Diffusion (stochastic SDE sampler): erratic Brownian trajectories zigzagging through noise.
Flow Matching (deterministic ODE integrator): clean, straight-line paths to the data modes.
Same start, radically different dynamics.
Well, that is what my previous two books are all about: Book 1 about low-dim models in high-dim spaces: https://t.co/4XEBJY5FEv and Book 2 about deep representations: https://t.co/ihPBCkI3x5 BTW, Version 2.0 of Book 2 is coming out this weekend, with significant updates!
Hugging Face has released a 214-page
MASTERCLASS on how to train LLMs
> it’s called The Smol Training Playbook
> and if want to learn how to train LLMs,
> this GIFT is for you
> this training bible walks you through the ENTIRE pipeline
> covers every concept that matters from why you train,
> to what you train, to how you actually pull it off
> from pre-training, to mid-training, to post-training
> it turns vague buzzwords into step-by-step decisions
> architecture, tokenization, data strategy, and infra
> highlights the real-world gotchas
> instabilities, scaling headaches, debugging nightmares
> distills lessons from building actual
> state-of-the-art LLMs, not just toy models
how modern transformer models are actually built
> tokenization: the secret foundation of every LLM
> tokenizer fundamentals
> vocabulary size
> byte pair encoding
> custom vs existing tokenizers
> all the modern attention mechanisms are here
> multi-head attention
> multi-query attention
> grouped-query attention
> multi-latent attention
> every positional encoding trick in the book
> absolute position embedding
> rotary position embedding
> yaRN (yet another rotary network)
> ablate-by-frequency positional encoding
> no position embedding
> randomized no position embedding
> stability hacks that actually work
> z-loss regularization
> query-key normalization
> removing weight decay from embedding layers
> sparse scaling, handled
> mixture-of-experts scaling
> activation ratio tuning
> choosing the right granularity
> sharing experts between layers
> load balancing across experts
> long-context handling via ssm
> hybrid models: transformer plus state space models
data curation = most of your real model quality
> data curation is the main driver of your model’s actual quality
> architecture alone won’t save you
> building the right data mixture is an art,
> not just dumping in more web scrapes
> curriculum learning, adaptive mixes, ablate everything
> you need curriculum learning:
> design data mixes hat evolve as training progresses
> use adaptive mixtures that shift emphasis
> based on model stage and performance
> ablate everything: run experiments to systematically
> test how each data source or filter impacts results
> smollm3 data
> the smollm3 recipe: balanced english web data,
> broad multilingual sources, high-quality code, and diverse math datasets
> without the right data pipeline,
> even the best architecture will underperform
the training marathon
> do your preflight checklist or die
> check your infrastructure,
> validate your evaluation pipelines,
> set up logging, and configure alerts
> so you don’t miss silent failures
> scaling surprises are inevitable
> things will break at scale in ways they never did in testing
> vanishing throughput? that usually means
> you’ve got a hidden shape mismatch or
> batch dimension bug killing your GPU utilization
> sudden drops in throughput?
> check your software stack for inefficiencies,
> resource leaks, or bad dataloader code
> seeing noisy, spiky loss values?
> your data shuffling is probably broken,
> and the model is seeing repeated or ordered data
> performance worse than expected?
