't just "follow" training—it should slightly lead it.
For Step 3.5 Flash, strong results came from carefully chosen benchmarks and well-designed evaluation protocols.
Our next goal is to formalize this intuition into scalable quality checks—so evaluation certainty can offset training uncertainty.
We hope this experience is useful to the community—and that it helps power Step 4 and beyond 🚀
Feel free to try Step 3.5 Flash, and happy to discuss benchmarking with fellow practitioners.
📖 Read more: https://t.co/EDn3hPGKFd
🔗 Full evaluation protocols:
https://t.co/vJKWwbSY8Q
#Step35Flash #OpenSource #AI #LLM #MoE #Reasoning #Agent #AIInfra
StepFun Step 3.5-Flash Tech Report is here! And it's great!
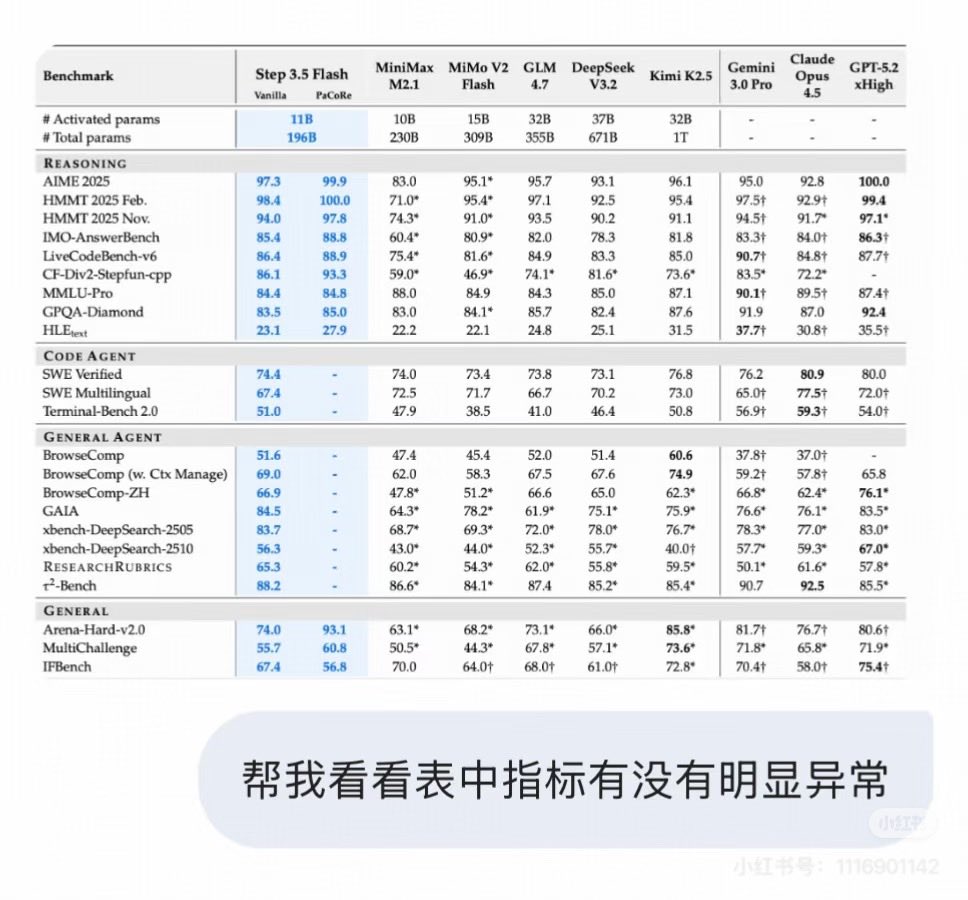
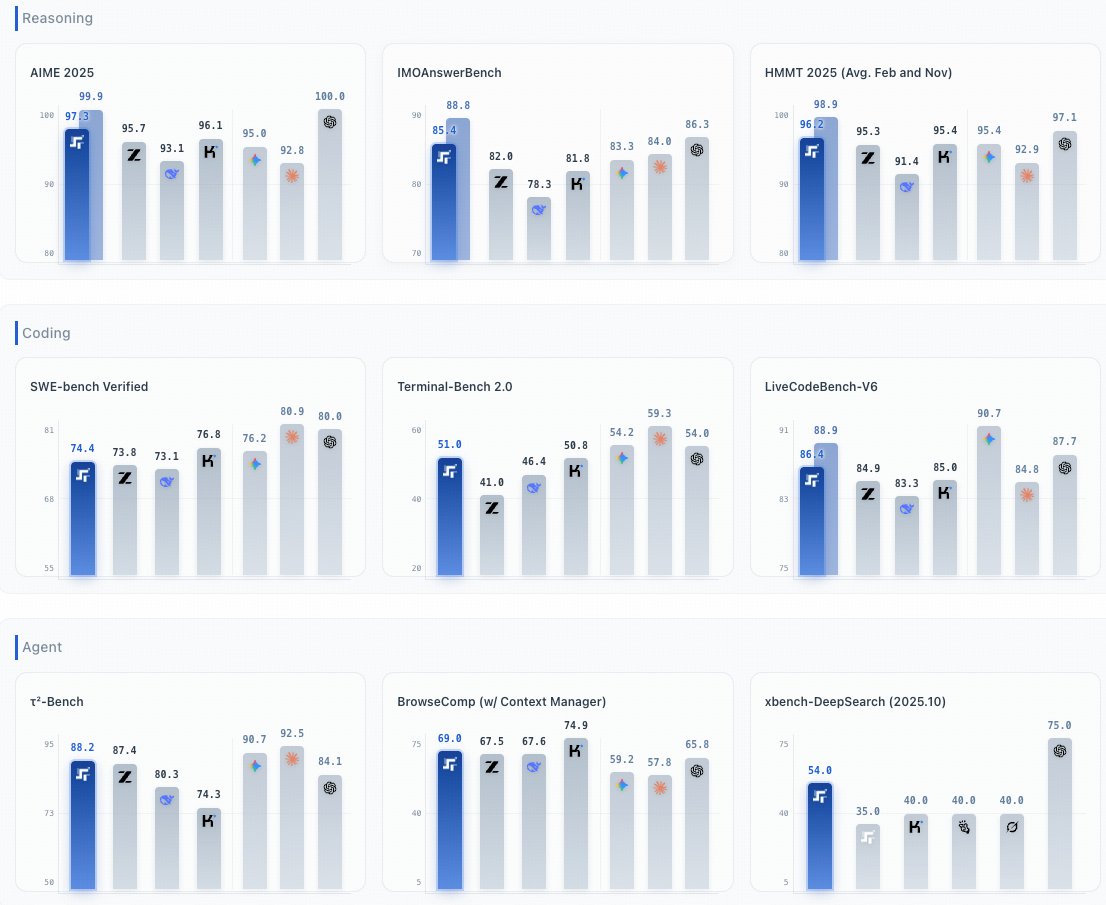
– they compare against absolute frontier (Gemini Pro/Opus/5.2-xhigh), primarily in agency. 74.4 SWE-Bench etc.
– 4,096 H800s, 17.2T tokens, Muon (fancy again)
- PaCoRe is their "Heavy" mode
- lots of details on training
Stepfun open-sourced Step-3.5-Flash, a powerhouse model specifically architected for high-speed reasoning and complex Agentic workflows. 🚀
Model: https://t.co/0Z6oFwJ9kI
Key Technical Specs:
