🚨 OPEN SOURCE AI IS LITERALLY UNSTOPPABLE 🚨
The legendary founder of Redis (Antirez) just dropped ds4 - a custom native inference engine built specifically for DeepSeek v4 Flash
This is earth shattering! Here is why:
DeepSeek v4 Flash is a quasi-frontier model with a massive 1M context window
You can now run it LOCALLY on a 128GB Mac using specialized 2-bit quantization
The architecture is reimagined—he moved the KV cache from RAM directly to the SSD disk! 🤯
We already know DeepSeek v4 Flash is insanely good for agentic loops - Now you don't even need the cloud to run it
Closed-source labs are burning tens of billions on massive GPU clusters while single brilliant developers are running frontier-level AI on laptops!
They told us open-source would be worthless against trillion-dollar monopolies
Instead, pure hacker culture + incredible open-weight models are completely rewriting the rules
Open Source will ALWAYS win 💕
ANTHROPIC JUST RELEASED THE OFFICIAL PLAYBOOK FOR BUILDING A COMPANY WITH CLAUDE CODE.
30 minutes. free. from the engineers who built it.
Bookmark this before you forget.
CEO: 1 human. Employees: AI agents. Operations: fully automatic.
The zero-headcount company is no longer a joke.
🚨 Karpathy was right. He warned that 90% of AI advice dies in 6 months.
spoiler: most tools will not even survive 90 days.
this guy is literally giving away the exact 2026 playbook for AI Agents.
he covers what to learn, what to build, and what to skip 👀
↓ read this today
THIS 2-HOUR STANFORD LECTURE WILL SHOW YOU HOW CLAUDE OPUS 4.7 ACTUALLY WORKS
> pretraining. SFT. RLHF. tokenization. evaluation
the same pipeline that powers Claude - explained from first principles by the people who research it
save this. watch it once 👇
🚨 Anthropic's own team just showed how to actually prompt Claude.
24 minutes. free. from the people who built it.
watch the workshop. bookmark it.
worth more than every $300 course you almost bought.
you've been using Claude without knowing 40 of its prompts.
Then read the guide below.
THE 1-HOUR OBSIDIAN LECTURE THAT CHANGES HOW YOU THINK ABOUT YOUR VAULT
> Nick Milo breaks down Obsidian Bases
> the feature that finally makes Obsidian a real database, not just a folder of markdown files
> save this. watch it before you set up your vault👇
The clearest explanation of Claude Managed Agents you'll find.
Everyone's talking about it. Nobody's explaining it well.
In 12 minutes we cover:
- What it actually is (platform as a service for AI agents)
- Who it's for and who should avoid it (4 personas)
- Live console walkthrough (sessions, analytics, costs)
- Real cost breakdown ($2.58 to fulfill a $1,000 service)
We also built a free Google Doc that deploys your first managed agent when you hand it to Claude Code.
You can grab it in the podcast show notes (Build With AI podcast) or YouTube description (video link below).
This 16-minute talk by two Anthropic engineers who built Claude Skills will teach
you more about building them right than most developers figure out on their own in months.
Bookmark this & watch, no matter what.
Then read the guide below by @eng_khairallah1
Every time I open X these days, it’s just Karpathy’s LLM Knowledge Base wiki dominating the timeline.
Close the app, reopen… still there.
At this point I’m half-tempted to file a FOIA request titled “Anthropic Payroll Shenanigans”.
Meanwhile in Anthropic Slack, 3:42pm:
PM: Andrej… token usage looking a little quiet this quarter
Karpathy: Say less.
Drops a 127k-word personal knowledge base that single-handedly melts every builder’s context window and resets the entire TL.
New quarterly Karpathy arc just dropped — courtesy of Anthropic’s token throughput department.