> look for subtle parallelism bugs
> tensor parallel, data parallel,
> or pipeline parallel gone rogue
> monitor like your GPUs depend on it (because they do)
> watch every metric, track utilization, spot anomalies fast
> mid-training is not autopilot
> swap in higher-quality data to improve learning,
> extend the context window if you want bigger inputs,
> and use multi-stage training curricula to maximize gains
> the difference between a good model and a failed run is
> almost always vigilance and relentless debugging during this marathon
post-training
> post-training is where your raw base model
> actually becomes a useful assistant
> always start with supervised fine-tuning (sft)
> use high-quality, well-structured chat data and
> pick a solid template for consistent turns
> sft gives you a stable, cost-effective baseline
> don’t skip it, even if you plan to go deeper
> next, optimize for user preferences
> direct preference optimization (dpo),
> or its variants like kernelized (kto),
> online (orpo), or adversarial (apo)
> these methods actually teach the model
> what “better” looks like beyond simple mimicry
> once you’ve got preference alignment,go on-policy:
> reinforcement learning from human feedback (rlhf)
> or on-policy distillation, which lets your model learn
> from real interactions or stronger models
> this is how you get reliability and sharper behaviors
> the post-training pipeline is where
> assistants are truly sculpted;
> skipping steps means leaving performance,
> safety, and steerability on the table
infra is the boss fight
> this is where most teams lose time,
> money, and sanity if they’re not careful
> inside every gpu
> you’ve got tensor cores and cuda cores for the heavy math,
> plus a memory hierarchy (registers, shared memory, hbm)
> that decides how fast you can feed data to the compute units
> outside the gpu, your interconnects matter
> pcie for gpu-to-cpu,
> nvlink for ultra-fast gpu-to-gpu within a node,
> infiniband or roce for communication between nodes,
> and gpudirect storage for feeding massive datasets
> straight from disk to gpu memory
> make your infra resilient:
> checkpoint your training constantly,
> because something will crash;
> monitor node health so you can kill or restart
> sick nodes before they poison your run
> scaling isn’t just “add more gpus”
> you have to pick and tune the right parallelism:
> data parallelism (dp), pipeline parallelism (pp), tensor parallelism (tp),
> or fully sharded data parallel (fsdp);
> the right combo can double your throughput,
> the wrong one can bottleneck you instantly
to recap
> always start with WHY
> define the core reason you’re training a model
> is it research, a custom production need, or to fill an open-source gap?
> spec what you need: architecture, model size, data mix, assistant type
> transformer or hybrid
> set your model size
> design the right data mixture
> decide what kind of assistant or
> use case you’re targeting
> build infra for the job, plan for chaos, pick your stability tricks
> build infrastructure that matches your goals
> choose the right GPUs
> set up reliable storage
> and plan for network bottlenecks
> expect failures, weird bugs,
> and sudden bottlenecks at scale
> select your stability tricks in advance:
> know which techniques you’ll use to fight loss spikes,
> unstable gradients, and hardware hiccups
closing notes
> the pace of LLM development is relentless,
> but the underlying principles never go out of style
> and this PDF covers what actually matters
> no matter how fast the field changes
> systematic experimentation is everything
> run controlled tests, change one variable at a time, and document every step
> sharp debugging instincts will save you
> more time (and compute budget) than any paper or library
> deep knowledge of both your software stack
> and your hardware is the ultimate unfair advantage;
> know your code, know your chips
> in the end, success comes from relentless curiosity,
> tight feedback loops, and a willingness to question everything
> even your own assumptions
if i had this two years ago, it would have saved me so much time
> if you’re building llms,
> read this before you burn gpu months
happy hacking
🏆 We are incredibly honored to announce that our paper, "Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free" has received the NeurIPS 2025 Best Paper Award!
A huge congratulations to our dedicated research team for pushing the boundaries of AI.
Read more: https://t.co/qu3ERa3pH5
Please check out paper #CoDA “Coordinated Diffusion Noise Optimization for Whole-Body Manipulation of Articulated Objects” at #NeurIPS2025! 🎉
(Big congrats and thanks to our amazing collaborators: @HuaijinPi (1st author), Zhi Cen, Taku Komura)
💡The paper tackles the challenge of full-body manipulation of articulated objects, generating long, physically plausible interaction sequences of a human body, both hands, and an object from an initial pose and a text instruction.
💡Its key idea is a framework that splits the body, left hand, and right hand into three diffusion models and jointly optimizes their input noise so that gradients from hand–object objectives flow through the kinematic chain and coordinate the whole body.