✅ Sparse MoE Architecture: 196B total params, but only ~11B active per token. SOTA efficiency.
✅ MTP-3 (Multi-Token Prediction): It predicts 3 tokens at once, hitting a blistering 350 TPS for code-heavy tasks. ⚡
✅ Hybrid Attention (SWA + Full): A 3:1 mix that masters 256K context windows while keeping compute costs low.
✅ Parallel Thinking: Massively boosted performance for multi-step reasoning and deep search.
Why Devs should care:
- Built for Agents: Excels at long-chain task decomposition and cloud-edge collaboration.
- Local-First Optimization: Runs smoothly on NVIDIA DGX Spark, Apple M3/M4 Max, and AMD AI Max+ 395. 💻
Benchmarks show it rivals top-tier closed-source models in math and coding scenarios, making it the perfect "copilot" for autonomous systems.
Fast enough to think. Reliable enough to act.
Step-3.5-Flash is here @StepFun_ai⚡
Website: https://t.co/tQRWfXOBwW
Blog: https://t.co/Ezb8uUvQCY
Powering the next wave of intelligence—from real-time reasoning to reliable agentic action.
We are so back. 🚀
Website:
https://t.co/tQRWfXOBwW
Blog:
https://t.co/Ezb8uUvQCY
Github:
https://t.co/2zI8JtmI43
Huggingface:
mtp3_bf16: https://t.co/odrPo9rKTc
API Platform:
https://t.co/JFZUYRQ4Jt
Openrouter:
https://t.co/e9Q67oEvyv
Discord:
https://t.co/oLpLYAJd2i