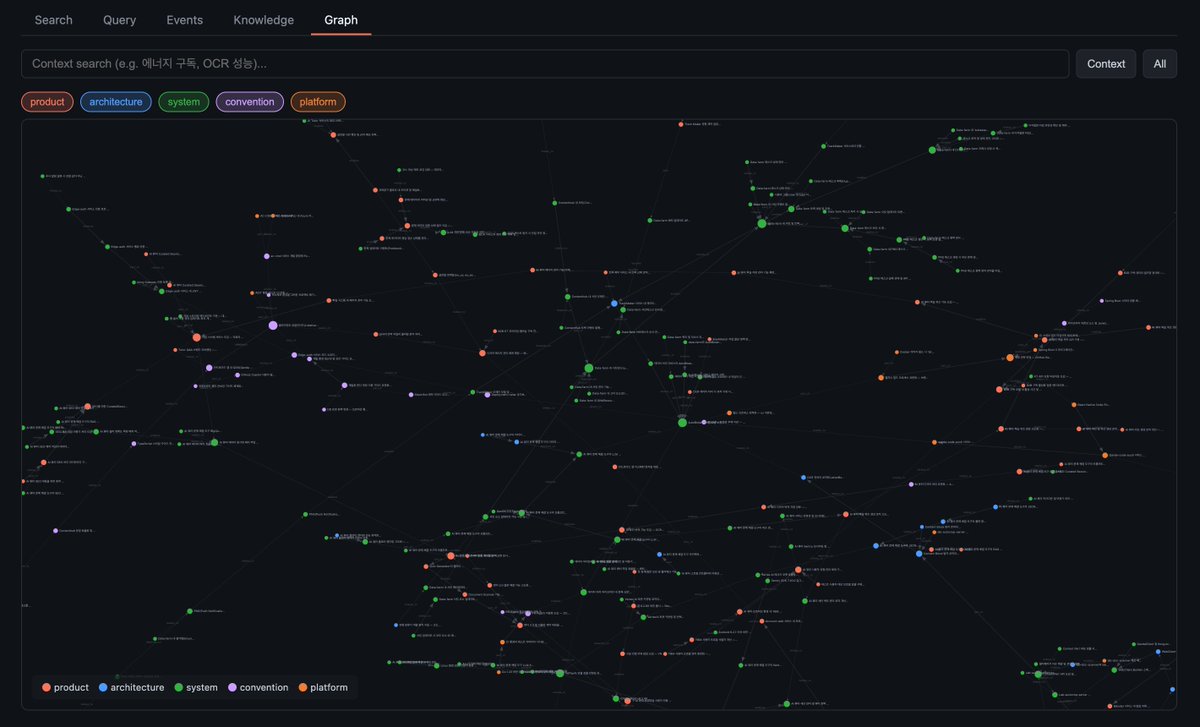
(meanwhile my org knowledge graph is quietly compiling itself in the background like a good little agent…)
Update on the org knowledge graph I posted about earlier —
Switched from the Neo4j graph approach to an LLM Wiki pattern (inspired by @karpathy). The difference is fundamental: instead of extracting isolated fact-nodes into a graph DB, the LLM now incrementally maintains wiki pages — reading, updating, cross-referencing, noting contradictions. Knowledge compounds instead of fragmenting.
The bigger shift: moved the whole thing onto Claude Code's remote scheduler. My Max plan runs a scheduled agent that crawls one 7-day window per run, starting from company founding.
The part I'm most excited about — the system evolves itself through three files:
**PROMPT.md** — The agent's instruction set. But here's the thing: the agent can rewrite it. If it discovers that a proxy endpoint needs different parameters, or that a directory convention should change, it updates its own instructions. Long-term behavioral evolution.
**handoffs/*.md** — One file per completed run. Each handoff teaches the next run: "Slack workspace was created Dec 27, so don't bother searching before that." "PR bodies are empty before 2020, rely on titles." "KANBAN format is MPKAN-####." The agent discovered all of this on its own and recorded it. Short-term accumulated memory.
**REPORT_LOG.md** — The only file meant for me. A human-readable log of what each run did, what it found interesting, and what needs my attention.
The loop:
1. Agent reads HANDOFF.md (learn from predecessors)
2. Collects from Slack/GitHub/Notion via proxy API
3. Updates wiki pages (knowledge/)
4. Writes new handoff (teach successor)
5. Optionally rewrites PROMPT.md (evolve behavior)
6. Commits → GitHub Action re-triggers → next window
After a few runs from the company founding, it built 100 wiki pages covering core services, products, infra, and team processes — all autonomously. Each run gets smarter than the last because it reads what previous runs learned.
~380 weeks to process until present. The system will literally teach itself the entire company history, one week at a time, getting better at it as it goes.
I get the business rationale, but where exactly is the line? Agent SDK? CLI runtimes? Local dev? Please just publish clear guidelines before rolling out policy changes.
Starting tomorrow at 12pm PT, Claude subscriptions will no longer cover usage on third-party tools like OpenClaw.
You can still use these tools with your Claude login via extra usage bundles (now available at a discount), or with a Claude API key.
Inspired by @karpathy's LM Knowledge Bases — I'm building something similar, but for an entire company.
Taking 10 years of organizational context at our company and compiling it into a shared knowledge graph that plugs into our existing AI workflows.
Pipeline: GitHub + Notion + Slack + ... (N channels) → raw event store → LLM extraction → Neo4j graph DB
The extraction LLM (gemini-3-flash-lite) isn't the smartest, but it's cheap — so inspired by @karpathy's auto-research approach, I run auto prompt-enhancing iterations: reset → promote → evaluate → tweak prompt → repeat until the graph quality is satisfactory.
From zero to working system: 1hr connecting data sources, 1hr infra + code, then karpathy iteration.
The loop: Integrated into our existing workflows via MCP. Every communication channel feeds the graph, and the graph feeds back into every workflow. Knowledge compounds automatically.
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
Started this account to share what I'm building at @team_qanda
I've been watching an explosion of AI workflows that help with dev, design, and planning. They're great for building something new from scratch — spin up a product, ship it, test it.
But I kept hitting the same wall: when multiple people need to work together, with existing company infra and institutional knowledge, producing output that satisfies everyone — these workflows fall short.
So I've been focused on building a harness that lets engineers, SREs, designers, PMs, marketers, and managers all produce fast, consistent output through AI workflows — grounded in the org's actual context.
Will be sharing my thinking and building process here. Open to networking with anyone working on similar problems or just curious about enterprise AI workflows.
Let's connect 🤝