💡Using a unified Basis Point Set (BPS) representation to encode both object geometry and end-effector trajectories, CoDA enables precise hand–object contact and object pose control, achieves SOTA results on ARCTIC and GRAB, and supports capabilities like walking while manipulating and filling in full-body motion from hand-only data.
Btw, if you work on full-body humanoid control (either real-world robots or simulated characters), this can be a good skill learning source.
Please come meet Huaijin @HuaijinPi at our #NeurIPS2025 San Diego poster!
📍 Exhibit Hall C,D,E — #5207
🕚 Wed, Dec 3 | 11 a.m.–2 p.m. PST
Paper: https://t.co/KcAYJgxSjK
Project Page: https://t.co/z1Yt8zTOp8
Code: https://t.co/VewME6TA6M
#NeurIPS #NeurIPS2025 #motion #Animation #Robotics #Robot #AI #Deeplearning #GenerativeAI #AIGC
I just read this paper called "Chain-of-Visual-Thought (COVT)" and it basically teaches VLMs to see and think at the same time not in text, but in continuous visual tokens.
Here’s the wild part:
Instead of forcing models to reason through words (which destroys all the fine-grained visual detail), COVT makes the model generate tiny visual latents mid-thought segmentation cues, depth cues, edges, DINO features then chain them together as its “visual reasoning process.”
Think of it like giving the model a miniature visual scratchpad so it can actually perceive geometry, spatial layout, object boundaries, and depth before answering.
And the results are stupid impressive:
• +14% jump on depth reasoning
• +5.5% improvement on CV-Bench
• Massive gains on HRBench + MMVP
• Works across Qwen2.5-VL, LLaVA, and more
• Visual tokens are interpretable you can literally decode the model’s visual thoughts (masks, edges, depth maps) as it reasons
The craziest discovery?
Text-only chain-of-thought actually hurts visual performance.
COVT fixes that by grounding reasoning in the visual world instead of making the model “verbalize” geometric relationships in clunky text.
It predicts a few continuous tokens, and those tokens reconstruct dense visual signals through segmentation, depth, and edge decoders. The model learns to think visually while staying efficient.
This unlocks:
- Accurate counting
- Reliable spatial understanding
- Real 3D awareness
- Better depth ordering
- Fine-grained perception
- Far fewer hallucinated visual claims
All inside the model.
A tiny chain of visual thoughts. Huge jump in perception.
Multimodal reasoning is about to get a whole lot more grounded.
Paper: Chain-of-Visual-Thought: Teaching VLMs to See and Think Better with Continuous Visual Tokens
This paper from Chinese Labs, explains how to train language model agents that solve tasks step by step using reinforcement learning.
These trained agents answer hard multi hop questions much better than simple one shot retrieval systems.
Ordinary language models usually read the question once, produce an answer, and do not interact with tools again.
Here the agent keeps a full history of the conversation plus every tool result, and uses that as its state.
Its actions are still just tokens, but some token spans are treated as commands that call tools and return feedback.
On top of this setup, the authors build Agent R1, a framework that connects models, tools, and interactive environments.
Tool modules actually run things like search or code, while the ToolEnv module updates the dialogue, computes rewards, and decides when to stop.
During training, each full interaction becomes a trajectory, an action mask marks exactly which tokens came from the agent, and special scores judge how good each decision was.
----
Paper – arxiv. org/abs/2511.14460
Paper Title: "Agent-R1: Training Powerful LLM Agents with End-to-End Reinforcement Learning"
This broke my brain.
A team at Sea AI Lab just discovered that most of the chaos in reinforcement learning training collapse, unstable gradients, inference drift wasn’t caused by the algorithms at all.
It was caused by numerical precision.
The default BF16 format, used across nearly every modern AI lab, introduces subtle rounding errors that make models behave differently during training and inference.
Their solution?
Not a new optimizer.
Not a new loss function.
Just switching to FP16.
One line of code and everything stabilized.
✅ No training collapse
✅ Consistent convergence
✅ +5–10% better results
✅ No extra tuning needed
They titled it “Defeating the Training–Inference Mismatch via FP16,”
but it could’ve just been called:
“How to fix RL by flipping a single bit.”
Paper: arxiv. org/abs/2510.26788
🧵 LoRA vs full fine-tuning: same performance ≠ same solution.
Our NeurIPS ‘25 paper 🎉shows that LoRA and full fine-tuning, even when equally well fit, learn structurally different solutions and that LoRA forgets less and can be made even better (lesser forgetting) by a simple intervention!
Read on for behavioral differences (forgetting, continual learning) and other analysis!
Paper: https://t.co/XXyQn7uYmZ
(1/7)
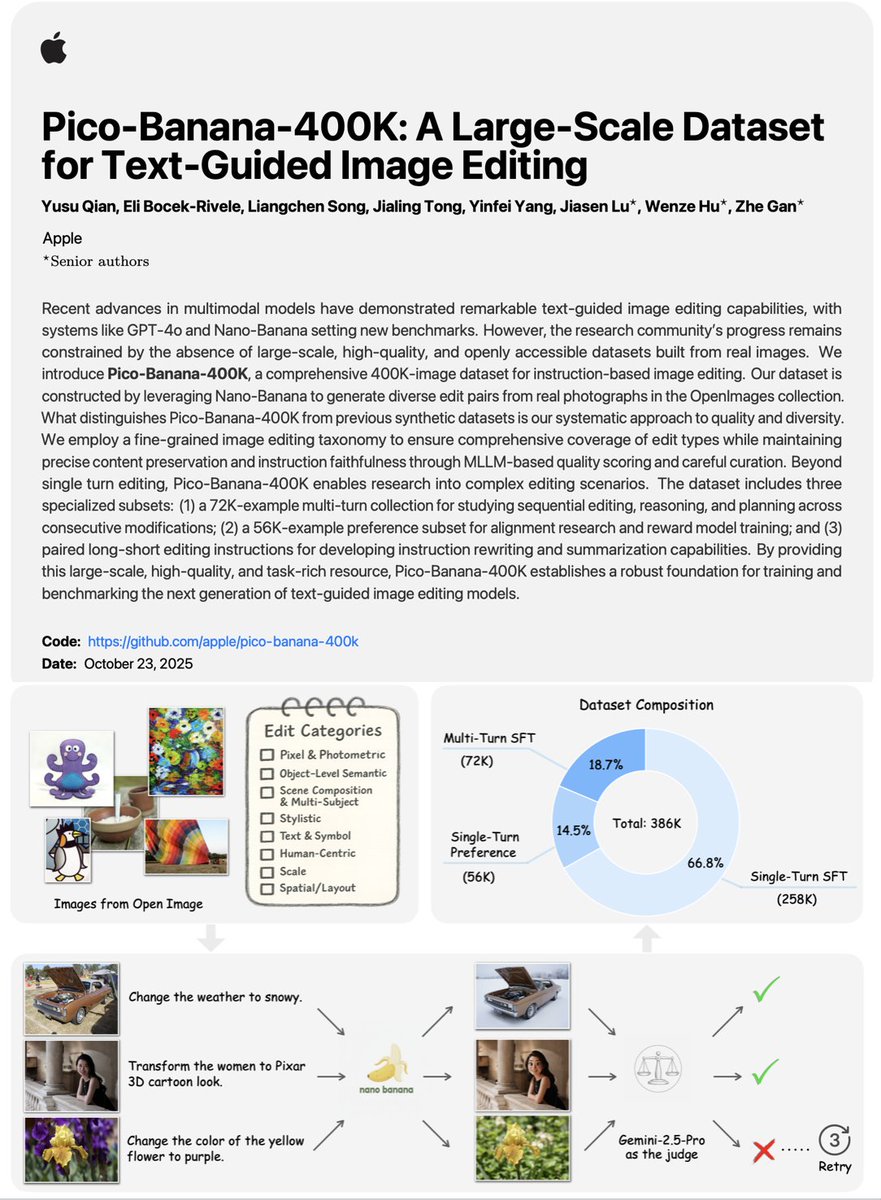
🔥 Holy shit... Apple just did something nobody saw coming
They just dropped Pico-Banana-400K a 400,000-image dataset for text-guided image editing that might redefine multimodal training itself.
Here’s the wild part:
Unlike most “open” datasets that rely on synthetic generations, this one is built entirely from real photos. Apple used their internal Nano-Banana model to generate edits, then ran everything through Gemini 2.5 Pro as an automated visual judge for quality assurance. Every image got scored on instruction compliance, realism, and preservation and only the top-tier results made it in.
It’s not just a static dataset either.
It includes:
• 72K multi-turn sequences for complex editing chains
• 56K preference pairs (success vs fail) for alignment and reward modeling
• Dual instructions both long, training-style prompts and short, human-style edits
You can literally train models to add a new object, change lighting to golden hour, Pixar-ify a face, or swap entire backgrounds and they’ll learn from real-world examples, not synthetic noise.
The kicker? It’s completely open-source under Apple’s research license.
They just gave every lab the data foundation to build next-gen editing AIs.
Everyone’s been talking about reasoning models…
but Apple just quietly dropped the ImageNet of visual editing.
👉 github. com/apple/pico-banana-400k
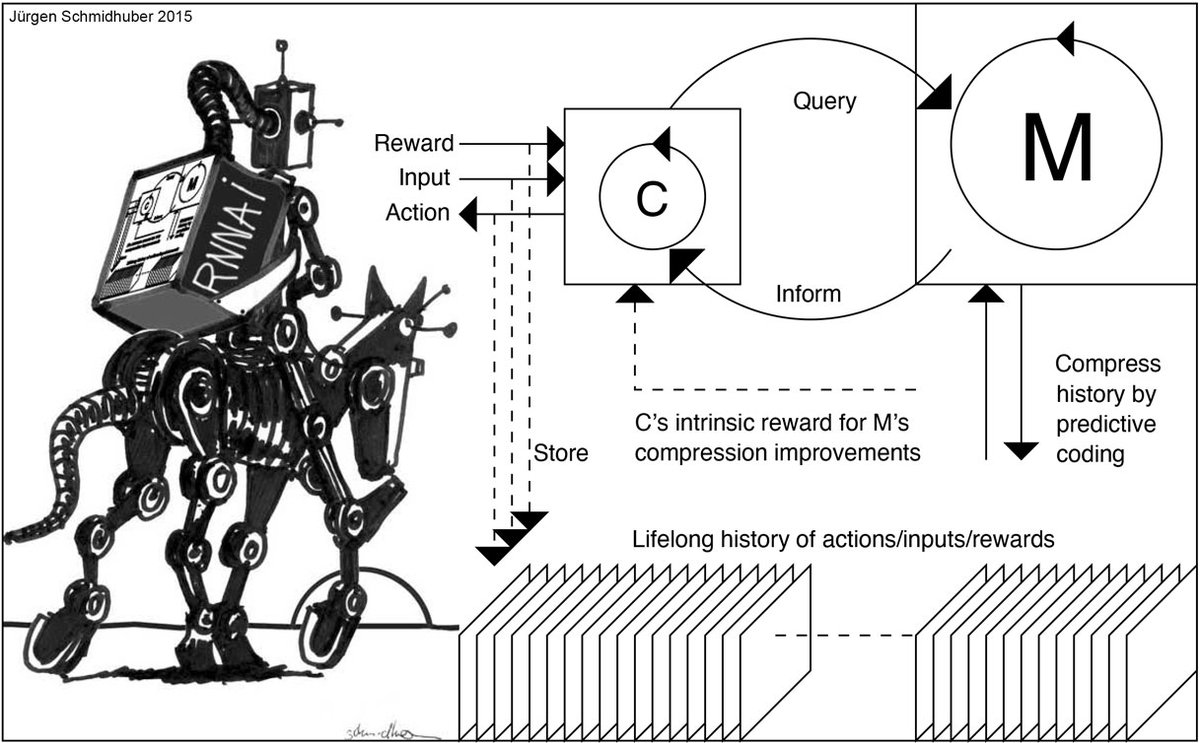
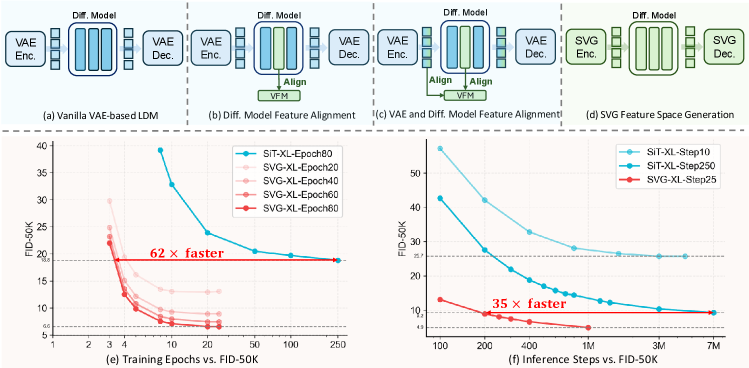
A new Latent Diffusion Model without VAE from Kuaishou Technology is here!
Introducing SVG: it ditches the VAE for self-supervised representations, enabling 62x faster training & 35x faster inference, all while boosting generative quality.
🎁🎁 We release Pico-Banana-400K, a large-scale, high-quality image editing dataset distilled from Nana-Banana across 35 editing types.
🔗 Data link: https://t.co/PF978SRBXu
🔗Paper link: https://t.co/E1RlcxtII8
It includes 258K single-turn image editing data, 72K multi-turn image editing data, and 56K preference pairs.
🤔 Btw, why Pico? It is simply because it represents the next smaller scale after Nano.
Led by @sueqian111, together with @yinfeiy@jiasenlu@wenzehu etc.
Holy shit... Tencent researchers just killed fine-tuning AND reinforcement learning in one shot 😳
They call it Training-Free GRPO (Group Relative Policy Optimization).
Instead of updating weights, the model literally learns from 'its own experiences' like an evolving memory that refines how it thinks without ever touching parameters.
Here’s what’s wild:
- No fine-tuning. No gradients.
- Uses only 100 examples.
- Outperforms $10,000+ RL setups.
- Total cost? $18.
It introspects its own rollouts, extracts what worked, and stores that as “semantic advantage” a natural language form of reinforcement.
LLMs are basically teaching themselves 'how' to think, not just 'what' to output.
This could make traditional RL and fine-tuning obsolete.
We’re entering the “training-free” era of AI optimization.
New @nvidia paper shows how to make text to image models render high resolution images far faster without losing quality.
53x faster 4K on H100, 3.5 seconds on a 5090 with quantization for 138x total speedup.
It speeds up by moving generation into a smaller hidden image space.
It means the model does not create the full detailed image step by step.
Instead, it first works inside a smaller hidden version of the image that has fewer pixels.
Because it processes this smaller space, there are fewer data chunks (called tokens) to handle.
Most models use 8x compression, this uses 32x or 64x, so far fewer tokens.
A direct swap is unstable because old and new latent features do not match.
They add a quick embedding alignment step that trains the patch embedder and output head.
Then they fine tune small LoRA adapters so the main weights stay mostly intact.
For FLUX guidance distilled weights, they fix the training target using outputs with and without text.
----
Paper – arxiv. org/abs/2509.25180
Paper Title: "DC-Gen: Post-Training Diffusion Acceleration with Deeply Compressed Latent Space"